
ChatGPT Cites Search Pages at 88.5% While AI Overviews Lose 61% CTR — The Data Behind AI Search's Split Personality | SEO Pulse — April 27, 2026
Ahrefs study of 1.4M ChatGPT prompts reveals search pages are cited at 88.5% while Reddit sits at 1.9%. Meanwhile, AI Overview CTR crashed 61% and Google

1. 1.4 Million Prompts: What Actually Drives ChatGPT Citations
On April 15, Ahrefs data scientist Xibeijia Guan published the largest empirical study to date on how ChatGPT selects which pages to cite. The dataset: 1.4 million ChatGPT 5.2 desktop prompts from February 2025, producing roughly 23 million cited URLs and 3 million non-cited search URLs. The overall citation rate across all retrieved URLs is almost exactly 50/50 — 49.98% cited versus 50.02% not cited. But that average hides a dramatic hierarchy.
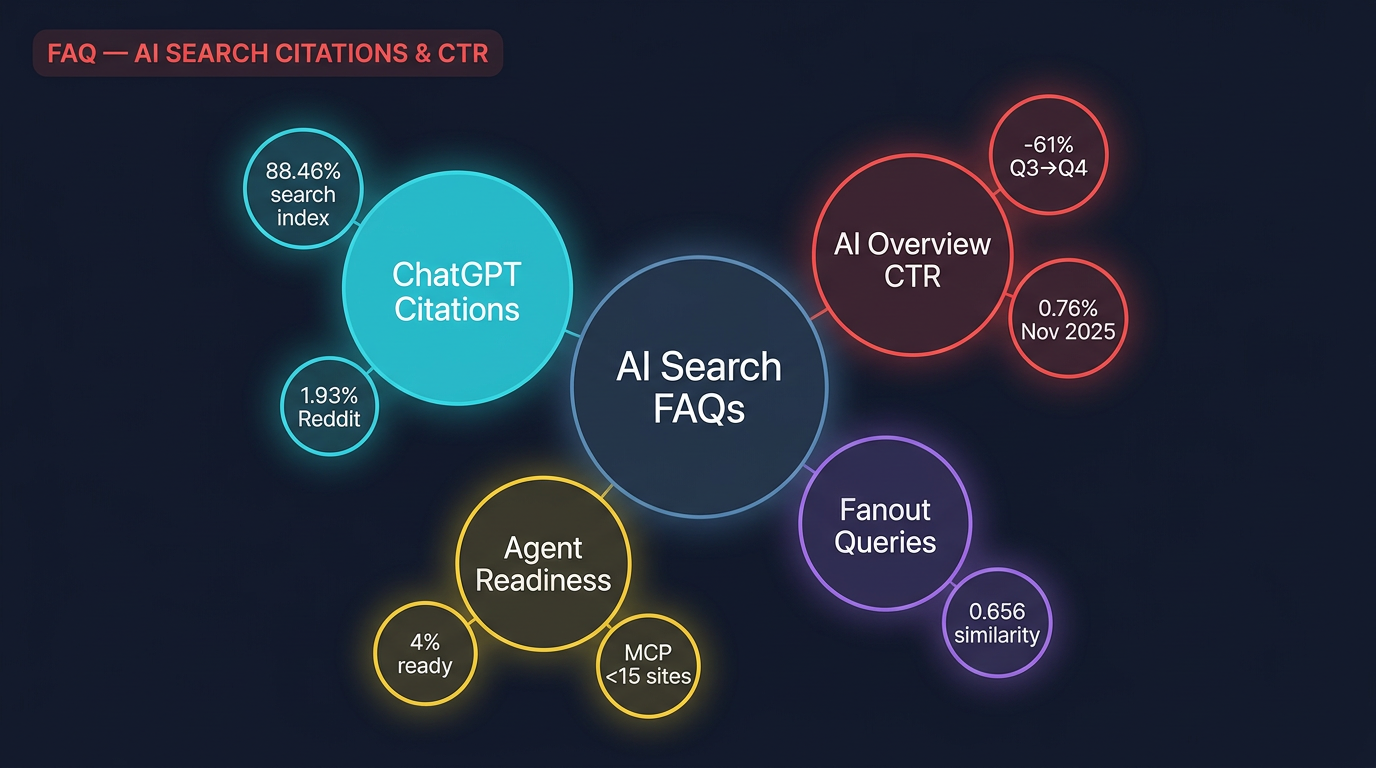
Pages from the general search index , the standard web results that traditional SEO targets , are cited at an 88.46% rate. That's not a typo. Nearly nine out of ten search-index pages ChatGPT retrieves end up cited in the final response. News articles clock in at 12.01%. Reddit, despite being the largest single source by volume with over 16 million retrieved URLs, manages just 1.93%. YouTube (0.51%) and academic sources (0.40%) round out the bottom.
| Source Type | Retrieved URLs | Citation Rate | Share of All Non-Cited |
|---|---|---|---|
| Search (web) | 25,563,589 | 88.46% | , |
| News | 3,940,537 | 12.01% | , |
| 16,182,976 | 1.93% | 67.8% | |
| YouTube | 953,693 | 0.51% | , |
| Academia | 185,337 | 0.40% | , |
The implication is stark: if you want ChatGPT to cite your content, traditional search-index visibility is by far the most reliable path. Being discoverable via standard web search produces an 88.5% citation rate , roughly 46 times higher than Reddit and 175 times higher than YouTube. Brands investing heavily in Reddit SEO or YouTube for AI visibility are optimizing for the wrong channel.
2. Fanout Queries: The Hidden Signal That Determines AI Citations

The Ahrefs study's most consequential finding isn't about source types , it's about how ChatGPT internally decides what to cite. When a user submits a prompt, ChatGPT doesn't simply search for the prompt text. It generates a series of internal sub-questions called "fanout queries" , breaking the original prompt into specific research angles. Guan's team computed cosine similarity between these fanout queries and page titles using open-source embedding models, revealing a significant gap between cited and non-cited pages.
The gap between cited (0.602) and non-cited (0.484) page title similarity to the original prompt is substantial , a 24.4% difference. But the fanout query alignment is even stronger at 0.656, which shows that ChatGPT's internal sub-questions are the true selection mechanism. Your page title doesn't need to match what the user literally typed. It needs to match what ChatGPT internally asks about the topic.
URL Slugs and Freshness: Secondary but Real Signals
Two additional signals came out of the data. Natural language URL slugs (e.g., /why-chatgpt-cites-pages/
) earned an 89.78% citation rate versus 81.11% for opaque slugs (e.g., /p/12847
) , an 8.67 percentage point advantage. ChatGPT uses URL structure as a relevance heuristic. Full stop.
Freshness matters, but not uniformly. For general search content, the median age of cited pages was approximately 500 days (~1.3 years), with citations going to pages as old as 2,700 days (7.4 years). Established, authoritative content keeps earning citations without being new. For news content, the pattern reverses: cited news had a median age of ~200 days versus ~300 days for non-cited news.
Stop optimizing page titles purely for the exact user query. Instead, think about what sub-questions an AI would generate when researching your topic. A page titled "How React Server Components Handle State Hydration" will outperform "React Server Components Guide" because it matches a specific fanout query the model generates when a user asks about React architecture. Specificity and semantic precision beat breadth.
3. The Reddit Paradox: 16 Million Retrievals, 1.93% Citations

Reddit's position in the data demands its own section because it challenges a widely held assumption. Since Google's August 2024 deal with Reddit for AI training data, and Reddit's subsequent surge in organic visibility, many SEOs have treated Reddit optimization as a front-door path to AI citations. The Ahrefs data tells a different story.
ChatGPT retrieved over 16 million Reddit URLs across the study period , more than any other single source. Yet it cited only 1.93% of them, and Reddit accounted for a staggering 67.8% of all non-cited URLs in the entire dataset. Reddit content functions as background research material for ChatGPT , context it consumes during reasoning but in the end won't surface to users.
Why the gap? The most likely explanation is authority signal arbitrage. Reddit posts lack the structured metadata, editorial governance, and institutional credibility that ChatGPT's citation system appears to weight. A Reddit thread may provide useful anecdotal context, but when ChatGPT selects sources to attribute in a response, it gravitates toward pages carrying traditional markers of web authority: clean URL structures, descriptive titles, publication metadata, and domain-level topical credibility.
This doesn't mean Reddit is useless for SEO , it still drives direct referral traffic and can influence traditional search rankings. But as a channel for AI citation acquisition, the data is unambiguous: investing in your own search-indexed content (88.5% citation rate) delivers roughly 46x the AI citation yield of Reddit content (1.93%). Brands should reallocate AI-visibility budgets accordingly.
4. AI Overview CTR Crashed 61% , But the Full Story Is More Subtle
On April 26, Search Engine Journal reported on a Seer Interactive study analyzing 5.47 million queries across 53 brands from September through November 2025. The headline finding: AI Overview click-through rate fell 61% from Q3 to Q4 2025. But the month-by-month breakdown is more complex than the headline suggests.
| Month | AI Overview Impressions | Clicks | CTR |
|---|---|---|---|
| September 2025 | 15.8 million | 398,798 | 2.52% |
| October 2025 | 33.1 million (+109%) | 400,271 (+0.4%) | 1.21% (-52%) |
| November 2025 | 39.5 million (+19%) | 301,783 (-25%) | 0.76% (-37%) |
October's CTR halved , but clicks were flat (+0.4%). The entire CTR decline in October was driven by a 109% explosion in AI Overview impressions, not a click collapse. Google was showing AI Overviews on dramatically more queries, which diluted the CTR mathematically without destroying absolute click volume. As Seer Interactive noted: "October's drop was mostly an impression-growth story, not a click-collapse story."
November is where it gets genuinely concerning. Impressions grew another 19% but clicks actually fell 25% , a real, absolute decline in traffic to publisher sites. The CTR hit 0.76%, meaning fewer than 1 in 130 AI Overview impressions resulted in a click. This aligns with what multiple independent studies have measured:
The one bright spot: pages actually cited within AI Overviews receive 120% more clicks per impression than uncited pages on the same SERP. Being cited in the AI Overview doesn't just preserve your traffic , it amplifies it relative to non-cited competitors. Still, even cited pages lag behind the same pages on SERPs without AI Overviews by approximately 38%.
The 61% CTR decline is real, but it's a composite of two different phenomena: impression dilution (Google showing AIOs on more queries) and genuine click suppression (users getting answers without clicking). For practitioners, the distinction matters. Impression dilution means your content is appearing in more AI Overview contexts , which is actually an opportunity if you tune for AIO citation. Click suppression on informational queries may be permanent, which means shifting toward transactional and navigational content where clicks remain essential.
5. Google's "Bounce Clicks" Defense: Three Appearances, Zero Data

On April 23, 2026, Google's VP of Search Liz Reid told Bloomberg that AI Overviews primarily reduce "bounce clicks" , visits where users quickly return to search without engaging content. Reid characterized this as removing low-quality traffic rather than eliminating genuine visits, claiming users seeking longer reads still click through to publishers.
This is the third time Google has deployed this story. In an August 2025 blog post, Google claimed organic click volume from Search was "relatively stable" year-over-year and that "quality clicks" had increased. In an October 2025 Wall Street Journal interview, Reid explicitly used the phrase "bounced clicks" and asserted ad revenue with AI Overviews remained "relatively stable."
Across all three appearances, Google has provided zero supporting data: no charts, no percentages, no year-over-year comparisons, no methodology for distinguishing bounce clicks from total clicks, and no access to data enabling independent verification. Three times. Nothing.
What Independent Data Actually Shows
| Source | Dataset | Finding |
|---|---|---|
| Chartbeat / Reuters Institute (2026) | 2,500+ publishers globally | Google search referral traffic down ~33%; Discover referrals down 21% YoY |
| Seer Interactive (Q3-Q4 2025) | 5.47M queries, 53 brands | Organic CTR on AIO queries down 61% |
| Pew Research | 68,000 queries | 8% click rate with AIOs vs. 15% without |
| Digital Content Next (2025) | 19 publishers, May-June | Median 10% YoY Google referral decline |
| Ahrefs (2026) | 146 million results | 20.5% AI Overview trigger rate across all queries |
The Chartbeat/Reuters Institute finding is especially damaging to Google's story. A 33% decline in search referral traffic across 2,500+ publishers isn't a "bounce click" phenomenon , it's a fundamental reduction in traffic reaching publisher sites. If Google were correct that only low-quality bounces were removed, engagement metrics on remaining traffic should have improved proportionally. No publisher dataset has shown that pattern.
Google's "bounce clicks" claim may contain a kernel of truth , some AI Overview answers do satisfy trivially informational queries that would have generated quick bounces. But the scale of independent evidence shows traffic declines far exceeding what "bounce removal" could explain. Until Google publishes verifiable data distinguishing bounce clicks from engaged visits, this story should be treated as corporate positioning, not empirical finding. The 33% publisher traffic decline and 21% Discover drop measured by Chartbeat aren't bounce clicks disappearing.
6. Only 4% of the Web Is AI-Agent Ready (Cloudflare Data)

While the SEO industry debates click-through rates, a structural problem is building beneath the surface. On April 17, Cloudflare published its Agent Readiness Score , a plan for measuring how well websites support AI agents , along with data from 200,000 of the most-visited domains. The findings show a massive infrastructure gap between where the web is and where it needs to be.
The Agent Readiness Score evaluates four dimensions: Discoverability (robots.txt, sitemaps, HTTP Link headers), Content (markdown support for agents), Bot Access Control (AI-specific directives using Content Signals), and Capabilities (MCP Server Cards, API catalogs, OAuth discovery, agent skill indexes). While 78% of sites have a robots.txt file, "the vast majority are written for traditional search engine crawlers, not AI agents," according to Cloudflare's analysis. A robots.txt from 2019 isn't AI infrastructure. It's just a file.
The Performance Gap Is Measurable
Cloudflare benchmarked its own documentation , which it optimized for AI agent readability , against unoptimized sites. Results were striking: 31% fewer tokens consumed on average, and 66% faster completion of technical queries when an AI agent (Kimi-k2.5 via OpenCode) answered highly specific questions. The token savings alone translate to real cost reduction for any AI system processing your content at scale.
The optimization techniques include serving every page at an /index.md path for direct markdown access, creating hierarchical llms.txt files that provide structured reading lists for LLMs, removing approximately 450 directory-listing pages that provided "little semantic value," and embedding hidden agent directives in HTML pages that instruct AI systems to request markdown versions instead.
AI Crawler Redirect Data
A companion Cloudflare feature , Redirects for AI Training , revealed concrete data about AI crawler behavior. On Cloudflare's own developer documentation, AI crawlers accessed pages 4.8 million times over 30 days. Legacy documentation alone received 46,000 crawls from OpenAI, 3,600 from Anthropic, and 1,700 from Meta in March 2026. These crawlers were accessing deprecated content despite canonical tags, noindex directives, and deprecation banners , none of which AI training crawlers respect.
Cloudflare's solution converts existing <link rel="canonical"> tags into HTTP 301 redirects for verified AI training crawlers. In the first seven days after deployment, 100% of AI training crawler requests to pages with non-self-referencing canonical tags were successfully redirected away from deprecated content.
If ChatGPT cites search-index pages at 88.5%, and AI crawlers are ingesting 4.8 million pages per month from a single documentation site, then the quality of what those crawlers encounter directly shapes whether your content gets cited. The 96% of websites that haven't declared AI preferences or implemented agent-readable content formats are leaving AI citation outcomes to chance. The Cloudflare data makes the action items concrete: implement llms.txt, serve markdown alternatives, add Content Signal directives, and redirect AI crawlers away from deprecated pages.
7. The Practitioner's Playbook: Optimizing for Both AI Surfaces
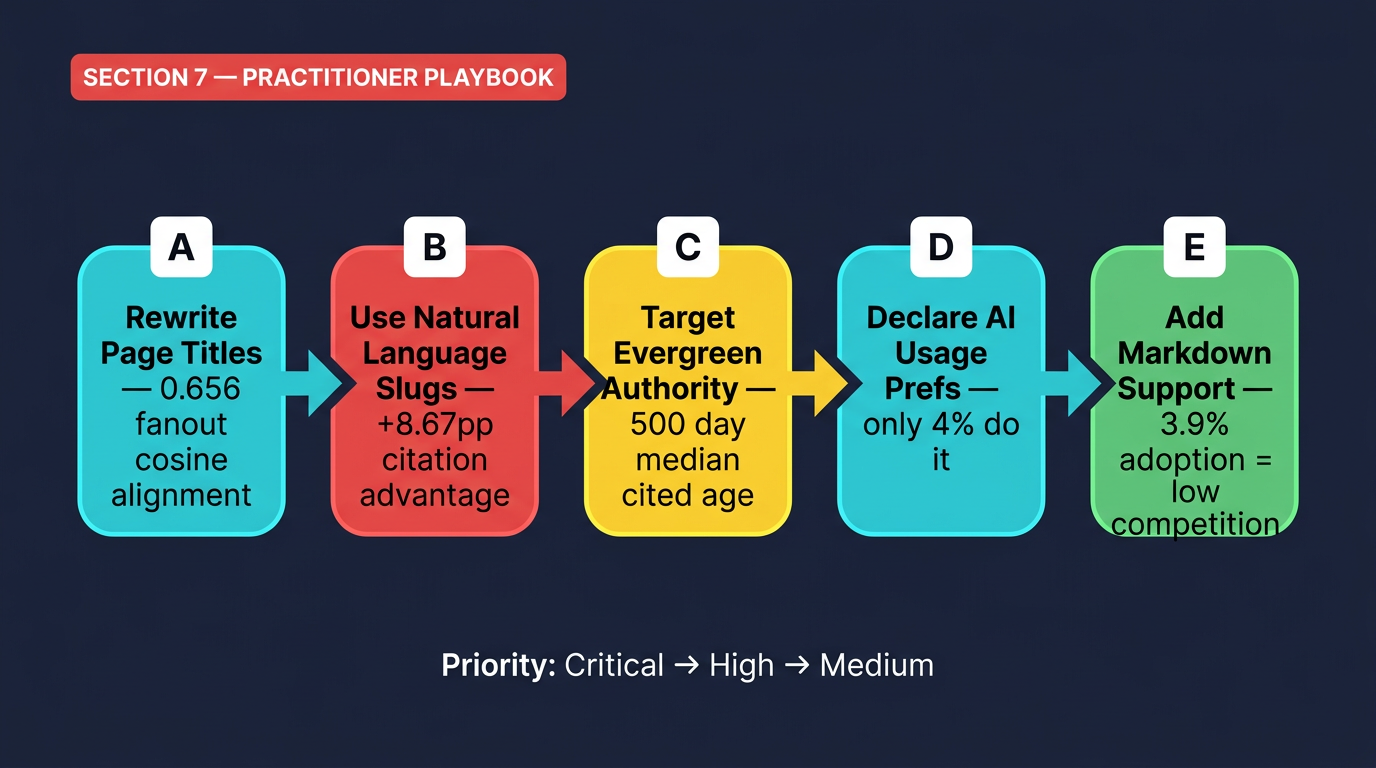
The data from this week tells a coherent story: earning AI citations is highly achievable if you tune for the right signals, and the competitive bar is still remarkably low. Here's a prioritized action plan built from the research.
For ChatGPT Citation Optimization
| Action | Data Support | Priority |
|---|---|---|
| Rewrite page titles for semantic precision , match the sub-questions an AI would generate, not just the user's surface query | 0.656 cosine similarity for fanout query alignment vs. 0.484 for non-cited | Critical |
| Use natural language URL slugs (descriptive, readable paths) | 89.78% citation rate vs. 81.11% for opaque slugs | High |
| Focus on search-index visibility over Reddit/YouTube/social presence | 88.5% citation rate for search vs. 1.93% for Reddit | Critical |
| For evergreen content, prioritize depth over freshness | Median cited page age: 500 days; oldest cited pages: 2,700+ days | Medium |
| For news content, publish and update within 200-day freshness window | Cited news median age: 200 days vs. 300 for non-cited | Medium |
For AI Overview Survival
| Action | Data Support | Priority |
|---|---|---|
| Pursue AIO citation , cited pages get 120% more clicks than uncited pages on the same SERP | Seer Interactive: cited vs. uncited click differential | Critical |
| Shift informational content toward mid-funnel/transactional intent where AI Overviews suppress fewer clicks | 61% CTR decline concentrated on informational queries | High |
| Monitor organic CTR trends monthly , the Feb 2026 rebound to 2.4% suggests CTR is not permanently at 0.76% | Seer data: CTR recovered from 1.3% (Dec) to 2.4% (Feb) | Medium |
| Build direct traffic channels (email, social, community) as hedge against search referral decline | Chartbeat: 33% publisher traffic decline; Discover down 21% | High |
For AI Infrastructure Readiness
| Action | Data Support | Priority |
|---|---|---|
Create an llms.txt file at site root with structured content hierarchy | Only 4% of sites have declared AI preferences , massive first-mover opportunity | High |
Serve markdown alternatives at /index.md paths or via Accept header | 3.9% adoption; 31% token reduction + 66% faster AI query completion | Medium |
| Add Content Signal directives for AI training/input preferences | 4% adoption across 200K top domains | Medium |
| Redirect AI crawlers away from deprecated/legacy content using canonical-based 301s | Cloudflare: 46K GPTBot crawls on legacy pages in one month | High |
Frequently Asked Questions
What percentage of ChatGPT search results get cited in responses?
According to an Ahrefs study of 1.4 million ChatGPT prompts, pages from the general search index are cited at an 88.46% rate. But this varies dramatically by source type: news articles are cited at 12.01%, Reddit posts at just 1.93%, YouTube at 0.51%, and academic sources at 0.40%. The overall citation rate across all retrieved URLs is approximately 50%, though this average is heavily skewed by Reddit's massive volume of uncited retrievals.
How much did AI Overview click-through rates drop in late 2025?
AI Overview CTR fell 61% from Q3 to Q4 2025, according to a Seer Interactive study of 5.47 million queries across 53 brands. CTR dropped from 2.52% in September to 0.76% in November 2025. Much of this decline was driven by a 150% explosion in AI Overview impressions rather than a proportional collapse in clicks , October's click volume was actually flat compared to September despite the CTR halving.
What is the strongest signal for getting cited by ChatGPT?
Semantic alignment between your page title and ChatGPT's internal "fanout queries" is the strongest citation signal. ChatGPT generates sub-questions when processing a prompt, and the cosine similarity between these fanout queries and cited page titles averaged 0.656, compared to 0.484 for non-cited pages. Optimizing for the specific sub-questions ChatGPT generates , not just the surface-level user prompt , is the most impactful strategy for earning AI citations.
What are Google's "bounce clicks" and is the explanation credible?
Google's Liz Reid characterized removed clicks as "bounce clicks" , visits where users quickly return to search without engaging content. She claims AI Overviews primarily reduce these low-quality visits while preserving deeper engagement. But across three public appearances (August 2025, October 2025, April 2026), Google has provided zero supporting data: no charts, percentages, or year-over-year comparisons. Independent research from Chartbeat/Reuters Institute shows a 33% drop in publisher Google search traffic and a 21% decline in Discover referrals, contradicting the "just bounce clicks" story.
What is Cloudflare's Agent Readiness Score and what does it measure?
Cloudflare's Agent Readiness Score evaluates how well websites support AI agents across four dimensions: Discoverability (robots.txt, sitemaps, Link headers), Content (markdown support for agents), Bot Access Control (AI-specific directives, Web Bot Auth), and Capabilities (MCP Server Cards, API catalogs, OAuth discovery). Analysis of 200,000 top domains found that while 78% have a robots.txt, only 4% declared AI usage preferences, 3.9% support markdown content negotiation, and fewer than 15 sites in the entire dataset had MCP Server Cards or API catalogs.
Why does Reddit have such a low ChatGPT citation rate despite being frequently retrieved?
Reddit accounts for over 16 million retrieved URLs in Ahrefs' dataset , the largest single source , but is cited only 1.93% of the time, making it 67.8% of all non-cited URLs. ChatGPT retrieves Reddit posts as supplementary context during its research phase but in the end prefers to cite more authoritative, structured sources when generating responses. Reddit content functions as background research material rather than citable authority, which has significant implications for brands investing in Reddit SEO strategies.
How does page age affect ChatGPT citation likelihood?
For general search content, the median age of cited pages is approximately 500 days (about 1.3 years), with some cited pages over 2,700 days old (7.4 years). Established, authoritative content keeps earning citations even without being fresh. For news content, freshness matters significantly more: cited news articles have a median age of about 200 days versus 300 days for non-cited news. Evergreen content should prioritize depth and authority over recency; news content must stay current to remain citable.
Sources
- Ahrefs , Why ChatGPT Cites One Page Over Another (Study of 1.4M Prompts) , April 15, 2026
- Search Engine Journal , AI Overview CTR Fell 61%, But Clicks Didn't Collapse , April 26, 2026
- Search Engine Journal , Google Pushes "Bounce Clicks" Explanation For AI Overview Traffic Loss , April 25, 2026
- Cloudflare , Introducing the Agent Readiness Score , April 17, 2026
- Cloudflare , Redirects for AI Training Enforces Canonical Content , April 17, 2026
- Cloudflare , Moving Past Bots vs. Humans , April 21, 2026
About the Author
