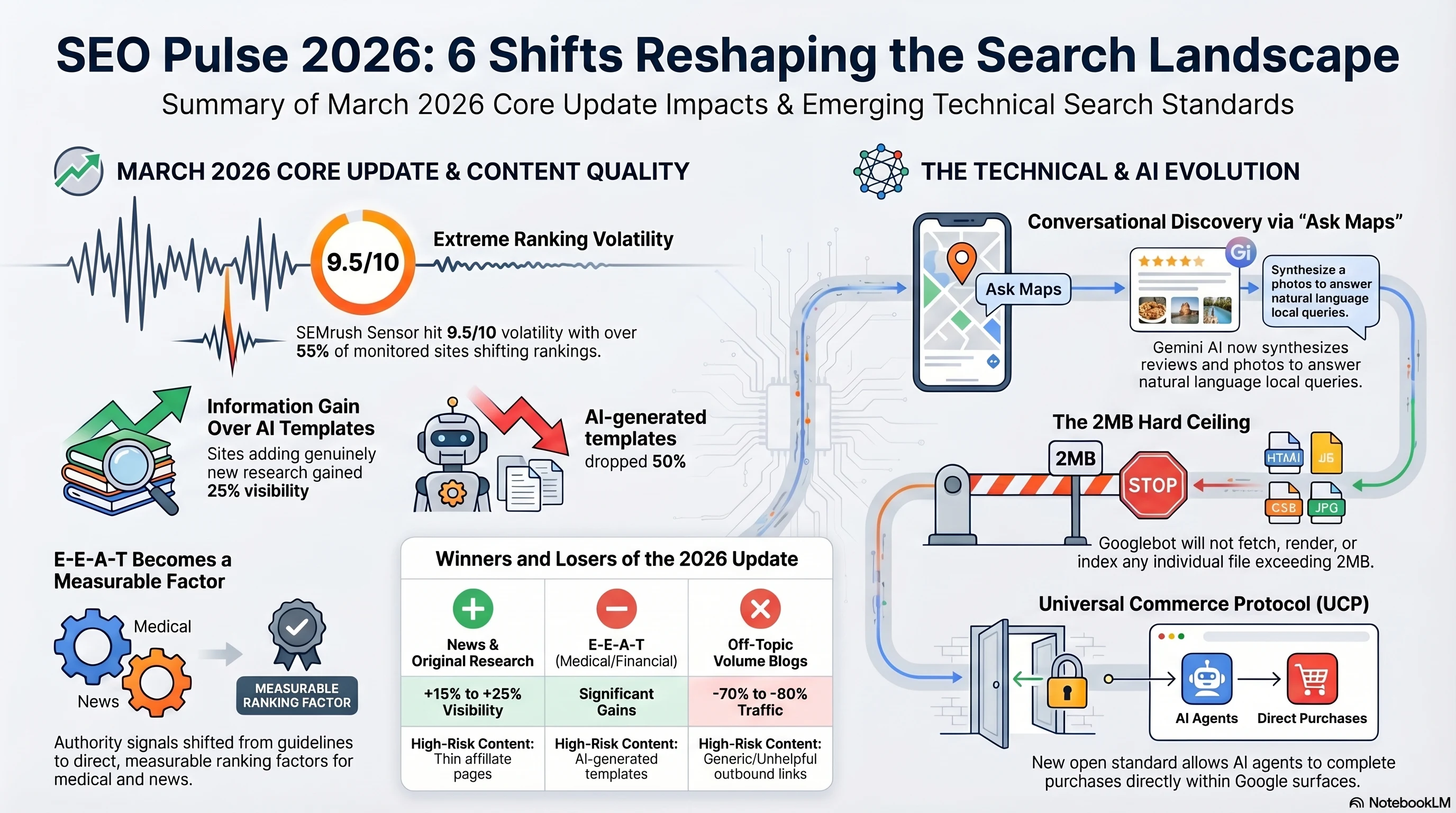
Google's Back Button Hijacking Spam Policy and the 815K-Page ChatGPT Citation Study
Google adds back button hijacking to spam policies with a June 15 enforcement deadline. Plus: AirOps' 815,000-page study reveals shorter content wins ChatGPT citations — retrieval rank beats domain authority, and 'ultimate guides' underperform focused articles.
Updated April 14, 2026Francisco Leon de Vivero
Two stories worth actual calendar entries today. Google just classified back button hijacking as spam — same tier as malware , with a June 15 enforcement deadline that gives sites exactly 62 days to audit every History API call on their pages. Separately, AirOps published the largest public study of ChatGPT citation behavior: 815,000 query-page pairs across 15,000 queries, and the findings overturn several assumptions about what content gets cited. Shorter beats longer. Heading match beats domain authority. And 85% of pages ChatGPT retrieves never appear in the final answer.
The six shifts driving SEO strategy this week , from Google's new spam policy to ChatGPT's citation mechanics.
1. Back Button Hijacking Is Now Spam , Enforcement June 15
On April 13, 2026, Google Search Central published a new spam policy adding back button hijacking to the "malicious practices" category , the same classification tier as malware distribution and unwanted software. This isn't a soft guideline. It carries manual action penalties, algorithmic demotions through SpamBrain, and potential Google Ads disqualification.
June 15Enforcement begins
62 daysCompliance window
2 pathsManual actions + SpamBrain
Ads riskLinked to eligibility since Dec 2024
What exactly is back button hijacking?
Back button hijacking happens when a site manipulates browser navigation to stop users returning to the page they came from. Instead of going back, users get redirected to pages they never visited , interstitial ads, affiliate redirects, recommendation traps. The behavior inflates pageview metrics and ad impressions while making the web measurably worse for users. Google's policy definition is precise: any practice where *"a site interferes with user browser navigation by manipulating the browser history or other functionalities, preventing them from using their back button."*
The three History API methods
Google is targeting The policy names three JavaScript mechanisms used for back button hijacking:
// These are flagged when used deceptively:
history.pushState() // Inserts fake entries into browser history
history.replaceState() // Overwrites the current history entry
popstate event listener // Intercepts back-button clicks
Legitimate single-page applications use these APIs constantly , React Router, Vue Router, and Next.js all rely on `pushState` for client-side navigation. The distinction Google draws is deceptive use: inserting entries the user never navigated to, or intercepting the back button to redirect users to monetization pages instead of their actual previous page.
Third-party code is your problem. Google explicitly states that responsibility extends to all scripts on the page , including ad platform code, tag managers, and third-party libraries. If a vendor's JavaScript hijacks the back button on your site, you face the penalty, not the vendor. A thorough technical SEO audit is the fastest way to surface every history-manipulating script before June 15.
Two enforcement pathways
Pathway
Mechanism
How it resolves
Manual spam action
Human reviewers reduce or remove search visibility
Reconsideration request after fixing the issue
Automated demotion
SpamBrain algorithmically demotes affected pages
Resolves over time as compliance improves
There's a third consequence most coverage has missed: since December 2024, Google has linked search spam manual actions to Google Ads eligibility. A manual action for back button hijacking could simultaneously kill organic visibility and paid advertising for the affected domain. The blast radius is wider than any previous spam policy update.
Who should be auditing right now
Google's blog post calls out recipe aggregators, news sites with interstitials, and affiliate-heavy pages as common offenders. But the real risk is less obvious. Any site running multiple ad networks, affiliate scripts, or engagement plugins through a tag manager is exposed. These scripts interact in ways that are hard to predict, and a single vendor injecting `pushState` calls can trigger the policy violation.
Audit checklist for this week:
Search your codebase for history.pushState, history.replaceState, and popstate
Open Chrome DevTools → Application → Back/forward cache → test navigation on 10 high-traffic pages
Check every script loaded through your tag manager (GTM, Tealium, etc.)
Test pages with ad scripts enabled , back button should always return to the referrer
Ask ad vendors in writing whether their scripts modify browser history
Back button hijacking enforcement timeline , April 13 announcement, June 15 deadline, two parallel enforcement paths.
Key takeaway
You have 62 days. Third-party scripts are your liability. A manual action can kill both organic rankings and Google Ads eligibility. Start the audit now , not in June.
2. The 815K-Page Study: What Content Actually Gets Cited by ChatGPT
AirOps published the largest public study of ChatGPT citation mechanics on April 13, 2026, analyzing 815,000 query-page pairs across 15,000 queries, 548,534 retrieved pages, and 82,108 citations in 10 industries. Kevin Indig's analysis in Growth Memo adds a second lens with 16,851 queries and 353,799 pages. Together, they give us the first statistically significant picture of what earns a ChatGPT citation , and the answer upends several widely held assumptions.
15%Retrieved pages that get cited
58%Citation rate at retrieval position 0
14%Citation rate at retrieval position 10
3.5×Citation advantage: Google #1 vs. beyond top 20
Finding #1: Retrieval rank is the dominant signal
The single strongest predictor of whether ChatGPT cites a page is its retrieval position , the order in which ChatGPT's internal search returns the page. At position 0, the citation rate is
58%. By position 10, it drops to 14%. That's a steeper drop-off than Google's own organic CTR curve. The practical implication: ChatGPT's retrieval system leans heavily on Google's index. Pages ranking in Google's top 20 account for 55.8% of all ChatGPT citations. A page ranking #1 in Google has a 43.2% citation rate in ChatGPT , 3.5× higher than pages ranking beyond position 20. Google SEO is, counterintuitively, the highest-use channel for ChatGPT visibility.
Finding #2: Domain authority is irrelevant
This is the most counterintuitive result in the study. AirOps found that
DA 20-40 sites earned 26.0% of citations , more than DA 80-100 sites at 25.4%. High-DA pages actually have a *lower* citations-per-retrieval rate: 15.0% versus 21.5-23.6% for DA 0-80 pages. The study's blunt summary: *"Always-cited pages have lower DA than never-cited pages."* Domain authority helps with retrieval , getting pulled into ChatGPT's context window , but actively hurts citation rate once retrieved. Why? High-DA sites tend toward broad, full content that dilutes query-specific relevance. Big brand, diffuse answer. Doesn't get cited.
ChatGPT citation rates by retrieval position, domain authority, and content length , the 815K-page AirOps + Growth Memo combined dataset.
3. The Death of the Ultimate Guide (for AI Citations)
The study's most actionable finding concerns content structure. Full "ultimate guides" , the content strategy that dominated SEO from 2018 to 2024 , are the least reliable performers in ChatGPT.
Content type
Word count
Citation behavior
Always-cited pages
500–2,000 words
Focused, high query match, direct headings
Mixed performers
Highest word counts
Highest DA, but least reliable citation rate
Never-cited pages
Variable
Low heading match, broad topic coverage
Pages covering 26-50% of ChatGPT's fan-out subtopics outperform pages covering 100%. Covering every subtopic exhaustively adds only 4.6 percentage points over covering none. The "10x content" thesis , that longer, more full content wins , is measurably false for AI citation. Full stop. The optimal content profile:
- 500–2,000 words , tight enough to maintain query-specific focus
- 7–20 subheadings , enough structure for retrieval, not so much it dilutes relevance
- Headings that directly answer the query , pages with 0.90+ heading match achieve 41% citation rate versus 30% below 0.50
- One question, one best answer , not adequate answers to twenty tangential questions
The Wikipedia exception: Wikipedia achieves a 59% citation rate despite a median retrieval rank of 24 and the lowest query match score (0.576). It compensates with exhaustive structured coverage , 4,383 average words, 31 lists, 6.6 tables per article. This works because Wikipedia's scale and structure are unique. For everyone else, shorter and focused wins.
The death of the ultimate guide , focused 500–2,000 word pages with query-aligned headings outperform full long-form for AI citation.
4. Fan-Out Queries: The Hidden Discovery Channel
One of the study's most important findings for content strategists is how ChatGPT actually finds content. When a user asks ChatGPT a question, the system doesn't just search for that query. It generates fan-out sub-queries , decomposed, reformulated versions of the original question , and searches for each one independently. The numbers are striking:
- 89.6% of ChatGPT searches trigger 2+ fan-out queries
- 32.9% of cited pages are discovered only through fan-out , not the original query
- 95% of fan-out queries have zero monthly search volume in traditional keyword tools One-third of ChatGPT citations go to pages that'd never appear in a keyword research workflow. ChatGPT's internal retrieval system decomposes questions in ways that don't map to how humans search on Google. A page about "best CRM for nonprofits" might get cited in response to "how should a small charity manage donor relationships" , through a fan-out query the content creator never targeted. This is, apparently, how content discovery works in 2026.
Fan-out behavior varies by intent
Query type
Fan-out behavior
Citation rate
Product awareness
Expands into feature/benefit sub-queries
18.3%
How-to
42.6% near-verbatim, rest decomposed into steps
16.9%
Comparison
38.4% split into per-option sub-queries
13.1%
Validation
40.6% near-verbatim
11.3%
Product discovery and how-to queries have the highest citation rates. Comparison and validation queries , where ChatGPT is trying to confirm or contrast , cite fewer sources, partly because the model has higher internal confidence on factual claims it can cross-reference.
Fan-out queries as the hidden discovery channel , one-third of ChatGPT citations come from sub-queries invisible to keyword research tools.
5. Title-Query Alignment: The 2.2× Citation Lift
AirOps measured title-query overlap , the percentage of query words that appear in the page's title tag , and found a clean linear relationship with citation rates:
Title-query overlap
Citation rate
50%+ overlap
20.1%
<10% overlap
9.3%
That's a 2.2× lift from stronger title alignment , without changing any other variable. And it doesn't stop at the `` tag. H1 and H2 headings function as relevance signals during retrieval too. Kevin Indig's heading match metric confirms it: pages with 0.90+ heading cosine similarity to the query achieve 41% citation rates versus 30% for pages below 0.50. The mechanism is straightforward: ChatGPT's retrieval system uses heading text as a primary relevance signal, similar to how Google uses title tags for ranking but with even more weight. Pages whose headings *are* the query , or close paraphrases , get cited. Pages with clever, engagement-tuned headlines that don't contain the query terms get retrieved and then discarded. <div class="pulse4-callout">
<p><strong>Practical implication:</strong> If you're optimizing for AI citations alongside Google rankings, use descriptive headings over clever headings. "How to migrate from Shopify to WooCommerce" will outperform "The Ultimate Platform Switch Guide" in ChatGPT citation every time , even if the second title earns more clicks on Google.</p>
</div> <div class="pulse4-image">
<figure>
<img src="/assets/images/posts/back-button-chatgpt/section-5-title-query-alignment.webp?v=2" alt="Infographic showing title-query overlap vs citation rate: 50%+ overlap yields 20.1% citation rate versus 9.3% for under 10% overlap , a 2.2× lift" width="1600" height="900" loading="lazy">
<figcaption>Title-query alignment drives a 2.2× citation lift , descriptive headings beat clever ones in ChatGPT retrieval.</figcaption>
</figure>
</div> <h2 id="q2-strategy">6. What This Means for Content Strategy in Q2 2026</h2> The AirOps data creates a clear fork in content strategy. Google and ChatGPT now reward meaningfully different content structures, and the gap is widening as ChatGPT's retrieval system matures. Pick your audience. Build for it deliberately. <h3>For Google organic rankings</h3><p>- Full coverage still works , topical authority matters - Backlinks and domain authority remain solid ranking signals - Long-form content (2,000-5,000 words) performs well for competitive head terms - E-E-A-T signals (author credentials, citations, experience demonstrations) are weighted heavily ### For ChatGPT citations - Focused, single-topic pages (500-2,000 words) outperform full guides - Domain authority is irrelevant , retrieval rank and heading match dominate - Descriptive, query-matching headings lift citation rates 2.2× - Moderate subtopic coverage (26-50%) beats exhaustive coverage - Google ranking is still the primary input , 55.8% of ChatGPT citations come from Google top-20 pages The resolution isn't to choose one or the other. Build</p><strong>focused hub pages</strong> , single-topic, 1,000-1,500 word pages with precise headings , and link them into broader topic clusters. The hub pages serve <a href="/ai-seo/">ChatGPT and AI search citation</a>. The cluster serves Google topical authority through disciplined <a href="/content-marketing/">content strategy</a>. Both benefit from Google rankings, which remain the common input for both systems. For a primary-source read, the full <a href="https://www.airops.com/report/influence-of-retrieval-fanout-and-google-serps-in-chatgpt" target="_blank" rel="noopener">AirOps 815K-page citation study</a> is worth working through. <div class="pulse4-image">
<figure>
<img src="/assets/images/posts/back-button-chatgpt/section-6-q2-2026-content-strategy.webp?v=2" alt="Infographic contrasting Google-optimized content (long-form, high DA, backlinks) with ChatGPT-optimized content (focused 500–2,000 word hubs, heading match, moderate coverage) for Q2 2026 content strategy" width="1600" height="900" loading="lazy">
<figcaption>Q2 2026 content strategy , focused hub pages for ChatGPT citation, linked into broader clusters for Google topical authority.</figcaption>
</figure>
</div> <h2 id="compliance">7. The Compliance Calendar: What to Do This Week</h2> <h3 id="back-button-hijacking-audit-deadline-june-15">Back button hijacking audit (deadline: June 15)</h3>
1. <strong>Day 1:</strong> Grep your JavaScript for `history.pushState`, `history.replaceState`, and `popstate`. Flag every instance.
2. <strong>Day 2:</strong> Audit tag manager containers , export all tags, search for history manipulation in ad scripts, affiliate scripts, and engagement plugins.
3. <strong>Day 3:</strong> Test the 20 highest-traffic pages manually: click through from Google, then click back. If you don't land on Google, you have a violation.
4. <strong>Day 4-5:</strong> Contact vendors running offending scripts. Get removal or fix timelines in writing.
5. <strong>Week 2:</strong> Deploy fixes, re-test, document compliance for potential reconsideration request. <h3>ChatGPT citation optimization (ongoing) 1. Identify your top 20 pages by</h3><p>Google ranking. These are your highest-probability ChatGPT citation candidates. 2. Rewrite H1 and H2 headings to directly match the queries you want to be cited for. 3. If any page exceeds 3,000 words, consider splitting it into focused single-topic pages. 4. Add structured data (FAQ schema, HowTo schema) to improve retrieval signals. 5. Monitor ChatGPT citations using tools like Otterly.ai or manual testing , search for your brand and key topics in ChatGPT weekly.</p><div class="post-related">
<h2>Related articles</h2>
<ul>
<li><a href="/insights/core-update-ask-maps/">March 2026 Core Update Aftermath, Ask Maps Revolution, and the 11-Month GSC Bug</a><span class="post-related__meta">April 14, 2026 , Local search AI + GSC recovery</span></li>
<li><a href="/insights/2mb-agentic-commerce/">Googlebot's 2MB Cutoff, the Agentic Commerce Arms Race, and Who Won the March Core Update</a><span class="post-related__meta">April 13, 2026 , Crawl limits + UCP vs OpenAI</span></li>
<li><a href="/insights/core-update-gsc-llm/">April 2026: Core Update Aftermath, the GSC Impressions Bug, and Why LLM Bots Now Out-Crawl Googlebot</a><span class="post-related__meta">April 12, 2026 , LLM crawler trends</span></li>
</ul>
</div> <h2 id="faq">8. Frequently Asked Questions</h2> <div class="pulse4-faq"> <div class="pulse4-faq-item">
<h4>What is Google's new back button hijacking spam policy?</h4>
<p>Announced April 13, 2026, Google now classifies back button hijacking as spam under its "malicious practices" category , the same tier as malware distribution. Sites that manipulate browser history via JavaScript ( <code>history.pushState</code>, <code>history.replaceState</code>, <code>popstate</code> listeners) to prevent users from navigating back will face manual actions or algorithmic demotions via SpamBrain. Enforcement begins June 15, 2026.</p>
</div> <div class="pulse4-faq-item">
<h4>What History API methods does the back button hijacking policy cover?</h4>
<p>Google flags deceptive use of <code>history.pushState()</code>, <code>history.replaceState()</code>, and <code>popstate</code> event listeners. Any script , including third-party ad libraries and tag managers , that inserts fake entries into browser history or intercepts back-button clicks to redirect users to unvisited pages violates the policy. Site owners are responsible even when the offending code comes from third-party vendors.</p>
</div> <div class="pulse4-faq-item">
<h4>How many pages does ChatGPT retrieve versus actually cite?</h4>
<p>AirOps analyzed 548,534 pages retrieved by ChatGPT across 15,000 queries and found only 15% were cited in final responses. 58% of retrieved pages are never cited, 25% are always cited when retrieved, and 17% fall in between. The study produced 82,108 total citations for analysis.</p>
</div> <div class="pulse4-faq-item">
<h4>Does domain authority matter for ChatGPT citations?</h4>
<p>No. AirOps found domain authority is irrelevant for ChatGPT citation likelihood. DA 20-40 sites earned 26.0% of citations versus 25.4% for DA 80-100 sites. High-DA pages actually had a lower citations-per-retrieval rate (15.0%) compared to DA 0-80 pages (21.5-23.6%). Retrieval rank and heading-query alignment are far stronger predictors.</p>
</div> <div class="pulse4-faq-item">
<h4>What is the optimal content length and structure for ChatGPT citations?</h4>
<p>Pages between 500 and 2,000 words with 7-20 subheadings perform best. Full "ultimate guides" are the least reliable performers. Covering 26-50% of ChatGPT's fan-out subtopics outperforms covering 100%. Headlines should directly match the query , pages with 0.90+ heading match achieve a 41% citation rate versus 30% for pages below 0.50.</p>
</div> <div class="pulse4-faq-item">
<h4>What are fan-out queries in ChatGPT and why do they matter for SEO?</h4>
<p>Fan-out queries are sub-queries ChatGPT generates from the original user question to gather information from multiple angles. 89.6% of searches trigger 2+ fan-out queries, and 32.9% of cited pages are discovered only through fan-out , not the original query. 95% of fan-out queries have zero monthly search volume, meaning traditional keyword research misses them entirely.</p>
</div> <div class="pulse4-faq-item">
<h4>How does Google's SERP ranking correlate with ChatGPT citations?</h4>
<p>Google's top-20 SERP pages account for 55.8% of all ChatGPT citations. Pages ranking #1 in Google are cited by ChatGPT 43.2% of the time , a 3.5× advantage over pages ranking beyond position 20. Google SEO remains the single highest-use channel for ChatGPT visibility.</p>
</div> </div> <h2 id="about-the-author">About the Author</h2> <div class="prose-author">
<img class="prose-author__image" src="/assets/images/francisco/francisco-conference.jpg" alt="Francisco Leon de Vivero at an industry conference">
<div class="prose-author__body">
<p class="eyebrow">About the author</p>
<h3>Francisco Leon de Vivero</h3>
<p>Francisco is a global SEO expert and VP of Growth at Growing Search with 15+ years of experience across enterprise, ecommerce, and international search. Former Head of Global SEO Plan at Shopify, he now helps brands and ecommerce teams build senior-level SEO strategy. Speaker at UnGagged, SEonthebeach, and Quondos. Published in Forbes and Huffington Post. Judge for Canadian and European search awards.</p>
<p class="prose-author__links">
<a href="https://www.linkedin.com/in/seofrancisco/" target="_blank" rel="noopener">LinkedIn</a>
<a href="https://www.youtube.com/c/SEOFrancisco/videos" target="_blank" rel="noopener">YouTube</a>
<a href="/consultation/">Book a consultation</a>
</p>
</div>
</div>
</div>
<div class="post-next-steps">
<div class="section-heading post-next-steps__heading">
<p class="eyebrow">Next step</p>
<h2>Turn this background reading into a more current SEO plan.</h2>
<p>Use the most relevant current page below if this topic is still on your roadmap, then review the proof and contact paths if you want direct support.</p>
</div>
<div class="path-grid">
<article class="path-card path-card--accent path-card--service card-with-mark">
<div class="service-mark" aria-hidden="true">
<svg viewBox="0 0 64 64" aria-hidden="true" focusable="false">
<defs>
<linearGradient id="grad-tech" x1="0%" y1="0%" x2="100%" y2="100%">
<stop offset="0%" stop-color="#23b7ff" />
<stop offset="100%" stop-color="#1a6fff" />
</linearGradient>
</defs>
<rect x="17" y="17" width="30" height="30" rx="9" fill="url(#grad-tech)" />
<path d="M24 28h16M24 36h11" fill="none" stroke="#fff" stroke-width="4.5" stroke-linecap="round" />
<circle cx="44" cy="36" r="4" fill="#ff9e3d" />
</svg>
</div>
<p class="audience-card__kicker">Current service page</p>
<h3><a href="/technical-seo-advisory/">Technical SEO Advisory</a></h3>
<p>The goal is not audit sprawl. It is translating complex technical issues into prioritized actions that development and marketing teams can actually execute.</p>
<a class="text-link" href="/technical-seo-advisory/">Explore this service</a>
</article>
<article class="path-card">
<p class="audience-card__kicker">Experience</p>
<h3><a href="/experience/">See the proof behind the advice.</a></h3>
<p>Review Francisco’s platform background, speaking, awards, judging, and leadership experience before reaching out.</p>
<a class="text-link" href="/experience/">Review experience</a>
</article>
<article class="path-card">
<p class="audience-card__kicker">Contact</p>
<h3><a href="/consultation/#cal-inline-embed">Start a focused consultation.</a></h3>
<p>Use the consultation page if you want help turning this topic into clearer priorities, next steps, and measurable SEO momentum.</p>
<a class="text-link" href="/consultation/#cal-inline-embed">Book the consultation</a>
</article>
</div>
</div>
</div>
<aside class="post-sidebar">
<div class="sticky-card sticky-card--service card-with-mark">
<div class="service-mark" aria-hidden="true">
<svg viewBox="0 0 64 64" aria-hidden="true" focusable="false">
<defs>
<linearGradient id="grad-tech" x1="0%" y1="0%" x2="100%" y2="100%">
<stop offset="0%" stop-color="#23b7ff" />
<stop offset="100%" stop-color="#1a6fff" />
</linearGradient>
</defs>
<rect x="17" y="17" width="30" height="30" rx="9" fill="url(#grad-tech)" />
<path d="M24 28h16M24 36h11" fill="none" stroke="#fff" stroke-width="4.5" stroke-linecap="round" />
<circle cx="44" cy="36" r="4" fill="#ff9e3d" />
</svg>
</div>
<p class="eyebrow">Current topic path</p>
<h2>Technical SEO Advisory</h2>
<p>Technical SEO support for teams dealing with crawlability, indexing, migrations, site structure, rendering, Core Web Vitals, and engineering backlogs.</p>
<a class="button button--secondary" href="/technical-seo-advisory/">Explore current page</a>
</div>
<div class="sticky-card author-card">
<div class="author-card__image">
<picture><source type="image/webp" srcset="/assets/optimized/bTHSfTn-Ag-240.webp 240w, /assets/optimized/bTHSfTn-Ag-360.webp 360w, /assets/optimized/bTHSfTn-Ag-480.webp 480w" sizes="14rem"><img src="/assets/optimized/bTHSfTn-Ag-240.jpeg" alt="Francisco Leon de Vivero" loading="lazy" decoding="async" width="480" height="508" srcset="/assets/optimized/bTHSfTn-Ag-240.jpeg 240w, /assets/optimized/bTHSfTn-Ag-360.jpeg 360w, /assets/optimized/bTHSfTn-Ag-480.jpeg 480w" sizes="14rem"></picture>
</div>
<p class="eyebrow">About Francisco</p>
<h2>Francisco Leon de Vivero</h2>
<p>VP of Growth at Growing Search and global SEO expert with 15+ years across Shopify, enterprise search, international growth programs, awards judging, and conference speaking.</p>
<ul class="feature-list feature-list--compact">
<li>Former Head of Global SEO Framework at Shopify</li>
<li>VP of Growth at Growing Search</li>
<li>Speaker, educator, and search awards judge</li>
<li>Focus on technical, international, and growth-led SEO</li>
</ul>
<a class="button button--secondary" href="/about/">View full profile</a>
</div>
<div class="sticky-card">
<p class="eyebrow">Need expert help?</p>
<h2>Turn these SEO insights into an action plan.</h2>
<p>Book one focused hour if you want help turning these ideas into clear priorities and measurable SEO progress.</p>
<a class="button button--primary" href="/consultation/#cal-inline-embed">Book a $200 Consultation</a>
<a class="button button--ghost" href="/case-studies/">Review case studies</a>
</div>
<div class="sticky-card">
<p class="eyebrow">Read Next</p>
<ul class="related-posts">
<li>
<a href="/insights/faq-schema-ai-pivot/">Google Killed FAQ Rich Results: The Full Timeline and Why Schema Now Serves AI, Not SERPs</a>
<span>May 13, 2026</span>
</li>
<li>
<a href="/insights/openai-crawl-gpt5-ai-overviews-seo/">OpenAI Crawl Activity Triples Post-GPT-5 While AI Overviews Cut Organic Clicks 38% | SEO Data Briefing</a>
<span>April 30, 2026</span>
</li>
<li>
<a href="/insights/openai-web-crawl-seo-study/">OpenAI Tripled Its Web Crawl: What the 7-Billion Log File Study Means for Your SEO</a>
<span>April 28, 2026</span>
</li>
</ul>
<a class="text-link" href="/blog/">Browse all blog articles</a>
</div>
</aside>
</div>
</article>
</main>
<footer class="site-footer">
<div class="container site-footer__grid">
<div class="site-footer__intro">
<p class="footer-kicker">SEO Francisco</p>
<h2 class="site-footer__title"><span class="site-footer__title-line">Francisco</span>Leon de Vivero</h2>
<p class="site-footer__lede">Francisco leads growth at Growing Search and helps brands connect technical SEO, international visibility, content systems, and measurable business outcomes.</p>
<div class="footer-pill-row">
<span class="footer-pill">VP of Growth at Growing Search</span>
<span class="footer-pill">Toronto and Montreal offices</span>
<span class="footer-pill">15+ years in SEO</span>
<span class="footer-pill">Technical, Shopify, and international SEO</span>
</div>
</div>
<div class="site-footer__panel site-footer__panel--explore">
<p class="footer-kicker">Explore</p>
<div class="site-footer__stack">
<div class="site-footer__group">
<p class="site-footer__subhead">Navigation</p>
<ul class="footer-list footer-list--primary">
<li><a href="/services/">Services</a></li>
<li><a href="/industries/">Industries</a></li>
<li><a href="/case-studies/">Case Studies</a></li>
<li><a href="/tools/">Tools</a></li>
<li><a href="/blog/">Blog</a></li>
<li><a href="/about/">About</a></li>
<li><a href="/contact/">Contact</a></li>
</ul>
</div>
<div class="site-footer__group">
<p class="site-footer__subhead">Services</p>
<div class="footer-service-grid">
<a class="footer-service-link" href="/international-seo/">International SEO</a>
<a class="footer-service-link" href="/technical-seo-advisory/">Technical SEO Advisory</a>
<a class="footer-service-link" href="/shopify-seo/">Shopify SEO</a>
<a class="footer-service-link" href="/toronto-seo-consultant/">Toronto SEO Consultant</a>
<a class="footer-service-link" href="/ai-seo/">AI SEO</a>
<a class="footer-service-link" href="/ai-seo-audit/">AI SEO Audit</a>
<a class="footer-service-link" href="/content-marketing/">Content Marketing</a>
<a class="footer-service-link" href="/link-building/">Link Building</a>
<a class="footer-service-link" href="/online-reputation-management/">Online Reputation Management</a>
<a class="footer-service-link" href="/youtube-seo/">YouTube SEO</a>
<a class="footer-service-link" href="/growth-accelerator-team/">Growth Accelerator Team</a>
</div>
</div>
</div>
</div>
<div class="site-footer__panel">
<p class="footer-kicker">Connect</p>
<ul class="footer-list">
<li><a href="#" data-chat-toggle>Chat with Sophie</a></li>
<li><a href="https://wa.me/16474930660" target="_blank" rel="noreferrer">WhatsApp</a></li>
<li><a href="/consultation/#cal-inline-embed">Book $200 Consultation</a></li>
<li><a href="https://www.growingsearch.com/" target="_blank" rel="noreferrer">Growing Search</a></li>
<li><a href="/blog/">Blog & Articles</a></li>
<li><a href="https://ca.linkedin.com/company/growingsearch" target="_blank" rel="noreferrer">LinkedIn</a></li>
<li><a href="tel:+16474930660">+1 647 493 0660</a></li>
</ul>
</div>
<div class="site-footer__panel">
<p class="footer-kicker">Offices</p>
<ul class="footer-list footer-list--offices">
<li>
<strong>Toronto</strong>
<span>240 Richmond Street W, Toronto, ON Canada M5V 1V6</span>
</li>
<li>
<strong>Montreal</strong>
<span>1275 Avenue Des Canadiens-De-Montreal L'Avenue, Montreal, Quebec H3B 0G4</span>
</li>
</ul>
</div>
</div>
<div class="container site-footer__meta">
<p>Book a focused $200 SEO consultation or explore broader growth support through Growing Search.</p>
<p>Toronto and Montreal, Canada</p>
<a href="/llm.txt" class="site-footer__sitemap-link">LLM.txt</a>
<a href="/sitemap/" class="site-footer__sitemap-link">Sitemap</a>
</div>
</footer>
<div class="chat-dock" data-chat-dock>
<section class="chat-panel" id="site-chat-panel" data-chat-panel hidden aria-labelledby="site-chat-title">
<div class="chat-panel__header">
<div>
<p class="chat-panel__eyebrow">SEO Francisco</p>
<h2 id="site-chat-title">Contact Francisco</h2>
</div>
<button class="chat-panel__close" type="button" data-chat-close aria-label="Close chat">Close</button>
</div>
<div class="chat-thread" data-chat-thread aria-live="polite" aria-atomic="false"></div>
<form class="chat-form" data-chat-form>
<label class="sr-only" for="site-chat-input">Chat reply</label>
<input class="chat-form__input" id="site-chat-input" data-chat-input type="text" autocomplete="off" placeholder="Type your reply">
<div class="chat-form__actions">
<button class="button button--primary" type="submit" data-chat-submit>Send</button>
<button class="button button--ghost chat-form__restart" type="button" data-chat-restart hidden>Start over</button>
</div>
<p class="chat-form__help" data-chat-help>This chat collects your name, email, and message before sending the inquiry.</p>
<p class="chat-form__status" data-chat-status aria-live="polite"></p>
</form>
</section>
</div>
<aside class="sophie-scroll-card" data-sophie-scroll-card aria-label="Chat with Sophie" hidden>
<button class="sophie-scroll-card__close" type="button" data-sophie-scroll-dismiss aria-label="Minimize Sophie chat prompt">×</button>
<div class="sophie-scroll-card__media">
<img src="/assets/images/sophie/sophie-chat-openart-low-blue.webp" alt="Sophie, SEO Francisco chat assistant" width="1792" height="1008" loading="lazy" decoding="async">
<span class="sophie-scroll-card__call" aria-hidden="true">
<svg viewBox="0 0 24 24" focusable="false"><path d="M22 16.92v3a2 2 0 0 1-2.18 2 19.79 19.79 0 0 1-8.63-3.07 19.5 19.5 0 0 1-6-6A19.79 19.79 0 0 1 2.12 4.18 2 2 0 0 1 4.11 2h3a2 2 0 0 1 2 1.72c.12.9.32 1.77.59 2.61a2 2 0 0 1-.45 2.11L8 9.69a16 16 0 0 0 6.31 6.31l1.25-1.25a2 2 0 0 1 2.11-.45c.84.27 1.71.47 2.61.59A2 2 0 0 1 22 16.92Z"/></svg>
</span>
</div>
<div class="sophie-scroll-card__body">
<p>Need a quick SEO answer?</p>
<div class="sophie-scroll-card__actions" aria-label="Contact options">
<button class="sophie-scroll-card__cta" type="button" data-chat-toggle data-sophie-scroll-cta aria-controls="site-chat-panel" aria-expanded="false">
<svg viewBox="0 0 24 24" aria-hidden="true" focusable="false"><path d="M21 15a2 2 0 0 1-2 2H8l-5 4V5a2 2 0 0 1 2-2h14a2 2 0 0 1 2 2z" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round"/></svg>
Chat with Sophie
</button>
<a class="sophie-scroll-card__cta sophie-scroll-card__cta--whatsapp" href="https://wa.me/16474930660" target="_blank" rel="noreferrer" data-sophie-scroll-dismiss-link>
<svg viewBox="0 0 24 24" aria-hidden="true" focusable="false"><path d="M17.47 14.38c-.3-.15-1.76-.87-2.03-.97-.27-.1-.47-.15-.67.15s-.77.97-.94 1.17c-.17.2-.35.22-.65.07-.3-.15-1.26-.46-2.4-1.48-.89-.79-1.49-1.77-1.66-2.07-.17-.3-.02-.46.13-.61.14-.14.3-.35.45-.52.15-.17.2-.3.3-.5.1-.2.05-.37-.02-.52-.08-.15-.67-1.61-.92-2.2-.24-.58-.49-.5-.67-.51h-.57c-.2 0-.52.07-.8.37-.27.3-1.04 1.02-1.04 2.49s1.06 2.88 1.21 3.08c.15.2 2.1 3.2 5.08 4.49.71.31 1.26.49 1.69.63.71.23 1.36.2 1.87.12.57-.09 1.76-.72 2.01-1.41.25-.7.25-1.29.17-1.41-.07-.13-.27-.2-.57-.35zM12.05 21.78c-1.79 0-3.55-.48-5.08-1.39l-.36-.22-3.78.99 1.01-3.69-.24-.38A9.82 9.82 0 0 1 2.2 12.05c0-5.46 4.45-9.9 9.91-9.9a9.83 9.83 0 0 1 7 2.9 9.82 9.82 0 0 1 2.9 7c-.01 5.46-4.45 9.9-9.91 9.9l-.05-.17zM12.05 0C5.44 0 .1 5.34.1 11.92a11.87 11.87 0 0 0 1.6 5.97L0 24l6.3-1.65a11.9 11.9 0 0 0 5.69 1.45h.05C18.64 23.8 24 18.46 24 11.92 24 5.34 18.66 0 12.05 0z" fill="currentColor"/></svg>
WhatsApp
</a>
</div>
</div>
<button class="sophie-scroll-card__mini" type="button" data-sophie-scroll-restore aria-label="Restore Sophie contact options">
<span class="sophie-scroll-card__mini-avatar">
<img src="/assets/images/sophie/sophie-chat-openart-low-blue.webp" alt="" width="96" height="96" loading="lazy" decoding="async">
</span>
<span class="sophie-scroll-card__mini-phone" aria-hidden="true">
<svg viewBox="0 0 24 24" focusable="false"><path d="M22 16.92v3a2 2 0 0 1-2.18 2 19.79 19.79 0 0 1-8.63-3.07 19.5 19.5 0 0 1-6-6A19.79 19.79 0 0 1 2.12 4.18 2 2 0 0 1 4.11 2h3a2 2 0 0 1 2 1.72c.12.9.32 1.77.59 2.61a2 2 0 0 1-.45 2.11L8 9.69a16 16 0 0 0 6.31 6.31l1.25-1.25a2 2 0 0 1 2.11-.45c.84.27 1.71.47 2.61.59A2 2 0 0 1 22 16.92Z"/></svg>
</span>
</button>
</aside>
</body>
</html>