
OpenAI Tripled Its Web Crawl: What the 7-Billion Log File Study Means for Your SEO
A Botify/Nectiv analysis of 7 billion server log events reveals OAI-SearchBot surged 3.5× after GPT-5, ChatGPT-User dropped 28%, and traditional top-10 rankings now predict only 38% of AI citations. Here's what to do about it.

OpenAI Tripled Its Web Crawl: What the 7-Billion Log File Study Means for Your SEO
TL;DR: Botify and Nectiv published the largest-ever log file study of OpenAI's crawlers — 7 billion+ events from November 2024 to March 2026. OAI-SearchBot activity tripled after GPT-5 launched in August 2025. Meanwhile, ChatGPT-User events dropped 28%, signalling either user decline or a maturing index that no longer needs real-time fetches. Either way, the rules for LLM visibility just changed.
What you'll learn:
- What the 3.5x OAI-SearchBot surge means for your robots.txt and crawl budget
- Why ChatGPT is now citing fewer domains per response — and how to stay in the pool
- A concrete LLM visibility checklist built from the data, not guesswork
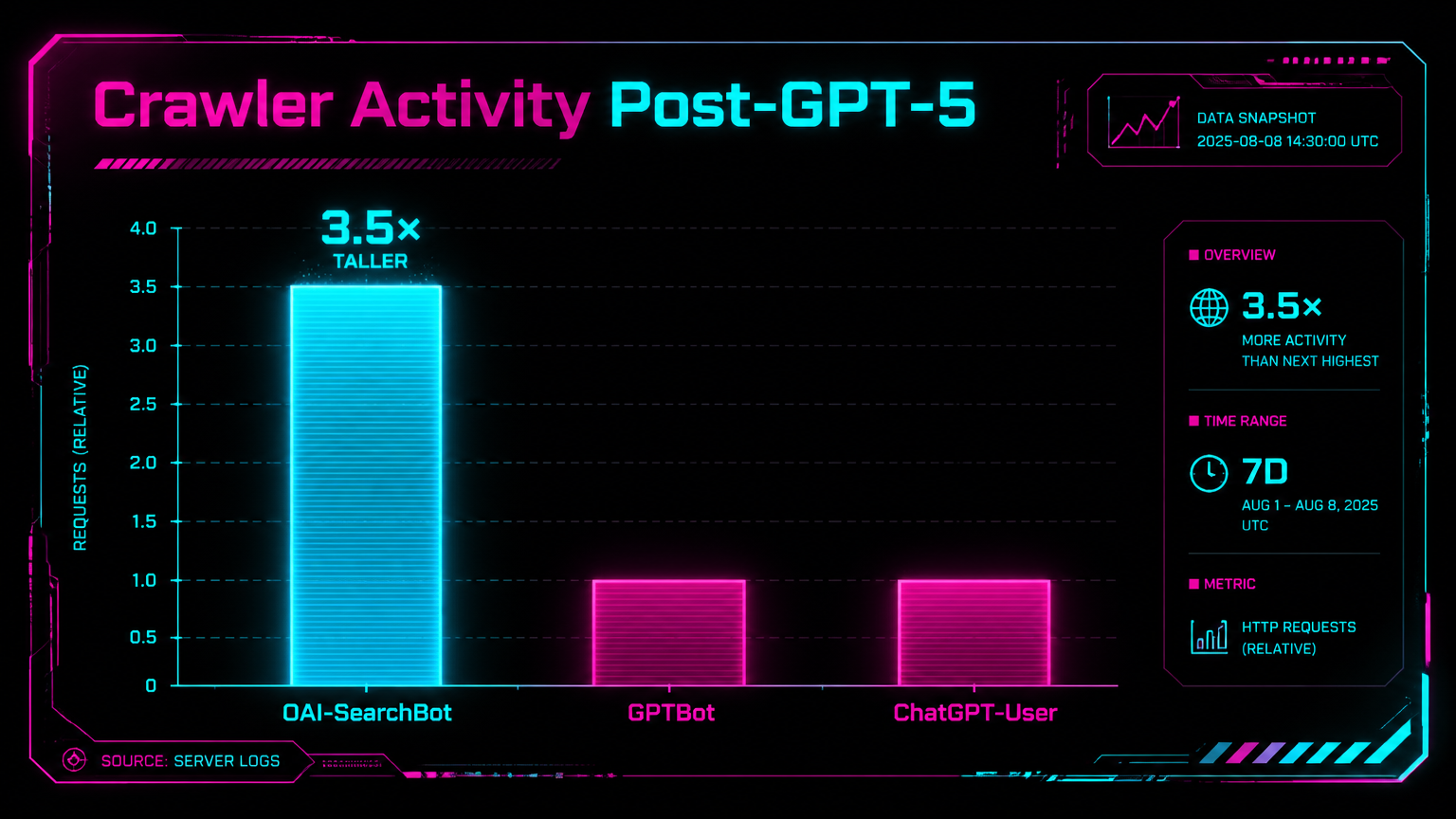
Here's a number that should stop you mid-scroll: OpenAI's automated web crawlers tripled in activity between August 2025 and March 2026. Not grew. Not expanded meaningfully. Tripled. And most SEO teams have zero log file monitoring set up for OpenAI bots, which means they've been completely blind to this shift. (Source: Botify/Nectiv, April 23, 2026)
I've been watching the AI crawl story develop for about 18 months. Last summer, when Chris Long published a LinkedIn post about analysing OpenAI crawl activity via log files, the reaction was disproportionate , hundreds of SEOs sharing it like it was breaking news. Which, in fairness, it was. Nobody was measuring this stuff. Now, Long partnered with Botify , the enterprise SEO platform that processes log files for Fortune 500 clients across retail, publishing, healthcare, travel, and more , and they ran the numbers at genuine scale. The dataset: 250+ billion total log files, with ~7 billion filtered to OpenAI bot activity spanning November 2024 through March 14, 2026.
The results are the most data-grounded picture of how ChatGPT actually reads the web that we've ever had. And several findings are frankly surprising. Let me walk you through the key ones, and then tell you what to do about them.
The Three OpenAI Crawlers , And Why You Need to Track Each Separately
Before diving into the data, you need to understand that "OpenAI's crawler" isn't one thing. There are three distinct bots, each with a different job:
| Bot Name | Purpose | SEO Relevance |
|---|---|---|
| ChatGPT-User | User-initiated action , when someone tells ChatGPT to visit or interact with a page | Proxy for actual platform engagement with your content |
| GPTBot | General training crawler , collects data to improve model foundational knowledge | Affects future model training; less direct citation impact today |
| OAI-SearchBot | Real-time web search crawler , fires when ChatGPT needs fresh web results for a query | Most directly tied to citation and visibility in ChatGPT search answers |
Most SEOs conflate these. Don't. Their trends have moved in completely different directions since August 2025, which tells completely different stories about what OpenAI is doing strategically. (Source: Botify/Nectiv study)
GPT-5 Was the Inflection Point No One Clocked in Real Time

The Botify data shows one unmistakable pattern: practically overnight after GPT-5 launched in August 2025, all three OpenAI crawlers registered rapid increases. When you isolate just the automated crawlers (OAI-SearchBot + GPTBot), the before/after difference is enormous.
Why did GPT-5 trigger this? SEO analyst Dan Petrovic had theorized at the time of GPT-5's release that the new model was designed to be intelligent rather than knowledgeable , meaning it leans on the live web as its knowledge base rather than relying solely on static training data. The Botify data confirms that thesis was right. GPT-5 changed how OpenAI's architecture retrieves and generates responses. (Source: Botify/Nectiv study)
Search Now Outpaces Training , What That Ratio Actually Means
Here's the one finding from the study that I keep coming back to. The researchers measured the ratio of OAI-SearchBot to GPTBot activity , , how much time is OpenAI spending searching the web in real time versus crawling for training data.
| Period | OAI-SearchBot / GPTBot Ratio | What It Means |
|---|---|---|
| Before GPT-5 (pre-Aug 2025) | 0.95 | Slightly more training than searching |
| After GPT-5 (Aug 2025–Mar 2026) | 1.14 | More searching than training , a structural flip |
This is a structural shift, not noise. OpenAI has crossed the threshold where live web retrieval now accounts for more crawler activity than model training. For SEO practitioners, this is good news: it means your fresh content has a real path to being cited in ChatGPT answers , not just via historical training data, but via active search retrieval. The window isn't closed.
But there's a meaningful industry-level wrinkle here. That aggregate ratio hides stark variation by vertical:
| Industry | OAI-SearchBot vs GPTBot Lean | Implication |
|---|---|---|
| Media & Publishing | +256% toward Search | Fresh content and recency are vital |
| Software / Internet | Leans toward Search | Documentation freshness matters |
| Healthcare | −50% (Training leads) | Model relies more on ingested knowledge; authority signals dominate |
| Retail & E-commerce | −33% (Training leads) | Product knowledge baked into the model; focus on training inclusion |
If you're a media publisher and wondering why your freshness strategy matters: this is why. ChatGPT is using OAI-SearchBot at a 256% higher rate than training crawlers on your type of content. Your published-yesterday article can get into ChatGPT answers quickly. If you're in healthcare, the calculus is different , the model already "knows" your field and searches less. Authority and training inclusion are your lever. (Source: Botify/Nectiv)
Key takeaway
Know your vertical's crawler lean before setting your LLM visibility strategy. A media brand and a pharma brand face different optimization problems inside OpenAI's system.
The ChatGPT-User Drop: User Loss or Better Index?
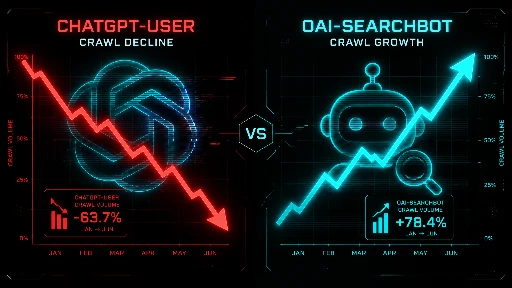
The most genuinely ambiguous finding in the whole study is the ChatGPT-User decline. Since December 2025, user-initiated events dropped a staggering 28% compared to the equivalent prior period. That's not a rounding error , it's a trend line.
Two explanations exist, and I'll give you both straight rather than hedging:
1ChatGPT Is Losing Users
SimilarWeb data shows ChatGPT's traffic share within the AI platform category fell from 86.7% in January 2025 to 64.5% in January 2026 , a 22-point collapse in 12 months. SISTRIX separately found usage plateauing around late 2025 then declining. If fewer people are using ChatGPT, fewer ChatGPT-User events follow logically.
2OpenAI's Index Is Maturing
Botify's team offers a structural alternative: OAI-SearchBot may be crawling so aggressively that OpenAI now holds a fresh cached version of most pages. So when a user interacts, the system pulls from cache rather than fetching live , exactly how Gemini uses Google's pre-built index instead of crawling on demand. Under this reading, the ChatGPT-User drop signals infrastructure progress, not platform decline.
My read: both are probably true simultaneously, in different proportions for different user segments. What matters for SEO practitioners is that tracking ChatGPT-User events as a measure of platform engagement is now unreliable. You might see your ChatGPT-User volume drop and panic , but it could just mean OpenAI cached your page and no longer needs to fetch it live. That's actually fine. Check citation data separately.
"It's possible that the reason we're seeing less ChatGPT-User traffic is actually because OAI-SearchBot is crawling more. If OpenAI has assembled a sufficiently fresh HTML web index, it doesn't need to fetch pages in real time as often."
Botify Engineering Team, via Chris Long's Analysis (April 2026)
ChatGPT Is Now Citing Fewer Sites Per Response
Parallel to the Botify crawl data, French SEO consultancy Resoneo ran a separate analysis that compounds the picture. They tracked 400 prompts daily for 14 weeks using Meteoria, their AI visibility tracking platform , producing 27,000 comparable responses. Their finding is uncomfortable for anyone banking on ChatGPT citation volume:
That's roughly a 20% reduction in citation breadth after GPT-5.3 Instant became the default experience in early March 2026. Fewer domains compete for the same answer space , but the sites that do get cited take up more of each response. Think of it like SEO position compression: the rich get richer. (Source: Resoneo/Meteoria analysis, via Search Engine Journal)
Jérôme Salomon at Oncrawl independently confirmed the pattern via server log analysis. Crawl volume settled lower post-transition. Some pages stopped being crawled entirely. Those that are still visited see lower frequency.
OpenAI Is Building Its Own Web Index , and That Changes Everything
The Botify data lands in the context of a larger strategic shift: OpenAI is no longer depending on Bing as its sole data source. It's building a proprietary web index. SEO Sherpa's Jenny Abouobaia put it well in an April 2026 analysis: "By building its own index, OpenAI is stepping out of dependency and into sovereignty."
What does that actually mean? A web index isn't just a database of URLs. It's a worldview , it determines what content exists, how it's categorized, how it's retrieved, and how relevance is defined. For decades, Google's index defined all three of those for the commercial web. Now there are two indexes that matter independently.
This changes the game in a specific way: optimizing for Google no longer automatically optimizes for ChatGPT. The two systems have different freshness models, different trust signals, different crawl patterns. A site with strong Google rankings but poor crawlability by OAI-SearchBot can be invisible in ChatGPT answers , and you won't see that in Search Console.
The Botify/Nectiv research also documented that OpenAI's crawlers and Google's Googlebot are exhibiting increasingly divergent behavior on the same pages. This isn't theoretical , it's measurable in log files right now. (Source: SEO Sherpa / Botify)
LLM Perception Drift: The New Metric You Need to Track

Jordan Koene at Previsible coined a concept in late 2025 that's becoming more relevant by the week: LLM perception drift , the month-over-month change in how AI models reference and position brands in their outputs, even when nothing visible changes in the market itself. Using data from Evertune, which tracks brand visibility in model outputs, they tracked the project management space from September to October 2025.
The swings were alarming:
| Brand | AI Brand Score Change (Sep → Oct 2025) |
|---|---|
| Slack | −8.10 |
| Trello | −5.59 |
| Monday.com | −0.78 |
| Atlassian | +5.50 |
| Deloitte | +5.00 |
| +3.62 | |
| Microsoft | +2.08 |
Atlassian's +5.50 gain happened not because they published more content, but because they have strong documentation, cross-product integrations, and high contextual density that drives richer model associations. Multi-product ecosystems gain attention more reliably. This is the entity-based SEO lesson playing out faster and with more volatility than anything we've seen in traditional search. (Source: Jordan Koene / Previsible, Search Engine Land)
By 2026, AI brand signal stability sits next to share of voice and keyword rankings as a core visibility metric. If you're not measuring it, you're flying blind on a third of your discovery surface.
What OAI-SearchBot Actually Looks For (And What Blocks It)
I've watched clients block OAI-SearchBot accidentally through over-aggressive robots.txt rules , usually inherited from some 2019 template that blocked everything except Googlebot. Don't be those clients. Here's what the data and practitioner experience tells us about what actually matters for OAI-SearchBot visibility.
Critical (do this week)
- Check
robots.txt, explicitly allow OAI-SearchBot:User-agent: OAI-SearchBot/Allow: / - Submit sitemap to Bing Webmaster Tools , ChatGPT's search still uses Bing index as primary source
- Verify GPTBot is not blocked if you want training data inclusion
- Add log file monitoring for all three OpenAI bot user agents (ChatGPT-User, GPTBot, OAI-SearchBot)
Important (this month)
- Structure content with direct question-answering H2/H3 headings , inverted pyramid, answer first
- Implement JSON-LD schema: FAQ Schema, Article Schema, Author Schema, Organization Schema
- Build topical authority clusters , ChatGPT favors full coverage of a topic over isolated pages
- Invest in brand mentions across the web: news articles, industry pubs, forums, GitHub , OpenAI's model associates brand presence with trustworthiness
Strategic (next quarter)
- Start tracking AI brand signal stability using tools like Evertune, Waikay, or Peec AI
- Measure citation surface (unique domains appearing in ChatGPT answers for your target topics)
- Audit content freshness cadence , especially if you're in media/publishing where OAI-SearchBot leads
- Map referring domains to citation threshold: SE Ranking data shows 32,000 referring domains as a key threshold for ChatGPT citation likelihood
Three Things SEOs Are Getting Wrong Right Now

I'd rather be direct about the bad takes circulating than hedge. Here's what I'm seeing people do wrong in response to this data:
1. Treating "LLM SEO" as a separate discipline with separate teams. It's not. Crawlability, authority, content structure, and E-E-A-T are the same signals Google cares about. The difference is the retrieval mechanism, not the foundation. If your technical SEO is broken for Google, it's almost certainly broken for OpenAI too. Fix the foundation first.
2. Obsessing over ChatGPT-User referral traffic as a vanity metric. As the Botify data shows, a decline in ChatGPT-User events might mean OpenAI built a better index , not that you're losing. Measure citation presence (are you being mentioned in AI responses to relevant queries?) rather than raw referral traffic.
3. Ignoring vertical-specific crawl patterns. Healthcare and retail sites see GPTBot leading, not OAI-SearchBot. If you're in those verticals and only thinking about real-time search optimization, you're solving the wrong problem. Training data inclusion , getting GPTBot to crawl and index your authoritative content , is your use point.
How We Got Here: A Timeline of OpenAI's Crawl Expansion
Bottom Line

The Botify/Nectiv study is the most important dataset published for SEO in 2026 so far. Full stop. It confirms several things we suspected and contradicts a few assumptions we were running on. Here's my honest synthesis:
OpenAI is building a serious, independent web index. It tripled crawler activity in under a year. It now crawls more for search than for training. The citation surface is narrowing , fewer domains per response , which means the stakes for being included are higher, not lower. And the signal quality of ChatGPT-User traffic in your analytics is degrading as a metric; you need to measure citation presence directly.
The good news: the core of good SEO still works. Crawlability, authority, clean structure, E-E-A-T , these are what OAI-SearchBot responds to. You don't need a new discipline. You need to extend what you're already (hopefully) doing to cover OpenAI's infrastructure explicitly, with log file monitoring, Bing Webmaster Tools access, and robots.txt hygiene as the starting points.
The SEO practitioners who add log file monitoring for OAI-SearchBot, GPTBot, and ChatGPT-User to their standard tech SEO audits in the next 90 days will have a material data advantage over those who don't. That advantage compounds as the data accumulates. Start now.
FAQ
How do I check if OAI-SearchBot is crawling my site?
Access your server logs and filter for the user agent string OAI-SearchBot. Enterprise platforms like Botify, Oncrawl, or Screaming Frog Log File Analyser can parse these automatically. If you don't have log file access, ask your hosting provider , most shared and managed hosting services can export access logs on request. Look at monthly volumes and compare against the August 2025 baseline to see if the tripling trend is reflected in your own data.
Does blocking GPTBot hurt my ChatGPT search visibility?
GPTBot is the training crawler, not the search crawler , so blocking it doesn't directly prevent OAI-SearchBot from citing your content in real-time answers. However, blocking GPTBot may affect how future model versions perceive and reference your content in their foundational knowledge. If you don't have a specific legal or content reason to block it, don't. Many publishers blocked it reactively in 2023–2024 without understanding this distinction.
Why did my ChatGPT referral traffic drop in March 2026?
Most likely: GPT-5.3 Instant became the default ChatGPT experience in early March 2026. Resoneo's analysis of 27,000 responses found a 20% reduction in domains cited per response after this transition. Fewer sites share the citation surface in each answer. Your traffic drop is likely structural to the model version change, not specific to your content. Check your citation presence (are you still being mentioned in AI responses?) rather than just referral sessions.
Is ChatGPT losing users or just indexing better?
Probably both, in different proportions. SimilarWeb data shows ChatGPT's AI platform traffic share fell from 86.7% to 64.5% between January 2025 and January 2026. That's real user loss to competitors like Gemini, Claude, and Perplexity. At the same time, the Botify team's hypothesis , that a more full index reduces the need for real-time ChatGPT-User fetches , is plausible and consistent with the data. Don't bet the farm on either explanation alone.
What's the minimum referring domain count to get cited by ChatGPT?
SE Ranking's analysis of 129,000 domains identified a threshold effect at approximately 32,000 referring domains, above which ChatGPT citation likelihood increases materially. Below that threshold, citation is statistically unlikely regardless of content quality. This isn't a hard cutoff , other factors (topical authority, content structure, schema) matter too , but it indicates that link acquisition for AI search visibility is not optional for competitive niches.
How is ChatGPT's crawling different from Googlebot?
Several ways. First, ChatGPT uses three distinct bots with different purposes (ChatGPT-User, GPTBot, OAI-SearchBot) vs. Google's more unified Googlebot. Second, the search/training ratio distinction means OpenAI's system makes a real-time freshness decision that Googlebot doesn't make explicitly. Third, the citation mechanism is different , Google ranks pages on a SERP; ChatGPT synthesizes an answer from multiple retrieved pages and cites sources inline. Being crawlable and being cited are related but different problems.
Should I tune for ChatGPT separately from Google?
Not as a completely separate discipline , the foundations are the same. But there are specific extensions: Bing Webmaster Tools submission, explicit OAI-SearchBot allowance in robots.txt, question-based H2 structure for direct answer retrieval, schema markup for context, and log file monitoring for OpenAI bots. Think of it as the same technical SEO foundation with a 15-point checklist of AI-specific extensions on top, not a parallel practice.
What tools can I use to track my brand's AI search citation presence?
Several platforms have emerged in 2025–2026: Evertune and Waikay (AI brand score tracking and share of voice), Peec AI (citation monitoring across ChatGPT, Perplexity, Gemini), Meteoria (used in the Resoneo study), and SE Ranking's AI Visibility module. Semrush and Ahrefs are also adding AI visibility features. For budget-conscious teams, manually querying representative prompts daily and tracking citation presence in a spreadsheet is better than nothing while proper tooling rolls out.
About the Author
