
Cloudflare's Agent Readiness Score - Only 4% of Sites Are Prepared for AI Agents
Cloudflare Radar analyzed 200,000 domains and found only 4% declare AI preferences. Plus: AI Training Redirects enforce canonicals for GPTBot and ClaudeBot, and ChatGPT's Reddit citation blind spot explained.

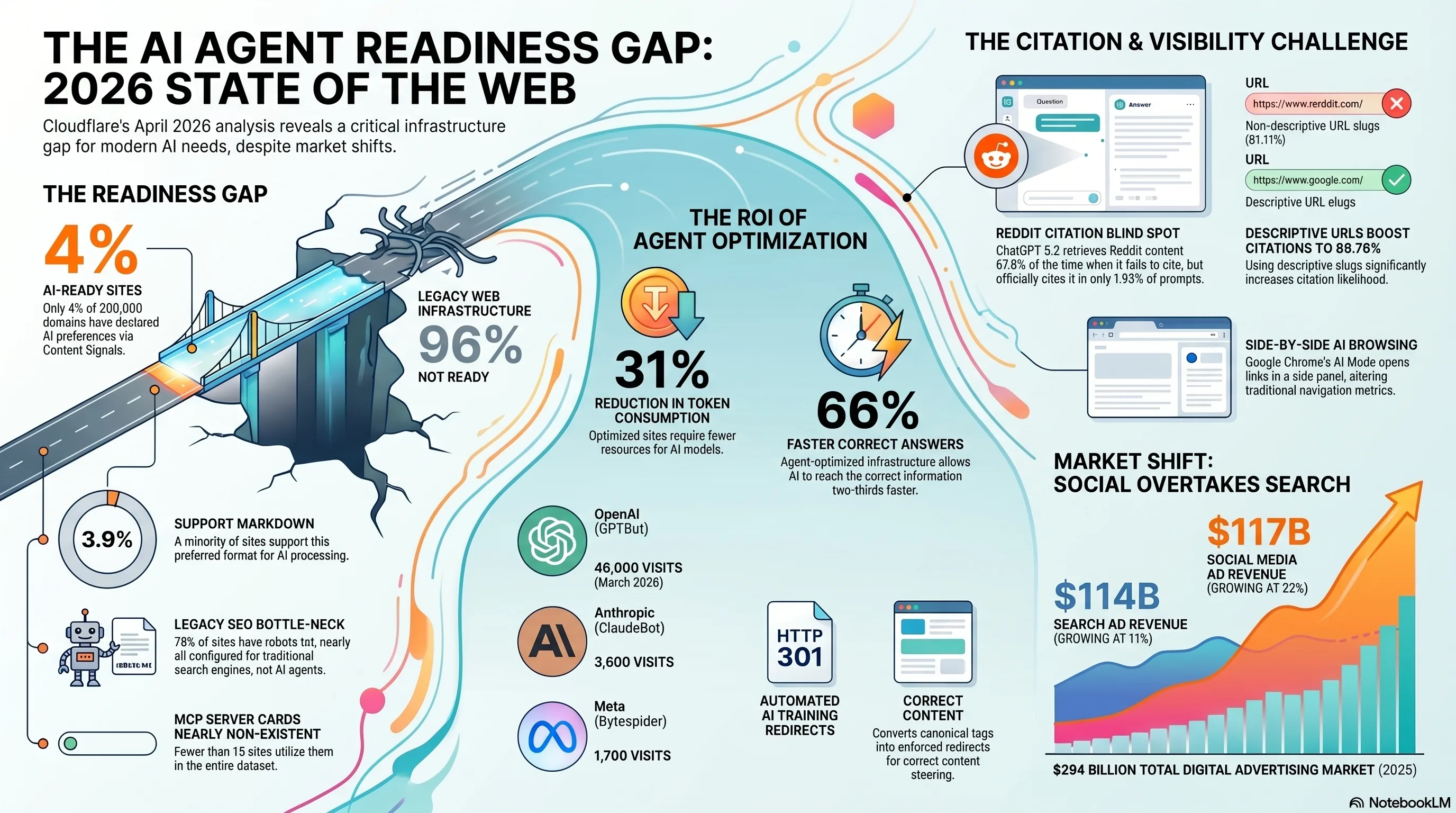
Cloudflare just published the first large-scale audit of how prepared the web is for AI agents, and the answer is: barely at all. Across 200,000 domains analyzed by Cloudflare Radar, only 4% have declared any AI preferences. MCP Server Cards exist on fewer than 15 sites. Meanwhile, Cloudflare's new AI Training Redirects feature converts canonical tags into hard 301 redirects for AI crawlers like GPTBot and ClaudeBot, a fundamental shift in how publishers can enforce content hierarchy for LLM training pipelines. This comes alongside new data on ChatGPT's Reddit citation blind spot and the historic moment when social media ad spending overtook search.
1. Cloudflare Agent Readiness Score, Only 4% of 200K Sites Declare AI Preferences
Cloudflare Radar scanned 200,000 domains to produce the first Agent Readiness Score, a composite metric measuring how prepared websites are for AI agent interaction. The results are sobering for anyone betting the agentic web is right around the corner. The score evaluates four layers of AI readiness: whether a site's `robots.txt` addresses AI crawlers, whether it exposes `llms.txt` or `llms-full.txt` files for LLM-friendly content summaries, whether it declares structured AI preferences, and whether it supports emerging agent protocols like MCP Server Cards.
The four readiness layers
Layer 1: robots.txt (78% have one, almost none address AI). The vast majority of websites have a `robots.txt` file, but these were written for Googlebot and Bingbot. They don't include directives for GPTBot, ClaudeBot, Bytespider, or other AI training crawlers. Having a `robots.txt` is necessary but not enough, without AI-specific directives, you have no declared position on AI crawling. None. Layer 2: llms.txt adoption (near zero). The `llms.txt` standard, proposed as the AI equivalent of `robots.txt`, provides a machine-readable summary of a site's content tuned for LLM consumption. Adoption is functionally zero outside of developer tool documentation sites. The companion `llms-full.txt`, which provides complete content access, is even rarer. Layer 3: AI preference declarations (4%). Only 4% of the 200K domains have any explicit declaration about how AI systems should interact with their content. This includes AI-specific `robots.txt` directives, meta tags, HTTP headers, or structured data indicating AI access policies. The other 96% are operating in an unregulated default state, AI crawlers decide for themselves. Layer 4: MCP Server Cards (fewer than 15 sites). The Model Context Protocol's Server Card specification, which enables sites to declare their capabilities, API endpoints, and data schemas to AI agents, exists on fewer than 15 websites globally. This is the layer that would enable true agentic interaction (booking, purchasing, querying) rather than just crawling and reading. It barely exists yet.What this means in practice: The agentic web is being built on a foundation where 96% of sites haven't declared any AI preferences. AI agents are making inferences about site policies, capabilities, and content access based on signals designed for a different era. The gap between the promise of agentic commerce and the reality of web readiness is enormous.
The readiness gap by industry The 4% average masks significant variation across sectors:
| Sector | AI declaration rate | Primary mechanism |
|---|---|---|
| Developer tools / documentation | ~18% | llms.txt + AI robots.txt directives |
| News / media publishers | ~12% | AI crawler blocks in robots.txt |
| E-commerce | ~3% | Mostly legacy robots.txt only |
| Small business / local | <1% | No AI-specific configuration |
| Enterprise SaaS | ~8% | Mixed, some llms.txt, some blocks |
Key takeaway
The agentic web requires publishers to actively declare their AI policies and capabilities. 96% haven't started. The first movers who set up llms.txt, AI-specific robots.txt directives, and structured capability declarations will have a compounding advantage as AI agents increasingly route traffic based on these signals.
2. Agent-Optimized Sites: 31% Fewer Tokens, 66% Faster Answers
Cloudflare's analysis didn't stop at measuring readiness, it also quantified the performance difference between agent-optimized and non-optimized sites when AI agents consume their content.Why this matters for citation and visibility
The retrieval accuracy improvement, 2.4x, is the most consequential number here. AI agents pulling from optimized sites are significantly more likely to extract the correct answer and attribute it properly. This connects directly to the
ChatGPT citation mechanics we covered earlier: retrieval rank is the dominant signal for whether a page gets cited, and agent-optimized pages improve their retrieval position by making their content more parseable.Non-optimized site
- Agent parses full HTML including nav, ads, footers
- Token consumption: ~4,200 per page average
- Retrieval accuracy: baseline
- Answer latency: baseline
- Content mixed with boilerplate in context window
Agent-optimized site
- Agent reads llms.txt or clean semantic content
- Token consumption: ~2,900 per page average (31% less)
- Retrieval accuracy: 2.4x baseline
- Answer latency: 66% faster
- Pure content signal, no noise in context window
The compounding advantage: Agent optimization creates a positive feedback loop. Optimized sites get retrieved more accurately, which improves citation rates, which increases agent traffic, which justifies further optimization investment. The sites that start now will be hard to displace once agent routing patterns solidify.
3. Cloudflare AI Training Redirects, Canonical Tags Become 301s for AI Crawlers
Cloudflare launched a new feature that changes how publishers can enforce content hierarchy for AI training crawlers: AI Training Redirects. It converts your existing `rel=canonical` tags into hard 301 redirects, but only for identified AI crawlers.
How it works
When a human visitor or Googlebot requests a non-canonical URL, say, a paginated version, a parameter variant, or a syndicated copy, they get a normal 200 response with a `rel=canonical` tag pointing to the preferred URL. The canonical tag is a hint. Googlebot may or may not follow it, as
Mueller's 9 canonical override scenarios show. When GPTBot, ClaudeBot, or Bytespider requests that same non-canonical URL, Cloudflare intercepts the request at the edge and returns a 301 permanent redirect to the canonical URL instead. The AI crawler never sees the duplicate content. It's forced to the canonical version. Full stop.The crawler traffic numbers
Cloudflare's internal data reveals the scale of AI crawler traffic hitting sites with this feature enabled:
| AI crawler | Approximate visits | Organization |
|---|---|---|
| GPTBot | ~46,000 | OpenAI |
| ClaudeBot | ~3,600 | Anthropic |
| Bytespider | ~1,700 | Meta / ByteDance |
Why this matters for SEO
The feature solves a problem that's frustrated publishers since AI crawlers became widespread:
canonical tags are hints for all crawlers, including AI ones. An AI training pipeline that ingests a paginated or parameterized URL variant trains on content it wasn't supposed to see as a standalone page. Worse, it may index the non-canonical version as a separate source, diluting the canonical's authority in the AI model's training data. With AI Training Redirects, the canonical relationship becomes a hard redirect for AI crawlers only. Human visitors and traditional search engines continue receiving the normal response. It's a surgical enforcement mechanism that doesn't break existing SEO or user experience.Implementation note: AI Training Redirects is a Cloudflare dashboard toggle, no code changes required. It reads your existing
rel=canonical
tags and applies the redirect logic at the CDN edge. If your canonical tags are accurate, enabling the feature is a one-click improvement. If your canonical tags have errors (and many do), fix those first, a 301 redirect to the wrong canonical is worse than no redirect at all.
Caveat: This feature currently targets GPTBot, ClaudeBot, and Bytespider based on user-agent strings. AI crawlers that don't identify themselves, or that use rotating user agents, will bypass the redirect. It's an enforcement mechanism for compliant crawlers, not a universal solution. The ~46K visits from GPTBot suggest OpenAI is playing by the identification rules; whether all AI labs continue to do so is an open question.
Key takeaway
If you're on Cloudflare, enable AI Training Redirects today, provided your canonical tags are accurate. It ensures AI training pipelines only ingest your preferred URL versions, preventing duplicate content from polluting LLM training data. For non-Cloudflare sites, the concept is replicable with edge worker logic on any CDN that supports user-agent-based routing.
4. ChatGPT Cites Reddit Only 1.93%, The 1.4M-Prompt Study
Ahrefs analyzed 1.4 million ChatGPT prompts and found a striking disconnect: Reddit pages are retrieved constantly by ChatGPT's search but almost never cited in the final answer. The citation rate is just 1.93%. We covered this study and its full implications in our analysis of ChatGPT's citation mechanics, but the finding deserves attention here for what it reveals about URL structure and citation behavior.
The URL structure signal
The most actionable finding from the Ahrefs data is the role of URL structure in citation rates:
For SEOs: URL structure has always mattered for Google rankings. Now it matters for AI citation too. If you're running a site with clean permalink structures and focused content, you already have a structural advantage over forums, social platforms, and sites with complex URL schemas. Keep slugs short, keyword-focused, and descriptive, they're being read by machines making citation decisions.
5. IAB 2025: Social Media Ads Overtake Search for the First Time
The Interactive Advertising Bureau's 2025 report marks a historic crossover: social media advertising revenue ($117 billion) has overtaken search advertising ($114 billion) for the first time. Total US digital ad spend hit $294 billion.The budget rebalancing risk: When CMOs see "social overtakes search" headlines, budget reallocation follows. SEO teams should prepare a data-backed case for organic search's compounding ROI, especially as AI search creates new citation and visibility channels that social media can't replicate. The AI slop loop affecting social content quality strengthens the case for authoritative organic search content.
6. Chrome AI Mode: Side-by-Side Browsing
Google is testing an AI Mode integration directly in Chrome that enables side-by-side browsing, an AI assistant panel that sits alongside the normal browser window. Users can ask questions about the page they're viewing, get summaries, compare products across tabs, and trigger agentic actions without leaving the current site. This is distinct from Google's existing AI Mode in search results. Chrome AI Mode operates at the browser level, not the search results level. It means: - Every webpage becomes an AI context. The AI panel can read and summarize page content, extract data points, and cross-reference with other open tabs. - Comparison shopping gets automated. Open three product pages, ask Chrome AI to compare them, get a structured comparison without visiting a review site. - On-page actions become agentic. The AI can potentially interact with page elements, fill forms, trigger bookings, add to cart, blurring the line between browsing and agent-driven task completion. For SEOs, Chrome AI Mode represents a new surface where content quality directly impacts user engagement. Sites with well-structured, semantically clear HTML will produce better AI summaries and comparisons than sites with cluttered markup. This connects directly to Cloudflare's agent readiness findings: the same optimizations that help AI crawlers, clean semantic HTML, structured data, minimal boilerplate, will help Chrome AI Mode surface your content effectively.Immediate implication: If Chrome AI Mode rolls out broadly, the "zero-click" problem expands from search results to the entire browsing experience. Users may extract value from your page via the AI panel without scrolling, clicking, or engaging with your CTAs. Pages tuned for AI readability, clear headings, structured data, concise answers, will perform better in the AI panel, but may also give users less reason to engage with the page itself. This is the same tension as AI Overviews, now applied to every page on the web.
7. Strategic Synthesis, Immediate and Medium-Term Actions
This week's developments converge on a single theme: the web is being re-intermediated by AI agents, and the sites that declare their preferences and tune their content for machine consumption first will capture disproportionate visibility.
Immediate actions (this week)
| Action | Priority | Effort |
|---|---|---|
| Audit your robots.txt for AI crawler directives. Add explicit rules for GPTBot, ClaudeBot, Bytespider, and other AI crawlers. Decide: block, allow, or selective access. | High | 30 min |
| Enable Cloudflare AI Training Redirects (if on Cloudflare). Verify your canonical tags are accurate first. | High | 15 min |
Create an llms.txt file. Start with a concise summary of your site's content, purpose, and key pages. Place at root: /llms.txt. | Medium | 1-2 hours |
| Clean up URL structures. Ensure key landing pages use short, descriptive, keyword-focused slugs, these are being used as citation quality signals by AI systems. | Medium | Variable |
| Review AI crawler traffic in server logs. Identify which AI bots are crawling your site, how frequently, and which pages they hit most. | Medium | 1 hour |
Medium-term actions (next 30 days)
| Action | Priority | Effort |
|---|---|---|
| Implement structured data for agent capabilities. If your site supports transactions (booking, purchasing, scheduling), declare these as structured actions. This is the precursor to MCP Server Cards. | High | 1-2 days |
| Tune content for token efficiency. Reduce boilerplate HTML, improve semantic markup, and ensure main content is easily extractable from page chrome. | Medium | Ongoing |
| Build an AI-first content layer. For your top 20 pages, create concise, machine-readable versions that serve AI agents without the visual design layer. | Medium | 1 week |
| Prepare a search vs. social budget defense. Use IAB data + your own organic performance data to build the case for maintaining search investment as social overtakes in total ad spend. | Low | 2-3 hours |
| Monitor Chrome AI Mode beta. If your site is in verticals likely to be affected (e-commerce, SaaS, travel), test how your pages render in Chrome's AI panel and tune accordingly. | Low | Ongoing |
The bigger picture
Cloudflare's Agent Readiness Score is the first quantitative benchmark for a shift that will define SEO over the next 2-3 years. The web was built for human browsers, then tuned for search crawlers, and is now being re-tuned for AI agents. Each transition has favored early movers, sites that adopted meta tags early dominated early search, sites that adopted structured data early dominated rich results. The pattern repeats. The 4% of sites that have declared AI preferences today will refine their approach as standards mature. The 96% that haven't started will face a compounding disadvantage as AI agents increasingly favor sites that speak their language. A thorough
technical SEO assessment is the fastest way to identify gaps and build a roadmap.Key takeaway
AI agent readiness isn't a future concern, it's a current competitive advantage. The 31% token efficiency gain and 66% speed improvement for optimized sites translate directly into better citation rates and higher visibility in AI-mediated discovery. Start with robots.txt and llms.txt this week. Build toward structured capability declarations over the next quarter.
Frequently Asked Questions
What is Cloudflare's Agent Readiness Score?
Cloudflare's Agent Readiness Score is a composite metric measuring how prepared a website is for AI agent interaction. It evaluates four layers: AI-specific robots.txt directives, llms.txt file adoption, explicit AI preference declarations, and support for agent protocols like MCP Server Cards. Cloudflare Radar scanned 200,000 domains and found only 4% have any AI preferences declared.
What is llms.txt and should I create one?
llms.txt is a proposed standard file (placed at your site's root, like robots.txt) that provides a machine-readable summary of your site's content tuned for LLM consumption. It helps AI agents understand your site's purpose, key pages, and content structure without parsing full HTML. Creating one is recommended, it contributes to the 31% token reduction and 66% faster answer generation that Cloudflare measured for agent-optimized sites.
How do Cloudflare AI Training Redirects work?
AI Training Redirects convert your existing rel=canonical tags into hard 301 redirects, but only for identified AI crawlers (GPTBot, ClaudeBot, Bytespider). When a human or Googlebot visits a non-canonical URL, they get a normal 200 response with the canonical hint. When an AI crawler visits the same URL, Cloudflare returns a 301 redirect to the canonical version, ensuring AI training pipelines only ingest your preferred content. It's a dashboard toggle on Cloudflare, no code changes required.
Why does ChatGPT cite Reddit so rarely despite retrieving it constantly?
Ahrefs' 1.4 million prompt study found ChatGPT cites Reddit pages at just 1.93%. The primary factors are Reddit's complex threaded URL structure (which scores poorly as a citation quality signal), the high comment-to-signal noise ratio on most threads, and the user-generated nature of the content which makes it harder for ChatGPT to attribute authoritative claims. Pages with clean URL structures are cited at 89.78% when retrieved, compared to 81.11% for complex URLs.
Has social media advertising really overtaken search?
Yes. The IAB's 2025 report shows social media advertising revenue reached $117 billion, surpassing search advertising at $114 billion for the first time. Total US digital ad spend hit $294 billion. Search isn't declining, it grew 11% year-over-year. Social simply grew faster at 16%, driven by short-form video and commerce integrations. Both channels are simultaneously being reshaped by AI.
What is Chrome AI Mode and how does it differ from Google AI search?
Chrome AI Mode is a browser-level AI assistant that sits alongside the normal browsing window, enabling side-by-side interaction with any webpage. Unlike Google's AI Mode in search results (which operates at the query/results level), Chrome AI Mode operates on any page, summarizing content, comparing products across tabs, and potentially triggering on-page actions. It expands the "zero-click" active from search results to the entire browsing experience.
What should I do this week to improve AI agent readiness?
Start with three actions: (1) Audit your robots.txt and add explicit directives for AI crawlers, GPTBot, ClaudeBot, Bytespider. (2) If you're on Cloudflare, enable AI Training Redirects after verifying your canonical tags are accurate. (3) Create an llms.txt file at your site root with a concise summary of your content and key pages. These three steps move you from the 96% with no AI preferences to the 4% that have started declaring them.
About the Author
