
What Actually Gets You Cited in AI Search
Crawlable pages, search strength, fan-out coverage, answer placement, and extractable evidence matter more for AI citations than hype around LLMs.txt.

90-Second AI Citation Recap
Watch the Short Film Before You Read
A cinematic breakdown of why crawlability, search rank, fan-out coverage, answer placement, and extractable evidence matter more than hype around LLMs.txt.
What Actually Gets You Cited in AI Search
TL;DR: The pages most likely to earn AI citations already look like strong SEO assets. They are crawlable, rank for the parent topic, answer the query fast, and package the answer in a form that is easy to quote.
Cyrus Shepard's new Zyppy Signal synthesis is useful because it pulls a noisy conversation into one ranking of evidence-backed signals. The punchline is less glamorous than the AI SEO hype cycle. Search strength still matters. Extractability matters more than `llms.txt` theater.
The cleanest way to read the current AI citation debate is this: retrieval systems still reward pages that can be crawled, matched, trusted, and lifted into an answer without much friction.
That is the core lesson from Cyrus Shepard's AI Citation Ranking Factors Analysis. Shepard reviewed 54 experiments, patents, and case studies, then scored 23 factors based on repeatability, strength of evidence, and official support.
Those numbers matter because the social version of this topic got messy fast. The screenshot circulating on LinkedIn says `55` and `50+ factors`. The formal Zyppy publication says `54` sources and gives a scored list of `23` factors. For this article, I am using the published numbers, not the social shorthand.
Important caveat: this is a synthesis of correlated signals, not a confirmed ranking formula from Google, OpenAI, Microsoft, or any other platform.
What The Analysis Actually Measured
The Zyppy piece is useful for one reason. It compresses scattered GEO research into a structure an SEO team can work with.
It does not prove that every search engine with AI answers uses the same weighting. It does not prove that a page gets cited because of one isolated factor. It gives us a weighted map of what keeps showing up across research, patents, and field observations.
The highest-scoring factors in the analysis are:
| Factor | Score | What it points to |
|---|---|---|
| URL Accessibility | 9.5 | The page can be crawled, indexed, and used for grounding. |
| Search Rank | 9.4 | Pages that already perform well in Search are more likely to feed AI answers. |
| Fan-out Rank | 9.3 | The page covers the supporting questions the engine asks before citing. |
| Preview Control | 9.2 | The system can read and preview enough content to use it safely. |
| Query-Answer Match | 9.2 | The answer matches the user's wording and intent with little interpretation cost. |
| Intent-Format Match | 9.0 | The page format fits the job, definition, comparison, workflow, or checklist the query needs. |

That is a familiar SEO story. If your page is weak in Search, vague in structure, and hard to crawl, AI systems have less reason to use it.
The Main Pattern Is Still SEO Strength
Many teams want AI citations to be a separate game. The data keeps pulling the conversation back to the same place.
Pages earn citations because they already have enough authority at the page level to be discovered, matched, and trusted. That is why `Search Rank` scores so high in Shepard's synthesis. It also fits other recent research, including Ahrefs' finding that a large share of AI Overview citations come from pages already ranking in the top 10.
This is also where many GEO conversations lose the plot. Teams chase novel files and hidden levers while the page still has weak rankings, shallow evidence, and thin answer blocks. AI systems cannot cite what they cannot find, cannot trust, or cannot extract cleanly.
Strong Signals
- crawlability and indexability
- parent-query search visibility
- fan-out coverage
- tight query-answer match
Supporting Signals
- answer near the top
- explicit phrasing
- self-contained passages
- source citation inside the content
Weak Or Overmarketed Signals
- `llms.txt`
- authority shorthand without page fit
- schema sold as a shortcut
- vague brand familiarity without proof
Why Extractability Is The New Layer
Extractability is the part many SEO teams should care about now. It is the difference between a good page and a page that can be lifted into an answer with very little cleanup.
In practice, extractability means:
- the answer appears early, not after 600 words of setup
- the answer uses direct language, not soft framing
- the paragraph can stand alone when quoted
- the page gives sources, examples, or verifiable detail
- the structure tells the system what each block is trying to answer
That framing lines up with Google's own direction. In AI Features and your website, Google keeps pointing publishers back to standard Search guidance. No extra AI-only file is required. The work is still about accessibility, useful content, technical hygiene, and matching what people ask.
It also lines up with the fan-out idea. Kevin Indig's work on the fan-out effect explains why one page can lose even when it ranks for the parent query. The engine often breaks the job into smaller questions first. If your page only addresses the headline query and ignores the supporting branches, another source gets the citation.
The important caveat is that fan-out coverage is not a license to bloat the page. The better read is focused support, not exhaustive sprawl. Pages that answer the main query cleanly and cover the most relevant supporting branches usually outperform “ultimate guides” that try to touch every possible subtopic and dilute the primary match.
What To Stop Overrating
Some of the weakest signals in the Zyppy synthesis are also the ones that get marketed hardest.
LLMs.txt Is Not The Story
`LLMs.txt` scored 2.0 in Shepard's analysis. That does not mean the proposal is useless for every workflow. It means the reviewed evidence is thin if your goal is earning citations across major AI search surfaces.
That lines up with the platform guidance we have today. Google does not ask for a new AI-only text file in order to appear in AI Overviews or AI Mode. OpenAI documents crawler and bot controls, not `llms.txt`, as the relevant path for discovery and eligibility. Bing is talking about grounding, citations, and cited pages, not a universal `llms.txt` adoption model.
Use `llms.txt` as an experiment if you want. Do not build the strategy around it.
Structured Data Is A Supporting Signal
`Structured Data` scored 5.6. That is not nothing. It is also far from the top of the list.
The right read is conservative. Schema can make content easier to classify and connect. It can support consistent entity and page labeling. It can help other search features when the markup matches visible facts. What it does not do is rescue weak answers or replace visible content design.
This is where technical SEO advisory gets useful. Clean schema still belongs in the stack. What should leave the stack is the lazy pitch that one markup layer will solve AI visibility by itself.

What Google, OpenAI, And Bing Add To The Picture
The strongest article on this topic should not stop at a third-party synthesis. It should test the synthesis against what the platforms say and expose.
Google's public guidance keeps the story grounded. AI search features still depend on the same technical and content foundation used for Search. Google also names `query fan-out`, which supports the idea that coverage depth matters inside the answer path. Just as important, Google says there are no extra AI-only requirements for AI Overviews or AI Mode, and supporting-link eligibility still starts with a page being indexed and eligible to show a snippet in Search.
OpenAI's bot documentation matters for a different reason. If a publisher blocks the relevant search crawler, the page may lose eligibility for inclusion in ChatGPT search responses. That does not guarantee citations if the crawler is allowed. It does show that accessibility is a baseline requirement.
Bing's recent language around the AI web is also useful. Microsoft is leaning into grounding and citation reporting. The public preview of AI Performance in Bing Webmaster Tools suggests that cited pages, total citations, and grounding queries are becoming operational reporting surfaces, not only theoretical concepts.
For working SEOs, this adds up to a simple rule. Treat AI citation work as a retrieval and answer-design workflow. Then measure it with the reporting tools that are emerging, not with a single vanity signal.
A Working Model For SEO Teams
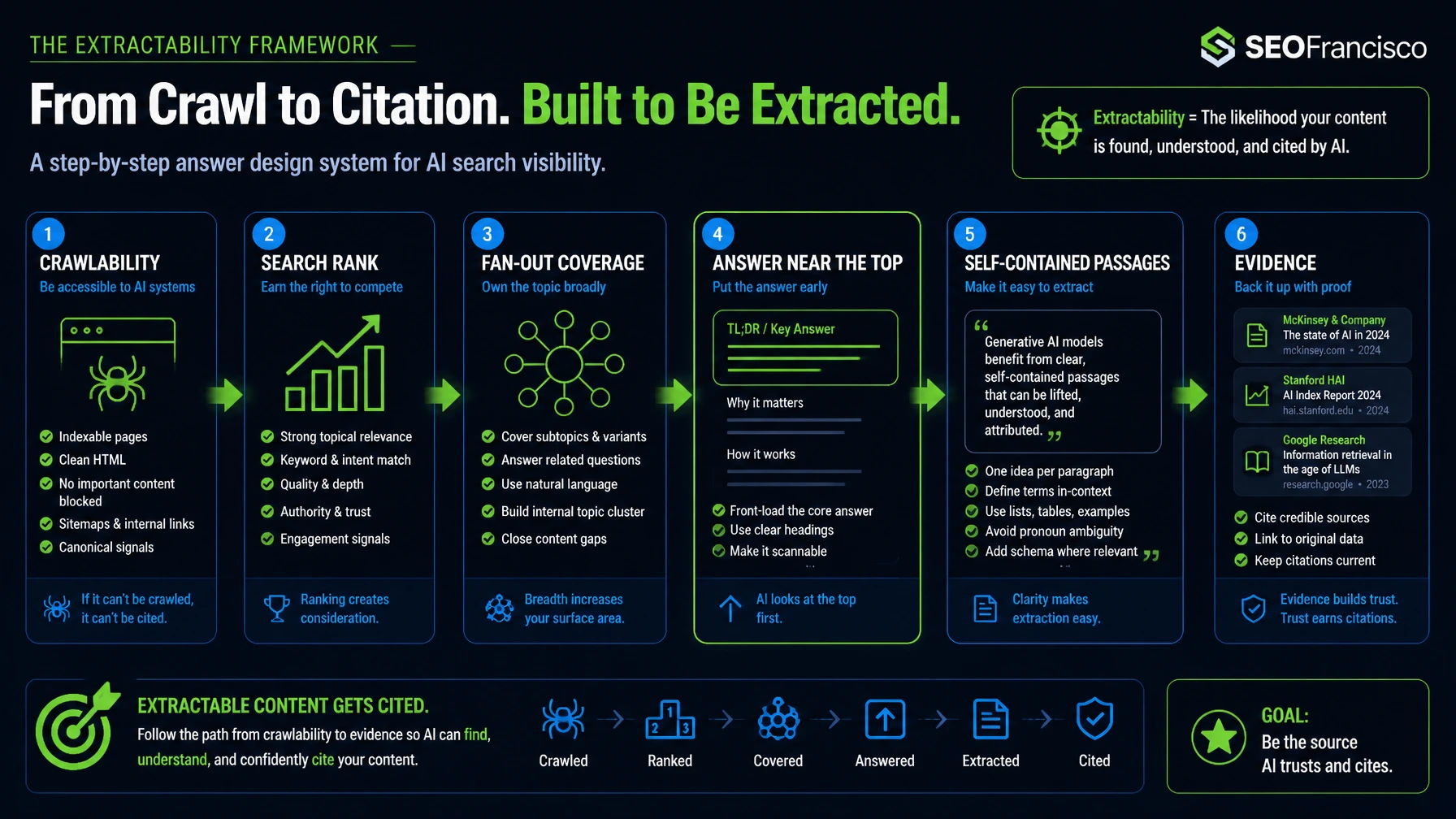
If I had to reduce this article to one practical framework, it would be this:
- Accessibility: let the system crawl, fetch, and preview the page.
- Rank: win enough search visibility to enter the candidate set.
- Fan-out coverage: answer the supporting questions around the main query.
- Extractability: place a direct answer high on the page in explicit language.
- Evidence: cite sources, add specifics, and give the answer something solid to rest on.
That framework fits what I am already seeing across AI SEO work. Teams that publish specific, source-backed, well-structured pages are easier for answer engines to use. Teams that publish vague opinion pieces with weak information architecture are harder to ground, even if they publish more often.
It also fits the next measurement problem. A citation does not always mean influence. The page may appear in the footnotes without changing the answer much. Recent GEO research frames this as the difference between citation selection and citation absorption. A page can win the link layer but still lose the answer layer if another source contributes more of the language, facts, structure, or comparisons that shape the final response.
Where The Data Is Still Soft
This topic has enough confusion around it that the caveats deserve their own section.
- One synthesis, mixed ecosystems: the evidence base blends Google AI Overviews, ChatGPT search behavior, Perplexity-style systems, patents, and field studies.
- Correlated signals: Shepard's analysis is explicit about this. The factors track with citations. They are not a universal platform formula.
- Different engines, different retrieval habits: a tactic that helps in Google AI Overviews may have a weaker effect in another system.
- Measurement is still immature: more cited does not automatically mean more clicks, more influence, or more revenue.
That is exactly why the anti-hype posture matters here. Good teams should use this research to improve page architecture and answer design. They should not use it to sell certainty that the evidence cannot support.
Sources
- Zyppy Signal, AI Citation Ranking Factors Analysis
- AI Citation Ranking Factors Publication Heat Map
- Google Search Central, AI Features and your website
- OpenAI, Overview of OpenAI Crawlers
- Microsoft Bing, Elevating the Role of Grounding on the AI Web
- Microsoft Bing Webmaster Tools, AI Performance public preview
- Ahrefs, 38% of AI Overview citations pull from the top 10
- AirOps, The Fan-Out Effect
- DEJAN, SRO & Grounding Snippets
- GEO, Generative Engine Optimization
- From Citation Selection to Citation Absorption
FAQ
What is the strongest AI citation ranking factor in the Zyppy analysis?
URL accessibility scored highest at 9.5. The practical meaning is clear. If a page cannot be crawled, previewed, and used for grounding, it is harder to cite.
Does ranking well in Google still matter for AI citations?
Yes. Search rank scored 9.4 in the Zyppy synthesis, and separate studies suggest many AI citations still come from pages that already rank well for related queries.
Does structured data still matter for AI search?
It appears to matter as a smaller supporting signal, not as a primary citation lever. Keep schema clean and aligned with visible content, but do not expect it to rescue weak pages.
Should SEO teams implement llms.txt for AI citations?
You can test it, but the evidence base behind citation impact is weak right now. It should not outrank crawlability, answer quality, fan-out coverage, or source support in the roadmap.
What does extractability mean in practice?
It means the answer is easy to find, easy to quote, and easy to verify. Put the answer near the top, use explicit language, keep the passage self-contained, and cite something solid when the claim needs proof.
About the Author
