
AI Visibility Tools Are Selling Certainty They Cannot Measure
Prompt trackers can reveal AI visibility patterns, but they cannot replicate real user answers. Here is how to evaluate AI visibility tools, what the evidence says, and how to build a transparent DataForSEO or SerpApi audit workflow.
AI Visibility Tools Are Selling Certainty They Cannot Measure
TL;DR: AI visibility tools and prompt trackers can be useful as weak directional instruments, but they cannot precisely measure how real users see your brand inside ChatGPT, Perplexity, Copilot, Gemini, AI Overviews, or AI Mode. The strongest use case is topic-gap discovery at scale, not "ranking position" reports for a few synthetic prompts.
What you will learn:
- Why AI visibility is not equivalent to rank tracking.
- What the research says about LLM inconsistency, API-vs-interface gaps, and Google AI citation behavior.
- How to evaluate vendors without buying false certainty.
- How to build a transparent mini prompt-audit tool with DataForSEO or SerpApi.
5-Minute AI Visibility Measurement Breakdown
Watch why AI visibility dashboards are directional evidence, not rank tracking
A practical walkthrough of prompt tracker limits, API-vs-interface gaps, Google AI query fan-out, and the evidence trail SEOs should keep.
The market for AI visibility tracking is growing because marketers want the one thing generative search refuses to provide: certainty. A dashboard that says your brand is 43% visible in ChatGPT feels comforting. A line chart that shows your "AI share of voice" rising feels like control. A table that claims you rank third in AI answers looks familiar enough to get a budget approved.
That familiarity is the problem. AI answers are not search results pages. They are probabilistic outputs shaped by model version, retrieval path, prompt wording, session context, language, location, memory, subscription tier, private connectors, and sometimes tools the user has installed. A prompt tracker that runs 50 clean prompts from a neutral session is not measuring what your buyers experience. It is sampling one artificial slice of a much larger answer space.
My view is simple: prompt trackers are not useless, but most are sold with far more confidence than the evidence supports. The useful question is not "What is our exact AI visibility score?" The useful question is "What weak signals can we collect repeatedly enough to find topic gaps, source gaps, and brand mention patterns worth investigating?"
This article is the practical version of that argument. If you want the measurement side of AI search, read it with our breakdown of the GEO attribution crisis. If you want the optimization side, pair it with our guide to Google's AI search guidance.

What AI Visibility Trackers Actually Measure
AI visibility is usually defined as how often, how prominently, and in what sentiment a brand appears in generated answers for prompts related to its market. Prompt trackers operationalize that by executing predefined prompts against AI systems, then counting mentions, citations, competitor references, and sometimes apparent position.
That sounds reasonable until you inspect the assumptions. Most trackers assume that a list of prompts can represent real user demand, that a clean session can represent a personalized user environment, and that repeated outputs are stable enough to score. Those assumptions are weak.
A traditional rank tracker measures a rendered result for a keyword, location, device, and time. It still has variance, but the object being measured is a results page. An AI tracker measures a generated answer from a system that may decide to search, not search, rewrite the query, retrieve from different sources, use hidden context, or produce a slightly different answer for no obvious external reason.
The Evidence Says AI Recommendations Are Unstable
The strongest public evidence comes from SparkToro's 2026 research on brand and product recommendations. Across 600 volunteers, 12 recommendation prompts, and 2,961 runs in ChatGPT, Claude, and Google AI, SparkToro found less than a 1 in 100 chance of receiving the same brand list twice, and around a 1 in 1,000 chance of receiving the same list in the same order. That is not a ranking environment. That is a statistical lottery with a few recurring favorites.
Rand Fishkin's practical point is that exact rankings are mostly nonsense, but aggregate appearance percentage can be more defensible. If a brand appears in 97% of repeated answers for a narrow category, that signal is real enough to investigate. If it appears in 3 of 25 prompts once a day, you probably have random variation wearing a badge.
This matches the academic direction. Research on LLM non-determinism has shown that models can vary even under settings that many practitioners assume are deterministic. Another study on consistency found that more advanced models are not necessarily more repeatable. Anthropic's work on statistical evaluation also matters here: related prompts are not independent observations. If thirty CRM prompts are semantically similar, they may behave like far fewer independent data points.
That is the first methodological trap. A vendor may say it tracks 100 prompts. If those prompts are variations of the same buying question, the effective sample size is much smaller. You do not have 100 independent windows into AI visibility. You may have a handful of correlated windows with nice labels.
API Results Do Not Match Real AI Interfaces
The second trap is access method. Many tools use APIs because APIs are cheaper, easier to scale, and easier to normalize. But API answers are not the same thing as the logged-in web products people use.
Surfer SEO's December 2025 study compared API outputs with scraped interface outputs for AI search tools. The gap was large enough to undermine API-based visibility claims. For ChatGPT, the study reported low overlap in brands and sources between API and scraped outputs. For Perplexity, source overlap was only 8%. That means a tool using an API as a proxy for the real interface can miss brands, miss citations, and misread the answer environment.
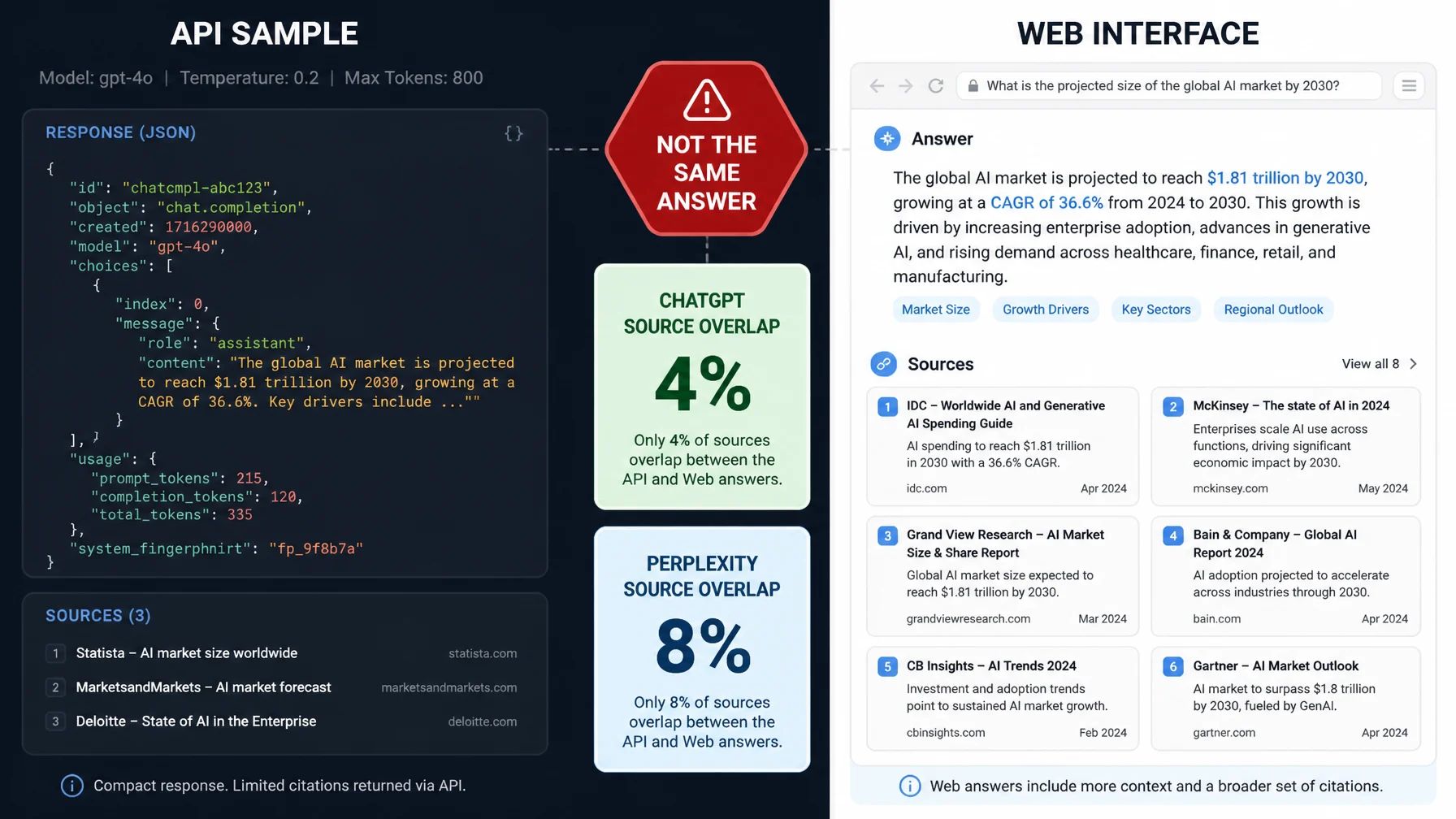
This does not mean APIs are worthless. It means API-based monitoring must be described honestly: controlled simulation, not real-user measurement. That distinction matters when a tool promises board-level reporting.
Scraping public interfaces can be closer to the user experience, but it creates its own problems: account state, rate limits, terms of service, geography, personalization, and changing UI behavior. The better vendors document their method. The weaker ones hide behind a generic "AI visibility score."
Google AI Search Is Not Your Literal Prompt
Google AI Overviews and AI Mode add a deeper problem: the visible query is not the only query. Google's generative search systems can use query fan-out, retrieval, reranking, clustering, and synthesis. A user asks one question. The system may generate many related internal queries, retrieve from pages that do not rank for the original query, and cite a source because it answered one of those hidden subquestions.
Ahrefs analyzed 863,000 SERPs and 4 million AI Overview citation URLs and found that only 37.9% of AI Overview cited pages also ranked in the top 10 organic results for the same query. Another 31.2% came from positions 11 to 100, and 31.0% came from beyond the top 100. That is a massive reminder that AI citations are not just top-10 rankings with a new wrapper.
For SEO, this is important and annoying in equal measure. It means your content can earn citations without ranking top 10 for the original query. It also means a prompt tracker that only launches the visible prompt from outside Google cannot know the internal fan-out path that caused a citation.

This is why our work on AI citation ranking factors focuses on crawlability, answer fit, source clarity, entity strength, and content quality rather than magic prompt phrases. It also explains why YouTube and third-party mentions can matter. In AI Overviews, citations can come from pages or videos that sit outside the exact organic result set a keyword tool shows you. Our analysis of YouTube brand mentions and AI citations covers that angle in more detail.
You Cannot Replicate the Real User Context
A clean prompt-tracking session has no memory, no buyer history, no private files, no email context, no calendar, no CRM, no saved preferences, and often no subscription-specific behavior. Real AI usage increasingly has all of those things.
ChatGPT uses memory and chat history when available. Claude and ChatGPT can connect tools and data sources. Google is moving Gemini deeper into Gmail, Drive, Calendar, Photos, YouTube, and Search history. Microsoft has first-party visibility into Copilot and Bing experiences that no external tracker can reproduce. Once users connect private data, the answer is not only about the web. It is about the web plus the user's context.
There is also the retrieval-vs-memory distinction. If a model recommends your brand from parametric knowledge, you cannot optimize that result next week with a new blog post. If it recommends your brand after web retrieval, content, digital PR, citations, and third-party coverage can influence future answers. Most tools do not tell you which path produced the mention. That makes the metric less actionable.
When a tool says, "You are visible in 12% of prompts," the next question should be: visible where, from what retrieval path, in what interface, under what session state, with what model version, and against what real demand sample?
How to Evaluate AI Visibility Tools
You can still buy an AI visibility tool. Just do it with the right skepticism. The evaluation criteria are more important than the score.
| Question | Why it matters | What a good answer sounds like |
|---|---|---|
| Where do prompts come from? | Synthetic prompts copy what you think users ask, not necessarily what they ask. | Prompts are derived from demand signals, clustered by topic, and documented. |
| How many repeated runs per prompt? | One run per prompt is too noisy for recommendation-style answers. | The tool supports repeated runs and reports confidence or volatility. |
| API or real interface? | API outputs can diverge sharply from user-facing products. | The method is disclosed and limitations are stated plainly. |
| Which model versions? | Models change, and newer models may be less consistent. | Model names, update cadence, and historical breaks are visible. |
| How are entities disambiguated? | Brand string matching creates false positives for names like Apple, Corona, or Stradivarius. | The vendor uses contextual entity matching, not only substring search. |
| Do citations mean visible links? | Grounding URLs and visible citations are not the same thing. | The tool separates visible citations from internal or hidden source use where possible. |
The large-suite tools have an advantage because they can operate at scale. SISTRIX says its AI/Chatbot Research Tool uses 10 million prompts per language across five languages. Ahrefs Brand Radar connects AI visibility with its keyword and web graph data. Semrush says its AI Visibility data spans hundreds of millions of prompts and responses. Those numbers do not make the scores absolute, but they make topic-level patterns more useful than a tiny bespoke tracker with 25 prompts.
Small trackers can still be useful for stakeholder reporting, weekly monitoring of a handpicked prompt set, and quick competitor snapshots. Just do not confuse that with market measurement. A 50-prompt custom tracker is closer to a lab notebook than a Search Console report.
First-Party Data Is the Real Prize
The most interesting development is not another third-party tracker. It is first-party AI reporting. Bing Webmaster Tools has started exposing AI Performance data, including cited pages and grounding queries for Copilot and Bing AI. That matters because it comes from the system itself, not from an external simulation.
First-party AI visibility data solves several problems at once. It measures the model users actually see. It avoids the API-vs-interface proxy problem. It captures real retrieval and real visible citations. It still has limits, of course. It covers only Microsoft properties, it is aggregated, it does not show exact user prompts, and it does not prove clicks or conversions. But it is a better class of evidence.
If Google eventually extends Search Console to AI Overviews and AI Mode, and if OpenAI creates webmaster reporting for ChatGPT Search, the role of third-party prompt trackers will shrink. They will not disappear. They will become competitive research and topic-gap tools, not the source of truth for your own visibility.
Build Your Own Transparent AI Visibility Audit
Because the market is noisy, I built a small shareable tool for this article: AI Visibility Audit Lite. It is a Node.js CLI with no external npm dependencies. You can run your own prompts through DataForSEO's Google AI Mode endpoint, SerpApi's Google AI Mode engine, or both, then export raw JSON plus a CSV summary.
The tool is deliberately modest. It does not claim to tell you your real AI visibility. It helps you run a transparent, repeatable prompt sample, with your own credentials, so you can inspect the raw evidence instead of trusting a black-box score.
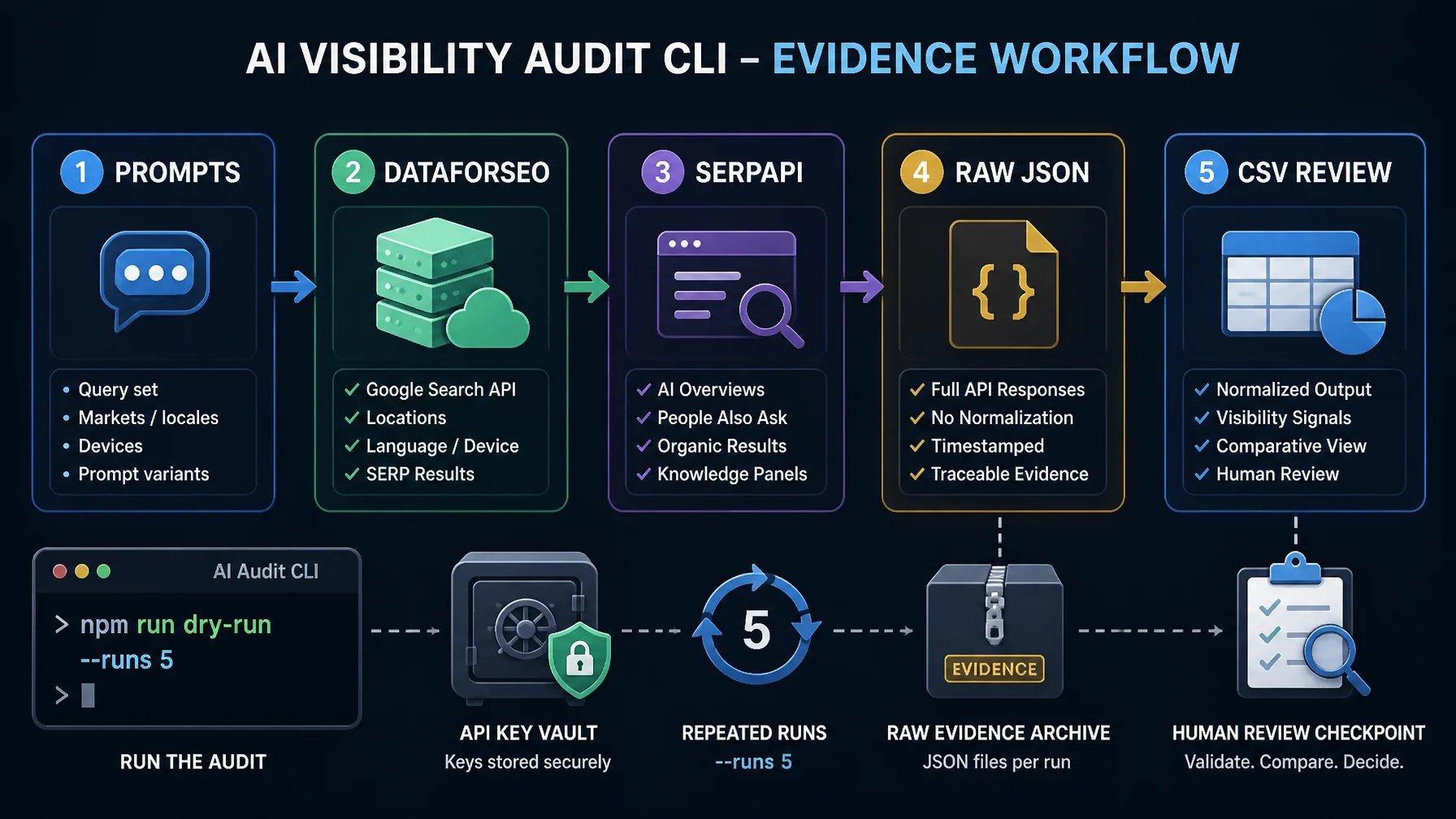
What the Tool Does
- Runs a prompt list against DataForSEO, SerpApi, or both providers.
- Repeats each prompt multiple times, so you can see volatility.
- Counts brand mentions and competitor mentions in the answer text.
- Extracts visible citation domains when the provider returns them.
- Exports raw JSON and a CSV summary for manual review.
- Includes a dry-run mode so people can test the workflow before adding credentials.
How to Run It
Download the ZIP, unzip it, and create a local .env file from the example. For DataForSEO, add:
DATAFORSEO_LOGIN=your-login
DATAFORSEO_PASSWORD=your-passwordFor SerpApi, add:
SERPAPI_KEY=your-keyThen run a dry test:
npm run dry-runAnd a real sample:
node bin/ai-visibility-audit.mjs \
--provider both \
--brand "Your Brand" \
--competitors "Competitor A,Competitor B" \
--prompts prompts.example.json \
--runs 5 \
--location "United States" \
--language enUse Claude or Codex to extend the output. For example, ask Codex to cluster prompts by topic, flag unstable prompts, compare citation domains against your backlink database, or turn the CSV into a client-readable report. Keep the raw JSON. That is your audit trail.
What I Would Measure Instead
If you are responsible for AI search reporting, I would build a layered model:
- First-party citations: Bing AI Performance where available, and future provider dashboards as they arrive.
- AI referral traffic: GA4 channel groups and server logs for visible AI referrers.
- Self-reported attribution: form fields that ask buyers where they first heard about you.
- Topic-gap sampling: large-scale tools like SISTRIX, Ahrefs, or Semrush for clusters where competitors appear and you do not.
- Custom prompt audits: your own repeated samples for strategic prompts, clearly labeled as directional.
- Content and entity work: stronger pages, clearer source signals, better third-party mentions, useful videos, and crawlable evidence.
That last point is the part people skip. Measurement does not create visibility. It only tells you where to investigate. The work is still SEO: publish useful content, make it crawlable, build authority, earn mentions, structure pages clearly, and reduce technical friction. The name can be GEO, AEO, LLMO, or whatever acronym wins this quarter. The durable work is still search strategy.
The Decision Rule
Use AI visibility tools if they help you discover topic gaps, monitor competitor mentions, or answer a stakeholder's question with appropriate caveats. Avoid tools that sell exact rankings, universal scores, or ROI claims without first-party data.
The strongest vendors will be transparent about method, scale, volatility, prompt source, access path, and model version. The weakest vendors will sell a single score and hope you do not ask how it was made.
AI visibility tracking is not dead. It is just younger, noisier, and easier to oversell than SEO rank tracking ever was. The goal is not to avoid measurement. The goal is to stop buying certainty where the system only supports probability.
Sources
- SparkToro: AI brand recommendation consistency research
- Surfer SEO: scraped AI answers vs API results
- SISTRIX AI/Chatbot Research Tool documentation
- Ahrefs Brand Radar help documentation
- Semrush AI Visibility data documentation
- DataForSEO Google AI Mode API documentation
- SerpApi Google AI Mode API documentation
- Ahrefs: AI Overview citations and top 10 rankings
- Search Engine Journal: Bing AI Performance dashboard
About the Author
