
Only 4% of Websites Are Ready for AI Agents: Cloudflare Data, OAI-AdsBot, and the Robots.txt Shakeup (April 2026)
Cloudflare's Agent Readiness Score reveals only 4% of 200K top domains declare AI usage preferences. OpenAI adds OAI-AdsBot with no published IP ranges, and Google audits unsupported robots.txt directives. Here's what technical SEO teams need to do this week.

Only 4% of Websites Are Ready for AI Agents: Cloudflare Data Exposes a Massive Readiness Gap
Cloudflare analyzed 200,000 top domains. OpenAI launched a new ad-validation crawler. Google is rethinking robots.txt documentation. The web's relationship with AI bots is being rewritten — and most sites aren't keeping up.
Key Takeaways

- Cloudflare's Agent Readiness Score shows only 4% of the top 200K domains declare AI usage preferences
- Fewer than 15 sites in Cloudflare's dataset have MCP Server Cards or API Catalogs
- OpenAI's new OAI-AdsBot crawls ChatGPT ad landing pages — but has no published IP ranges yet
- Google is using HTTP Archive data to document the top 10-15 unsupported robots.txt rules
- Cloudflare proposes anonymous credentials to replace the binary bots-vs-humans detection model
- Sites optimized for AI agents see 31% fewer tokens consumed and 66% faster responses
1. Cloudflare's Agent Readiness Score: The Data Nobody Expected

On April 17, Cloudflare introduced the Agent Readiness Score , a diagnostic tool that measures how prepared a website is for the emerging wave of AI agents. Unlike vague "AI-ready" checklists, this score is built on concrete standards and backed by an analysis of 200,000 of the most-visited domains on the internet.
The results paint a stark picture of where the web actually stands.
(most written for search engines, not AI)
The score evaluates four dimensions, each targeting a different facet of agent interaction:
| Dimension | What It Checks | Standards Involved |
|---|---|---|
| Discoverability | Can agents find and understand your site structure? | robots.txt, sitemap.xml, Link Headers (RFC 8288) |
| Content | Can agents consume your content efficiently? | Markdown for Agents support |
| Bot Access Control | Have you declared preferences for AI usage? | Content Signals, AI bot rules, Web Bot Auth |
| Capabilities | Can agents take actions or use your services? | Agent Skills, API Catalog (RFC 9727), OAuth discovery, MCP Server Card, WebMCP |
The scoring tool also produces actionable feedback designed for coding agents to implement fixes , meaning you can feed your Agent Readiness report directly into Claude, Cursor, or similar tools and get implementation patches.
2. Why 78% Having Robots.txt Doesn't Mean What You Think
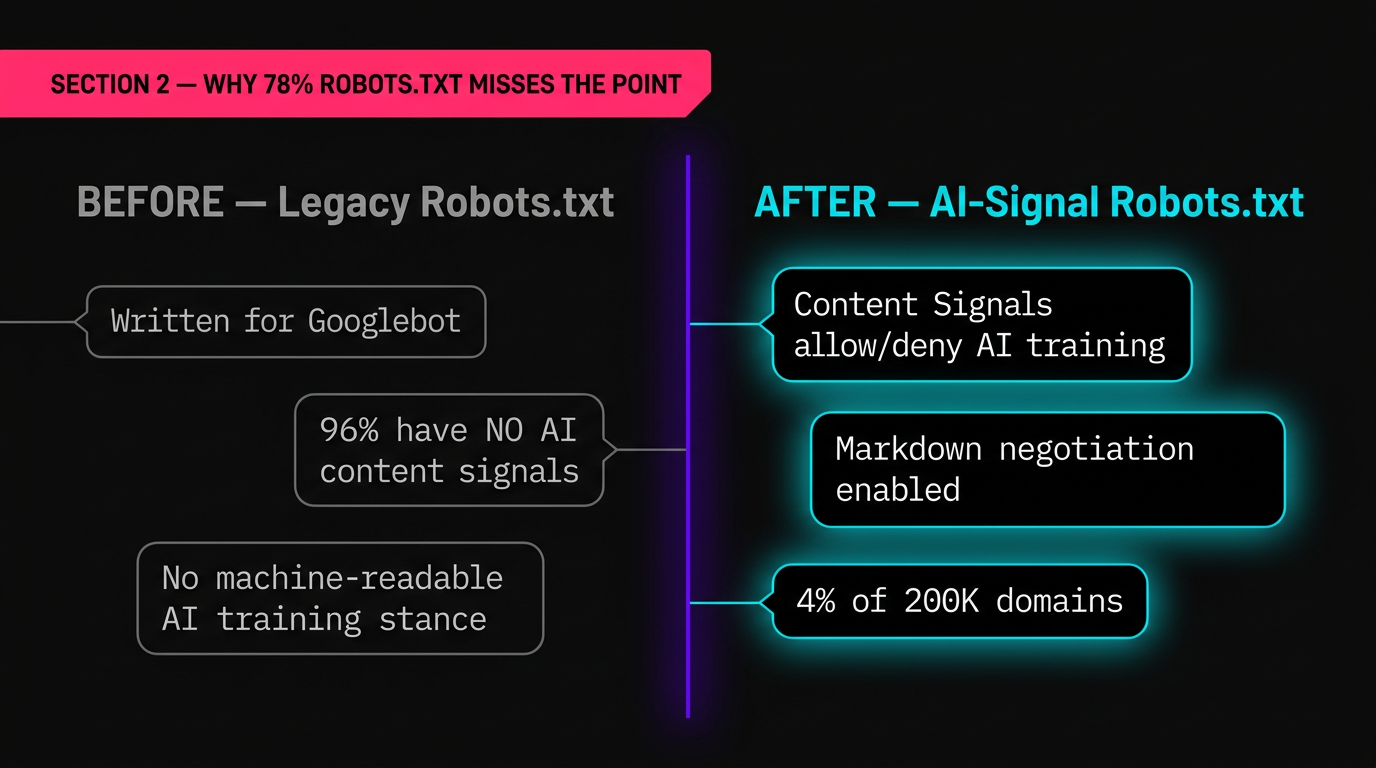
The headline number , 78% of top sites have robots.txt , sounds healthy until you examine what those files actually contain. The vast majority were written years ago for Googlebot and Bingbot. They don't address the new generation of AI crawlers at all.
The critical gap is in Content Signals: explicit declarations in robots.txt about how AI systems may use your content. Only 4% of the 200,000 analyzed domains include these signals. That means 96% of major websites have no machine-readable statement about whether AI agents can train on their content, summarize it, or quote it.
The Practical Difference
A traditional robots.txt typically handles access , can you crawl this page or not? Content Signals handle usage , what can you do with the content once you've accessed it? This is the distinction that matters as AI agents move from crawling to acting on web content.
# Traditional robots.txt (access only)
User-agent: GPTBot
Disallow: /private/ # With Content Signals (access + usage preferences)
User-agent: GPTBot
Disallow: /private/ # Content Signals
# ai-usage: no-training
# ai-usage: allow-summary
# ai-usage: allow-citation3. OpenAI's OAI-AdsBot: A New Crawler Enters the Arena
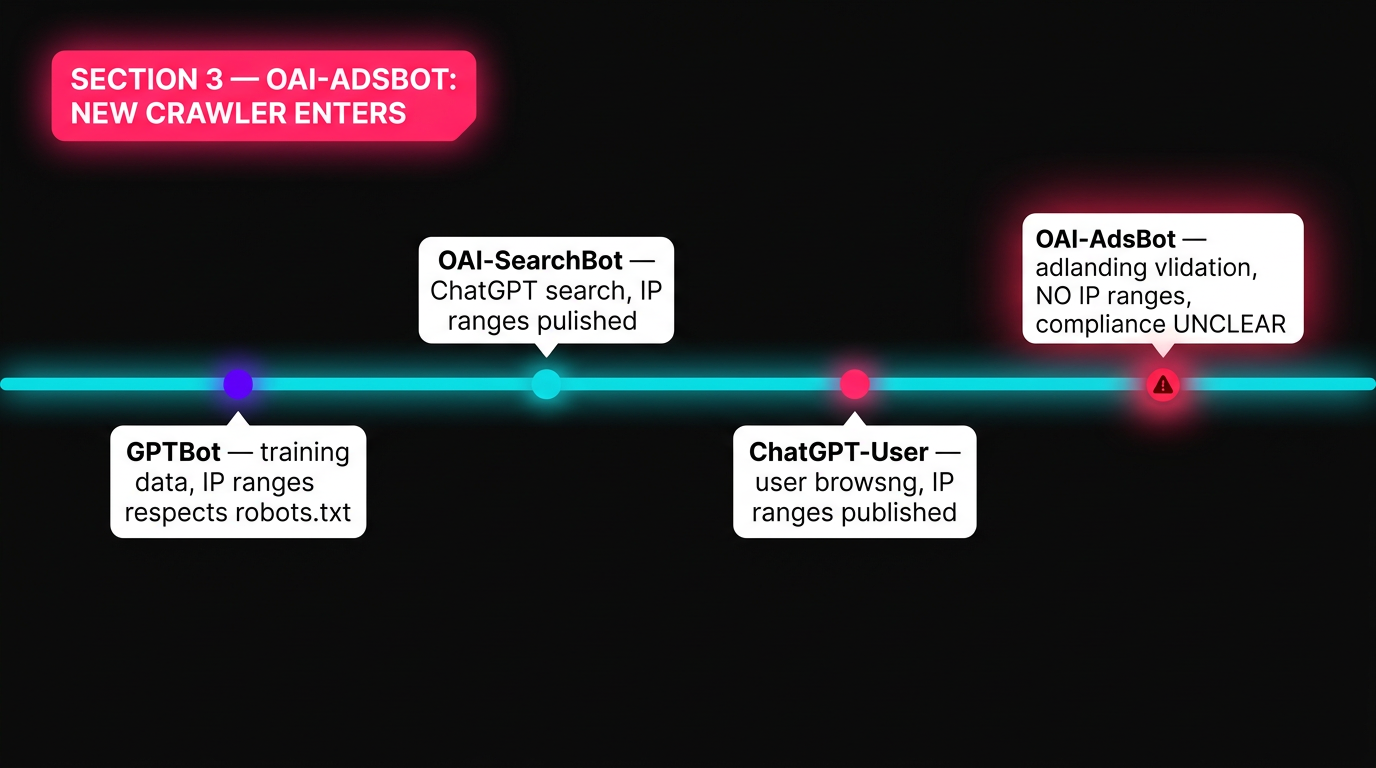
OpenAI's crawler documentation now lists four distinct bots. The newest addition , OAI-AdsBot , serves a different purpose from the others. It doesn't crawl the open web. It validates landing pages submitted through ChatGPT's advertising platform.
| Bot | Purpose | Respects robots.txt? | IP Ranges Published? |
|---|---|---|---|
| GPTBot | Training data collection | Yes | Yes (.json) |
| OAI-SearchBot | ChatGPT search results | Yes | Yes (.json) |
| ChatGPT-User | User-initiated browsing | Yes | Yes (.json) |
| OAI-AdsBot | Ad landing page validation | Unclear | No |
OAI-AdsBot performs two functions when an advertiser submits a landing page:
- Policy compliance checking , verifying the page meets OpenAI's advertising standards
- Content analysis , evaluating the page to determine optimal ad timing and audience targeting for ChatGPT users
Its user-agent string is:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, like Gecko); compatible; OAI-AdsBot/1.0What This Means for Advertisers
If you're running or planning ChatGPT ad campaigns, your landing pages need to be accessible to OAI-AdsBot. Aggressive bot-blocking setups (Cloudflare Bot Management, Akamai Bot Manager, custom WAF rules) may inadvertently block ad validation, preventing your campaigns from launching.
OpenAI explicitly states that data collected by OAI-AdsBot is not used to train generative AI models , a critical distinction from GPTBot's data usage.
4. Google's Robots.txt Documentation Expansion: What's Actually Changing
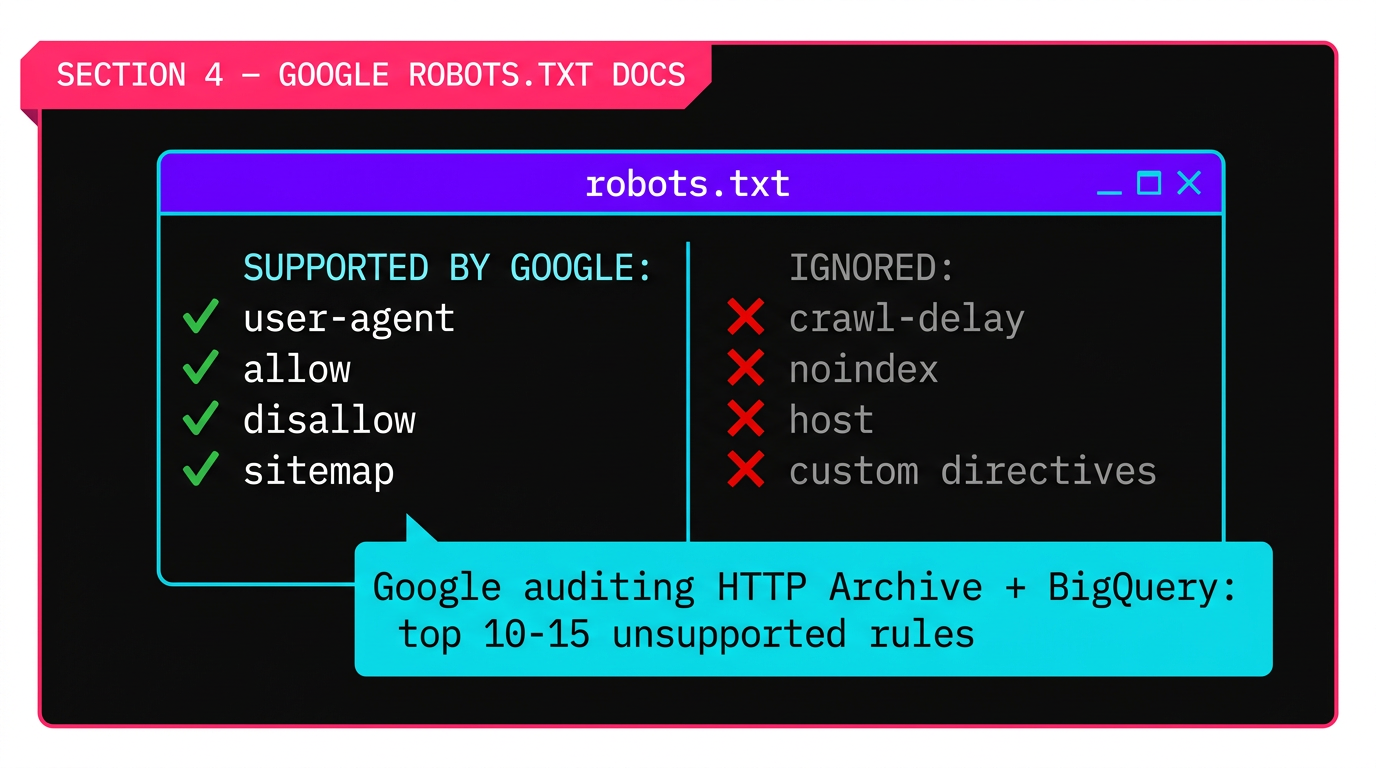
In a separate but related development, Google signaled it may expand its documentation of unsupported robots.txt directives. This is a documentation change, not a functionality change , but it matters more than it sounds.
Google currently supports exactly four robots.txt fields:
Everything else , crawl-delay, noindex, host, custom directives , is ignored by Google. But many site operators don't know that. Google's data research reveals the scale of the confusion.
The Research Methodology
Rather than guessing which unsupported rules to document, Google used HTTP Archive data queried via BigQuery. They built a custom JavaScript parser to extract robots.txt rules from the archive (standard web crawls don't typically capture these files). Their finding: "After allow and disallow and user agent, the drop is extremely drastic."
The goal is to identify the top 10-15 most-used unsupported directives and formally document that Google ignores them. Gary Illyes also indicated Google may expand typo tolerance , accepting more common misspellings of supported directives , though no specifics or timeline were given.
crawl-delay, noindex, host, or any non-standard directive expecting Google to honor it , it doesn't. These rules may work with other crawlers (Bing honors crawl-delay, for example) but have never influenced Googlebot's behavior. 5. The Model Shift: From "Bots vs. Humans" to Intent-Based Signals
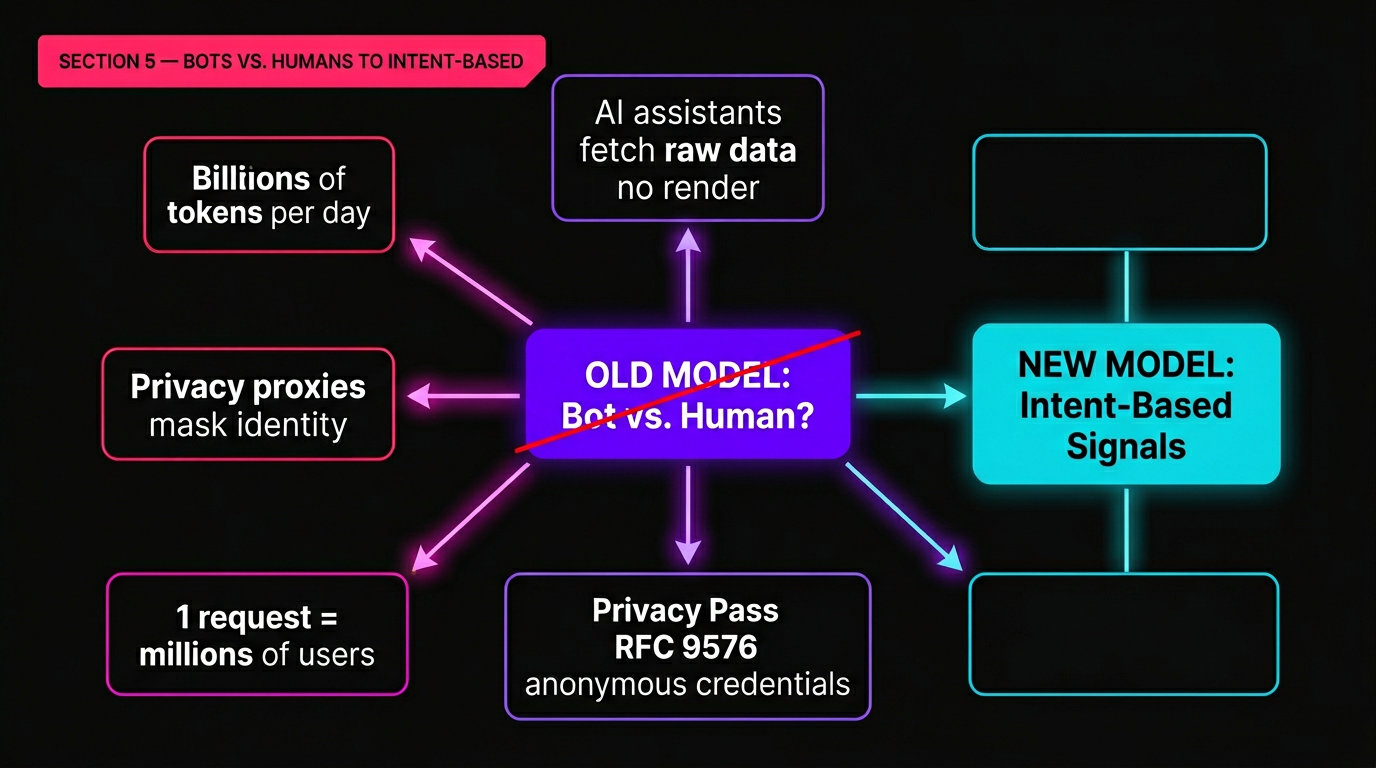
Cloudflare's April 21 post, "Moving past bots vs. humans," argues that the entire plan for bot management is obsolete. The binary question , is this request from a bot or a human? , no longer captures what actually matters.
AI assistants fetch raw data without rendering pages. Privacy proxies mask user identity. The same HTTP request might serve one private report or train a model on behalf of millions of users. The old taxonomy breaks down.
Anonymous Credentials: The Proposed Replacement
Cloudflare's proposed solution is built on Privacy Pass standards (RFC 9576, RFC 9578), using cryptographic primitives (VOPRF and BlindRSA) to create a new trust layer. The core mechanism:
- Tokens prove attributes, not identity , a client can demonstrate "I have a good history with this service" without revealing "I am this specific user"
- Tokens are unlinkable , they cannot be correlated across sessions, preventing tracking
- Already at scale , Privacy Pass tokens process billions per day across Cloudflare's infrastructure
The Rate Limit Trilemma
Cloudflare identifies a fundamental constraint in bot management: decentralization, anonymity, and accountability , pick two. Current systems generally achieve the first two while sacrificing accountability. New standards under IETF development attempt to balance all three:
| Standard | Status | What It Enables |
|---|---|---|
| Anonymous Rate-Limit Credentials (ARC) | IETF development | Rate-limit clients without identifying them |
| Anonymous Credit Tokens (ACT) | IETF development | Metered access with privacy preservation |
| Privacy Pass (RFC 9576/9578) | Production (billions/day) | Prove challenge completion without cookies |
6. The Emerging AI Bot System: A Complete Map
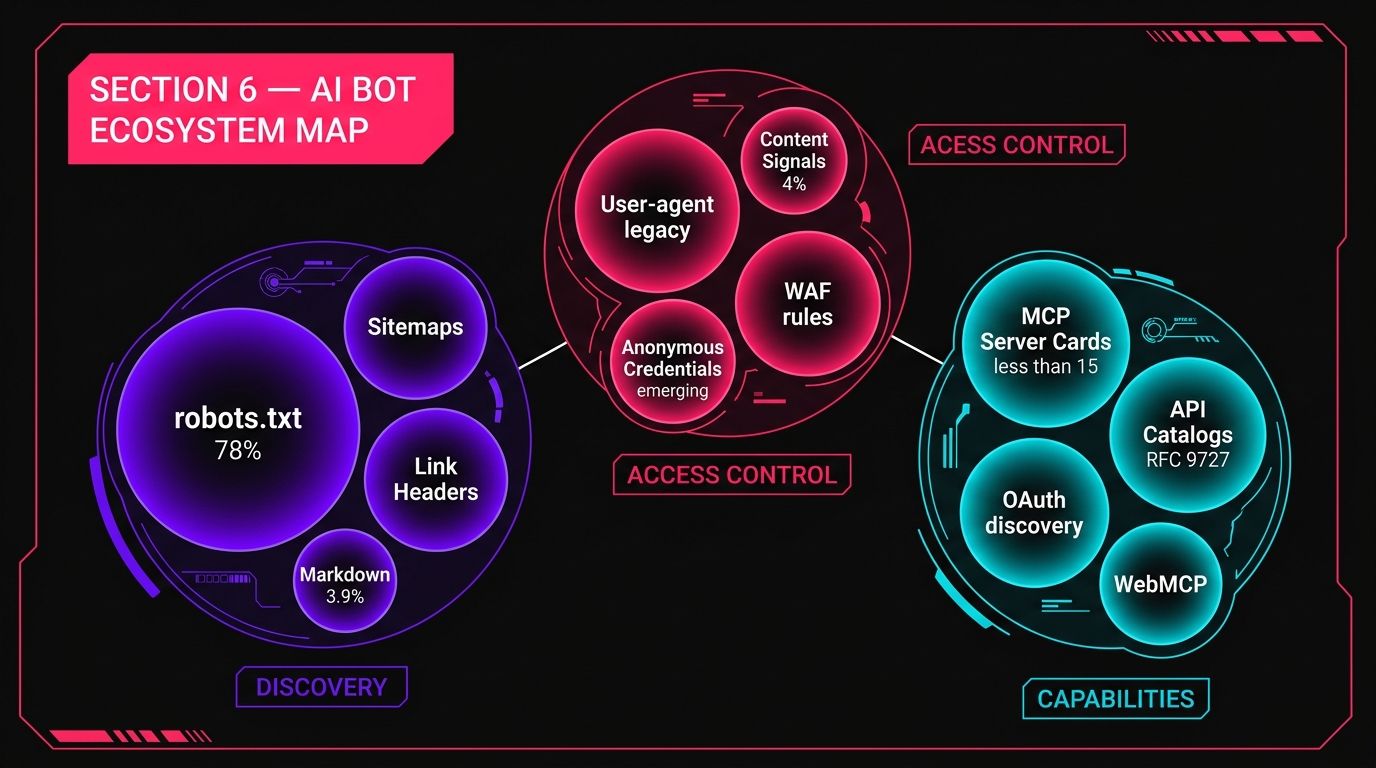
Between OpenAI's expanding bot fleet, Cloudflare's new standards, and Google's robots.txt audit, we're seeing the formation of a three-layer architecture for AI-web interaction:
| Layer | Function | Current State |
|---|---|---|
| Discovery | How agents find and understand site structure | robots.txt + sitemaps (78% adoption); Link Headers and Markdown (under 4%) |
| Access Control | Who can crawl what, and what they can do with it | User-agent matching (legacy); Content Signals (4%); Anonymous credentials (emerging) |
| Capabilities | What actions agents can take on your site | MCP Server Cards (<15 sites); API Catalogs (RFC 9727, near-zero); WebMCP (experimental) |
The data tells a clear story: the Discovery layer is mature but misaligned (built for search engines, not AI agents). The Access Control layer is undergoing a fundamental rethink. The Capabilities layer barely exists outside of a handful of early adopters.
What To Prioritize Now
Not everything needs immediate action. Here's a prioritized implementation order based on the data:
- Content Signals in robots.txt , Lowest effort, highest impact. Declare your AI usage preferences. (Currently: 4% adoption)
- Markdown content negotiation , Moderate effort, measurable payoff. 31% token reduction for AI consumers. (Currently: 3.9%)
- Robots.txt audit , Remove unsupported directives you thought were working. Takes 15 minutes.
- OAI-AdsBot handling , If running ChatGPT ads, ensure landing pages are accessible. Check WAF rules.
- MCP Server Card / API Catalog , Only if you offer structured services or APIs. The standard is still extremely early. (<15 sites)
7. What Changes For Technical SEO Teams This Week

These developments translate into concrete tasks for technical SEO professionals:
Immediate (This Week)
- Run the Agent Readiness check on your top domains. Document your baseline score.
- Audit robots.txt for non-standard directives (crawl-delay, noindex, host) that Google has never honored.
- Check server logs for OAI-AdsBot traffic if you're running or considering ChatGPT ads.
- Review WAF/bot management rules to ensure they don't block legitimate AI bot validation.
Short-Term (Next 30 Days)
- Add Content Signals to robots.txt declaring your AI usage preferences.
- Implement Markdown content negotiation for high-value content pages and documentation.
- Create an AI crawler monitoring dashboard tracking GPTBot, OAI-SearchBot, ChatGPT-User, OAI-AdsBot, ClaudeBot, and others.
Watch List
- Anonymous credentials adoption , Cloudflare's Privacy Pass is live, but ARC and ACT are still in IETF development.
- Google's robots.txt documentation update , The top 10-15 unsupported directives list hasn't been published yet.
- OAI-AdsBot IP ranges , OpenAI hasn't published a JSON file yet. Monitor their crawler documentation for updates.
Frequently Asked Questions
It's a diagnostic tool that evaluates websites across four dimensions: Discoverability (robots.txt, sitemaps, Link headers per RFC 8288), Content (Markdown for Agents support), Bot Access Control (Content Signals, AI bot rules, Web Bot Auth), and Capabilities (Agent Skills, API Catalog via RFC 9727, OAuth discovery, MCP Server Card, WebMCP). The tool provides a numerical score plus individual pass/fail checks, and generates actionable feedback that coding agents can implement directly.
Based on Cloudflare's analysis of 200,000 most-visited domains: only 4% declare AI usage preferences via Content Signals. While 78% have robots.txt, most files were written for traditional search engines. Only 3.9% support Markdown content negotiation. Fewer than 15 sites in the entire 200K dataset have MCP Server Cards or API Catalogs , the infrastructure needed for agents to take actions on a site.
OAI-AdsBot is OpenAI's new crawler for validating ChatGPT ad landing pages. Unlike GPTBot (which crawls the open web for training data), OAI-AdsBot only visits pages submitted as ad destinations. It checks policy compliance and analyzes content for ad targeting. Critically, data collected by OAI-AdsBot is not used to train AI models. However, it currently has no published IP ranges and it's unclear whether it respects robots.txt.
This is currently a gap in OpenAI's documentation. While GPTBot and OAI-SearchBot respect robots.txt, OpenAI hasn't specified whether OAI-AdsBot does. No IP range JSON file exists for verification. If you run ChatGPT ads, blocking this bot may prevent ad validation. Advertisers should whitelist the user-agent OAI-AdsBot/1.0 on ad landing pages. For non-advertisers, monitor logs for the user-agent string and consider contacting OpenAI for IP range documentation.
No. Google is expanding documentation, not functionality. Google still only supports four directives: user-agent, allow, disallow, and sitemap. The change is that Google is using HTTP Archive/BigQuery data to identify the top 10-15 most-used unsupported directives and will formally document that they're ignored. Gary Illyes also hinted at expanding typo tolerance for supported directives. This is a clarity update, not a technical change.
Anonymous credentials are privacy-preserving tokens (built on Privacy Pass RFC 9576/9578) that let clients prove attributes ("I have good history") without revealing identity. Cloudflare processes billions of these daily. For SEO, this matters because it could replace user-agent string matching as the primary bot identification method. Instead of blocking by bot name, sites would verify capabilities and authorization , shifting bot management from identity to intent. New IETF standards (ARC, ACT) are extending this to rate limiting and metered access.
Based on the data, prioritize in this order: (1) Add Content Signals to robots.txt declaring AI usage preferences , only 4% of sites do this. (2) Implement Markdown content negotiation , sites that do this see 31% fewer tokens consumed and 66% faster AI responses. (3) Audit robots.txt for non-standard directives (crawl-delay, noindex, host) that Google ignores. (4) If running ChatGPT ads, ensure landing pages are accessible to OAI-AdsBot. (5) Consider MCP Server Cards or API Catalogs only if you offer structured services , the system is extremely early (fewer than 15 sites).
Listen to this article
NotebookLM audio overview will be added here.
Sources
- Cloudflare , "Introducing the Agent Readiness score. Is your site agent-ready?" (April 17, 2026)
https://blog.cloudflare.com/agent-readiness/ - Cloudflare , "Moving past bots vs. humans" (April 21, 2026)
https://blog.cloudflare.com/past-bots-and-humans/ - Search Engine Journal , "OpenAI's Crawler Docs Now List OAI-AdsBot For ChatGPT Ads" (April 23, 2026)
https://www.searchenginejournal.com/openais-crawler-docs-now-list-oai-adsbot-for-chatgpt-ads/549980/ - Search Engine Journal , "Google May Expand Unsupported Robots.txt Rules List" (April 23, 2026)
https://www.searchenginejournal.com/google-may-expand-unsupported-robots-txt-rules-list/549944/ - Cloudflare , "Building the agentic cloud: everything we launched during Agents Week 2026" (April 20, 2026)
https://blog.cloudflare.com/agents-week-in-review/
About the Author
