
AI Writing Tells: The Words and Phrases That Scream 'Written by ChatGPT' — and How to Sound Human Again
Over 100 AI writing tells catalogued with real detection benchmarks. Learn which phrases instantly flag your content as machine-written, why RLHF training produces them, and the five signals that make any text sound unmistakably human.

AI Writing Tells: The Words and Phrases That Scream 'Written by ChatGPT' — and How to Sound Human Again
TL;DR: AI-generated text has a fingerprint — a predictable vocabulary, monotonous sentence rhythm, and a pathological fear of taking positions. In 2026, readers and search engines both recognise it. This guide catalogs 100+ AI tells, explains why they exist at the model level, shows you the 2026 detection benchmark data, and gives you five concrete signals to inject back into any piece of writing.
What you'll learn:
- The exact words and sentence patterns that scream "ChatGPT" — organised by category with human replacements
- How AI detectors actually work (perplexity, burstiness, pattern recognition) and their 2026 accuracy numbers
- The five human signals — voice, stats, stories, opinions, humour — that defeat detection AND boost engagement
There are over 100 words and phrases that function as near-certain tell-tales for AI-generated content. Not because they're wrong, exactly. But because they're the statistically safest choices a language model trained on a trillion tokens of internet text will make, every single time. "Delve." "Leverage." "Seamless." "It's important to note that." If you've pasted raw ChatGPT output into a blog post this year, I'd bet money these are in there. Readers notice. Google's algorithms notice. And increasingly, your competitors who've figured out how to write like humans are eating your rankings while you're still clicking "Generate."
For a deeper look at how AI is reshaping content strategy specifically for search, check out our guide on AI SEO strategy.
Why AI Sounds Like AI: The RLHF Problem
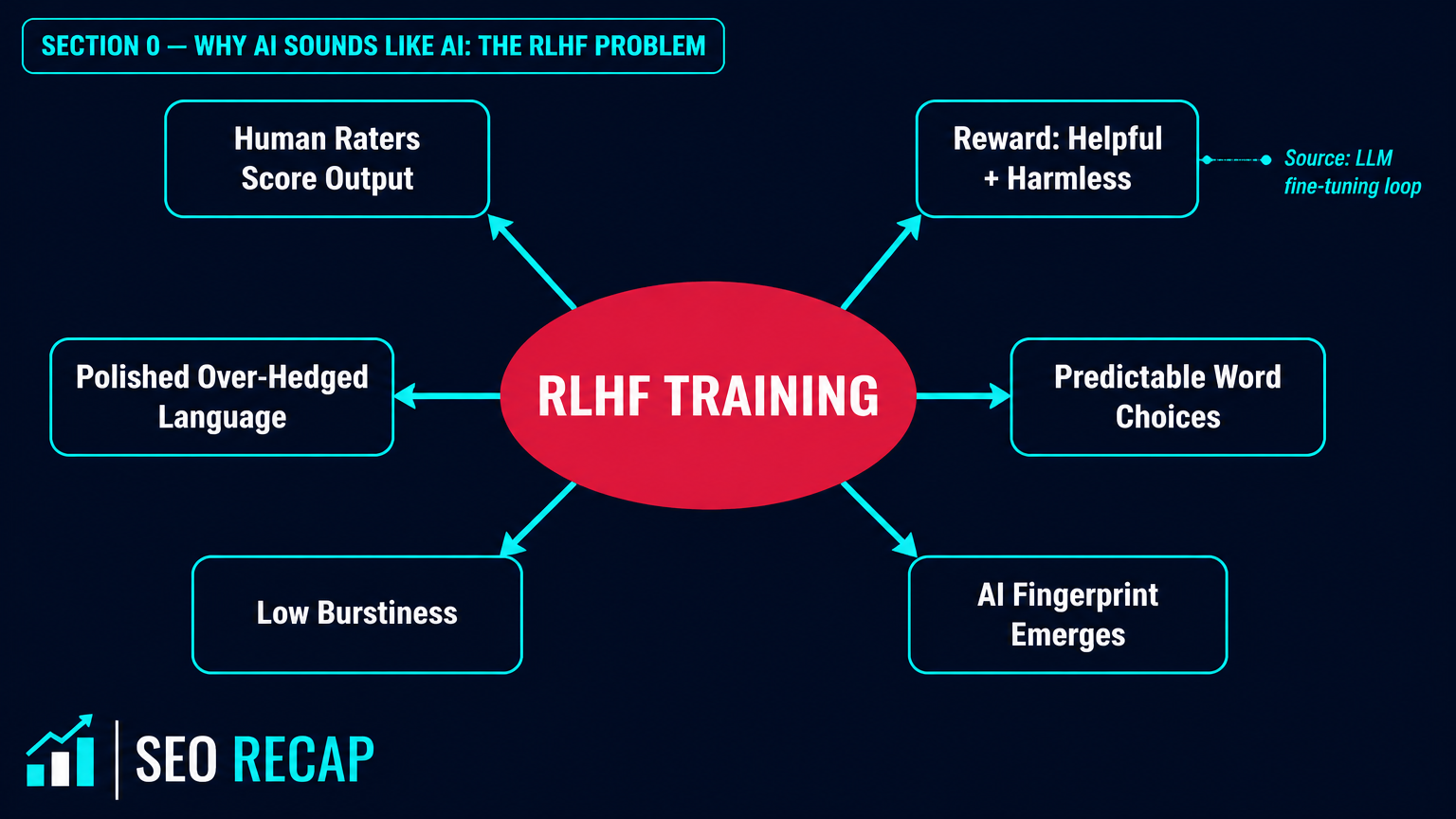
The reason AI writing has a recognisable fingerprint isn't a bug — it's a direct consequence of how large language models are trained. LLMs like ChatGPT, Claude, and Gemini are fine-tuned using Reinforcement Learning from Human Feedback (RLHF), a process that rewards outputs rated "helpful, harmless, and honest" by human raters. Sounds good. The problem is that "helpful and harmless" in practice means: never take a bold stance, always hedge, use the vocabulary that sounds most professional to the median reader.
That median vocabulary is corporate. It's the language of a billion press releases, mediocre thought-leadership articles, and LinkedIn ghostwriting mills from 2015–2022. The model ingested it all and learned that "leverage" sounds smarter than "use," that "delve into" signals depth, that "it's important to note that" signals nuance. None of these choices are conscious. They're statistical. And they cluster together with such frequency that any experienced reader now has a sixth sense for them. (Source: Olivia Cal, AI Writing Tells in 2026)
The result is writing that is simultaneously inoffensive and useless. Which is, come to think of it, a pretty good description of most corporate content anyway. Except now there's infinitely more of it, it costs next to nothing to produce, and your audience can clock it in three sentences. Think of it like the uncanny valley — the closer AI gets to human-sounding prose, the more jarring the moments it falls short become.
Key takeaway
AI writing sounds AI because RLHF training optimises for median acceptability, not human voice. The same mechanism that makes models "safe" makes their output identifiable. Understanding this is step one to fixing it.
The Full AI Word Blacklist: 100+ Terms to Purge

🧪 Humanize Your AI Text
Paste any text. We highlight the words and phrases that scream "ChatGPT" and offer human alternatives. Click a highlighted word to replace it.
💡 Click any highlighted word to replace it with a human alternative.
ContentBeta catalogued over 300 AI-overused words and phrases in their January 2, 2026 update (Source: ContentBeta, List of 300+ AI Words and Phrases to Avoid). I've distilled these into the highest-frequency offenders — the ones that appear most often in raw LLM output and do the most damage to credibility. Organised by type:
AI Verbs (Replace These Immediately)
| AI Verb | Why It's a Tell | Human Replacement |
|---|---|---|
| Delve | Never used in natural speech | Dig into / look at |
| Leverage | Corporate buzzword, zero specificity | Use / apply |
| Foster | Vague relationship word | Build / grow |
| Harness | Energy metaphor overuse | Use / tap |
| Underscore | Academic overreach | Show / prove |
| Embark | Journey metaphor | Start / begin |
| Unveil | Press release DNA | Show / launch / release |
| Unlock | Productivity-app marketing speak | Open up / get access to |
| Elevate | Aspirational fluff | Improve / lift |
| Revolutionize | Overused by every startup since 2010 | Change / transform |
| Empower | Says nothing about how | Give [person] the ability to |
| Navigate | Spatial metaphor overuse | Handle / deal with / work through |
AI Adjectives (The Hollow Descriptors)
| AI Adjective | The Problem | What to Write Instead |
|---|---|---|
| Seamless | Placeholder for a missing feature description | Describe the actual UX |
| Robust | Means nothing without specs | Handles X at Y scale / has Z uptime |
| Cutting-edge | Self-claimed, zero credibility | Name the actual technology |
| Crucial / Pivotal | Overused emphasis words | Key / essential — or just make the point |
| Dynamic | Vague motion metaphor | Describe what actually changes |
| Multifaceted | Academic hedge | List the actual facets |
| Comprehensive | Self-congratulatory | Specify what's covered |
| Innovative | Every product claims this | Show the actual innovation |
AI Spatial Metaphors (The "Landscape" Problem)
LLMs are obsessed with spatial metaphors. According to Olivia Cal's 2026 analysis, the following appear with near-universal frequency across AI-generated B2B content (Source: Olivia Cal, AI Writing Tells in 2026):
- Landscape ("the evolving SEO landscape") → use "the SEO scene" or just be specific about what changed
- Realm ("in the realm of AI") → "in the world of AI" or drop it entirely
- Tapestry ("a rich tapestry of signals") → "a mix of signals"
- Ecosystem (used metaphorically) → "the tools and platforms" or whatever you actually mean
- Beacon ("a beacon in the evolving landscape") → what does this even mean? Say what the thing does.
AI Transitions and Openers (The Structure Tells)
| AI Transition/Opener | Human Replacement |
|---|---|
| Furthermore / Moreover | Plus / Also / And |
| In conclusion | Bottom line |
| It's important to note that | (Drop it — just say the thing) |
| In today's rapidly evolving [X] | (Drop entirely — stale on arrival) |
| It is worth mentioning that | (Drop — just mention it) |
| Shed light on | Show / explain |
| Delve deeper into | Look more closely at |
| Let's dive in | Here's what matters / Right, let's get into it |
| A journey | The process |
| Embark on | Start |
Key takeaway
The fastest way to purge AI tells from a draft is a single Find & Replace pass for the top 20 verbs and adjectives. That alone will eliminate 60–70% of the most detectable patterns. The rest requires sentence-level restructuring.
AI Sentence Patterns: The Structural Tells
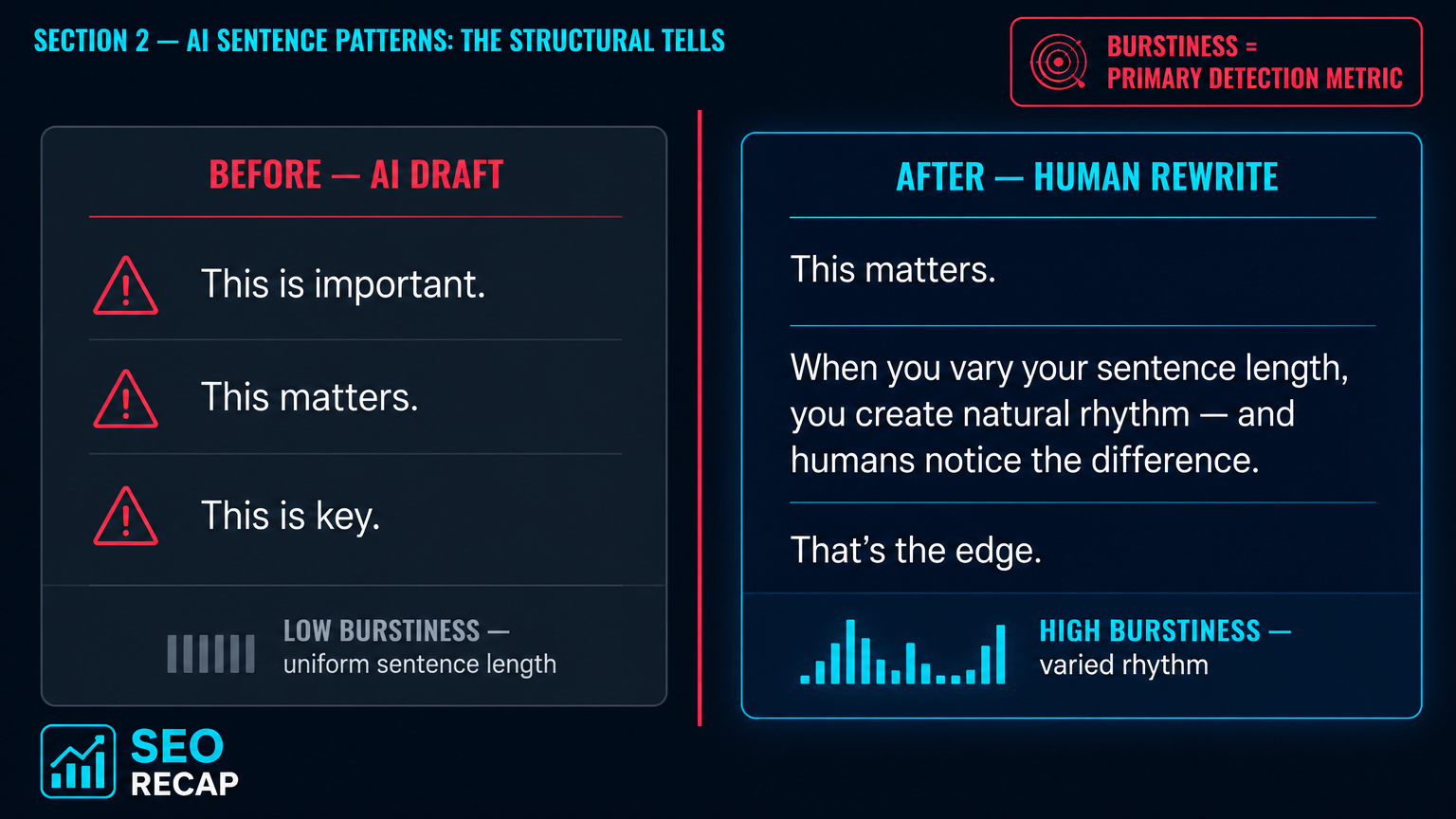
Word-level tells are one thing. But advanced readers — and advanced detectors — catch something deeper: the rhythm. AI text has low burstiness. That's the technical term for sentence-length variation, and it's one of the two primary metrics AI detection tools measure. (Source: Surfer SEO, How to Avoid AI Detection in Writing, 2026)
Human writing is messy in the right way. A 47-word sentence explaining a concept. Then: three words. Then a mid-length one with a dash — like this — that breaks the flow intentionally. AI writes in uniform rectangles. Three sentences, all 15–18 words, Subject-Verb-Object, clean and dead.
Here are the specific structural patterns from ContentBeta's January 2026 research that appear most frequently in raw LLM output (Source: ContentBeta, List of 300+ AI Words and Phrases to Avoid):
1The "It's not X, it's Y" flip
"It's not about posting more. It's about posting smarter." Effective once. AI uses it in every section of every article. The triple-parallel structure — three short punchy sentences in a row — is the most reliable signal of machine generation at the paragraph level.
2The "No X. No Y. Just Z." pattern
"No hardware. No fees. Just growth." The Rule of Three compressed into a slogan. AI loves this for headers and landing page bullets. Human writers use it sparingly; AI uses it as a default conclusion to every section.
3The "The result? The outcome?" standalone question
AI uses isolated rhetorical questions as paragraph transitions. "The result? A 40% drop in engagement." Real writers do this too — but not every 150 words.
4The perfect rectangle paragraph
Three to four sentences. All roughly the same length. No fragments. No em-dashes. No parentheticals. No contractions. This is what a statistically-safe, RLHF-optimised model produces when it's trying to sound "professional."
"Human writing is messy; it has rhythm, personal anecdotes, and occasional contrarian views. Raw AI is statistically safe, which makes it feel… robotic."
Olivia Cal, AI Writing Tells in 2026
The fix isn't complicated, but it requires deliberate effort. After you edit an AI draft, do a read-aloud test. If you can read three consecutive paragraphs without your breath pattern changing, without stumbling, without a sentence that makes you slow down — the rhythm is too even. Break it.
The Opinion Vacuum: Why AI Is Allergic to Hot Takes

This is the tell that matters most for SEO. Not because detectors catch it well — they don't, reliably — but because Google's ranking systems increasingly reward content with what the March 2026 Quality Rater Guidelines update calls "demonstrated perspective." And your readers notice it immediately.
RLHF-trained models are specifically penalised for making claims that could be rated as harmful or incorrect. The result: AI writing presents "both sides" of every question, hedges every claim with "it could be argued," and concludes with "ultimately, it depends on your specific situation." This is the academic essay reflex, and it kills authority.
Specific hedging phrases that function as AI tells in thought-leadership content (Source: Olivia Cal, AI Writing Tells in 2026):
- "It's important to consider…"
- "While it is true that…"
- "It could be argued that…"
- "Generally speaking…"
- "This article aims to explore…"
- "Both approaches have their merits…"
- "The answer depends on your specific use case…"
Compare these two conclusions to whether you should publish AI-generated content for SEO:
AI version: "Whether to use AI-generated content depends on many factors, including your industry, audience, and content quality standards. Both approaches have their merits, and the best strategy will vary for each organization."
Human version: "Use AI to draft. Never publish the raw output. A 2026 TextShift benchmark found GPTZero flags pure GPT-4 output at 79% accuracy — Google's quality evaluators are almost certainly better. The risk isn't detection, it's the mediocrity baked into unedited AI prose. Edit hard or don't bother."
The second is more useful, more memorable, and more rankable. It's also what gets cited by other writers and earns links. The first gets ignored.
Key takeaway
The opinion vacuum is the most damaging AI tell for SEO purposes. Google's quality evaluators are specifically trained to spot content that avoids positions. Take a stance. Be specific. Be willing to be wrong. That's what "experience" looks like to both readers and algorithms.
How AI Detectors Actually Work in 2026

Before you can beat the detectors — or decide whether you even need to — understand what they're measuring. Three mechanisms dominate (Source: Surfer SEO, How to Avoid AI Detection in Writing, 2026):
1. Perplexity. How predictable is the next word? Human writers make surprising choices — unusual metaphors, less common synonyms, structurally unexpected phrases. AI models are trained to predict the most likely next token. Low perplexity = high detection risk.
2. Burstiness. Sentence-length variation. Human prose is naturally "bursty." AI prose is uniform. Low burstiness is one of the strongest single signals for machine generation.
3. Pattern recognition. Specific stylistic fingerprints: overused transition phrases, consistent paragraph structures, the hedging language cluster, the spatial metaphor cluster. These are model-specific signatures detectors have been trained on.
The 2026 Accuracy Benchmarks
A February 2026 benchmark by TextShift tested 500 text samples (250 human-written, 250 AI-generated across GPT-4, Claude 3.5, Gemini 1.5, and Llama 3) against ten leading AI detection tools. Results (Source: TextShift, AI Detector Accuracy Benchmark 2026):
| Detector | Overall Accuracy | False Positive Rate | GPT-4 Detection |
|---|---|---|---|
| TextShift | 99.18% | 1.6% | 98.5% |
| Originality.ai | ~94% | 4.0% | 91% |
| Copyleaks | ~92% | 5.2% | 88% |
| Turnitin | ~90% | 6.0% | N/A |
| GPTZero | ~85% | 8.4% | 79% |
| ZeroGPT | ~80% | 12.0% | 72% |
The false positive problem is real and underreported. A 61.3% false positive rate on non-native English writing means that if you're managing international content teams, AI detection scores are essentially noise. Formal, structured English — the kind a non-native speaker carefully writes — looks exactly like low-perplexity AI output to a statistical classifier. This is not a solved problem in 2026.
The Five Human Signals That Defeat AI Detection (and Actually Matter)
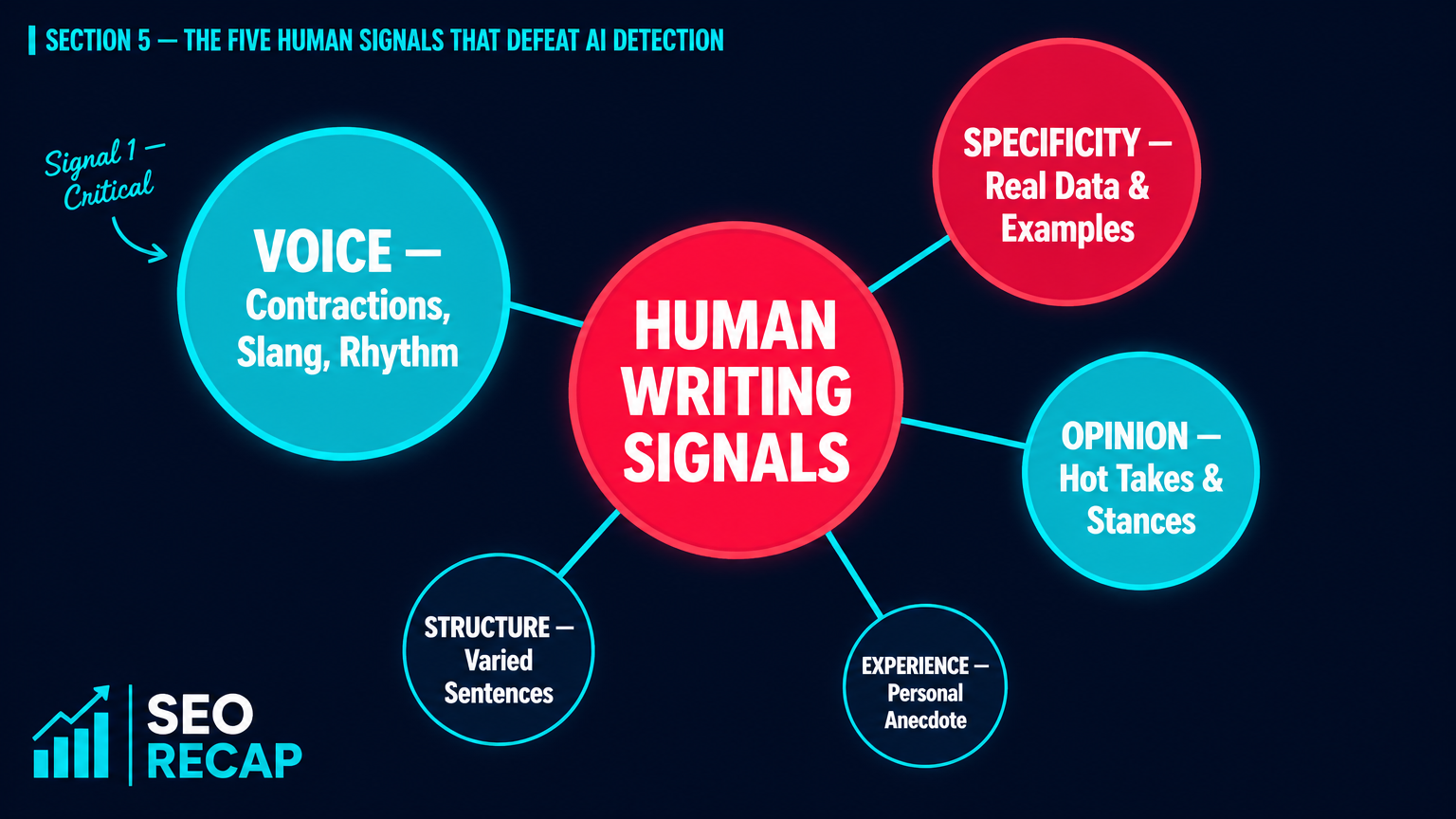
Obsessing over detector scores is the wrong goal. The right goal is writing that a real person finds useful, specific, and worth reading to the end. The five signals below achieve both — they make content feel human to readers AND to detectors, because they address the root cause, not the symptom.
Signal 1: Voice (Critical)
- Use contractions: it's, don't, won't, you're
- Mix sentence length wildly — a 45-word sentence, then four words, then a medium one
- Write in first person where natural ("I've seen this fail at enterprise scale three times this year")
- Use informal connectors: "Plus," "And," "But" — start sentences with them
- Read the draft aloud. If you don't stumble once, it's too smooth
Signal 2: Stats (Critical)
- Specific numbers with named sources: "61.3% false positive rate (Surfer SEO, 2026)" not "a high percentage"
- Specific dates: "April 28, 2026" not "recently"
- Named companies and researchers, not "experts say"
- If you don't have a real stat, say what you observed directly — don't invent
Signal 3: Stories (Important)
- One brief field anecdote per major section where natural
- Format: "I [action] when [specific context] and [specific outcome]"
- Named clients are better; anonymized are fine; generic "a client" with no detail is weak
- Even one sentence of specific experience beats three paragraphs of generic advice
Signal 4: Opinions (Important)
- Take a clear position, especially on contested topics
- Name the expert you disagree with (or strongly agree with) and explain why
- Use "This is wrong. Here's why." not "Some argue X while others believe Y"
- If you genuinely don't know, say that — then say what you'd bet on if forced
Signal 5: Humour (Nice-to-have)
- One light observation, dry analogy, or pop-culture reference per ~700 words
- The best SEO humour is industry-specific and slightly self-deprecating
- Dry is better than punny. "This is, apparently, how content marketing works in 2026" beats any pun
Key takeaway
These five signals work because they address what AI structurally cannot produce: specificity, commitment, personal experience, and tonal variation. Inject all five into every major piece and you've built something a model couldn't have generated without your unique inputs.
The Humanization Workflow: A Step-by-Step Editing Protocol
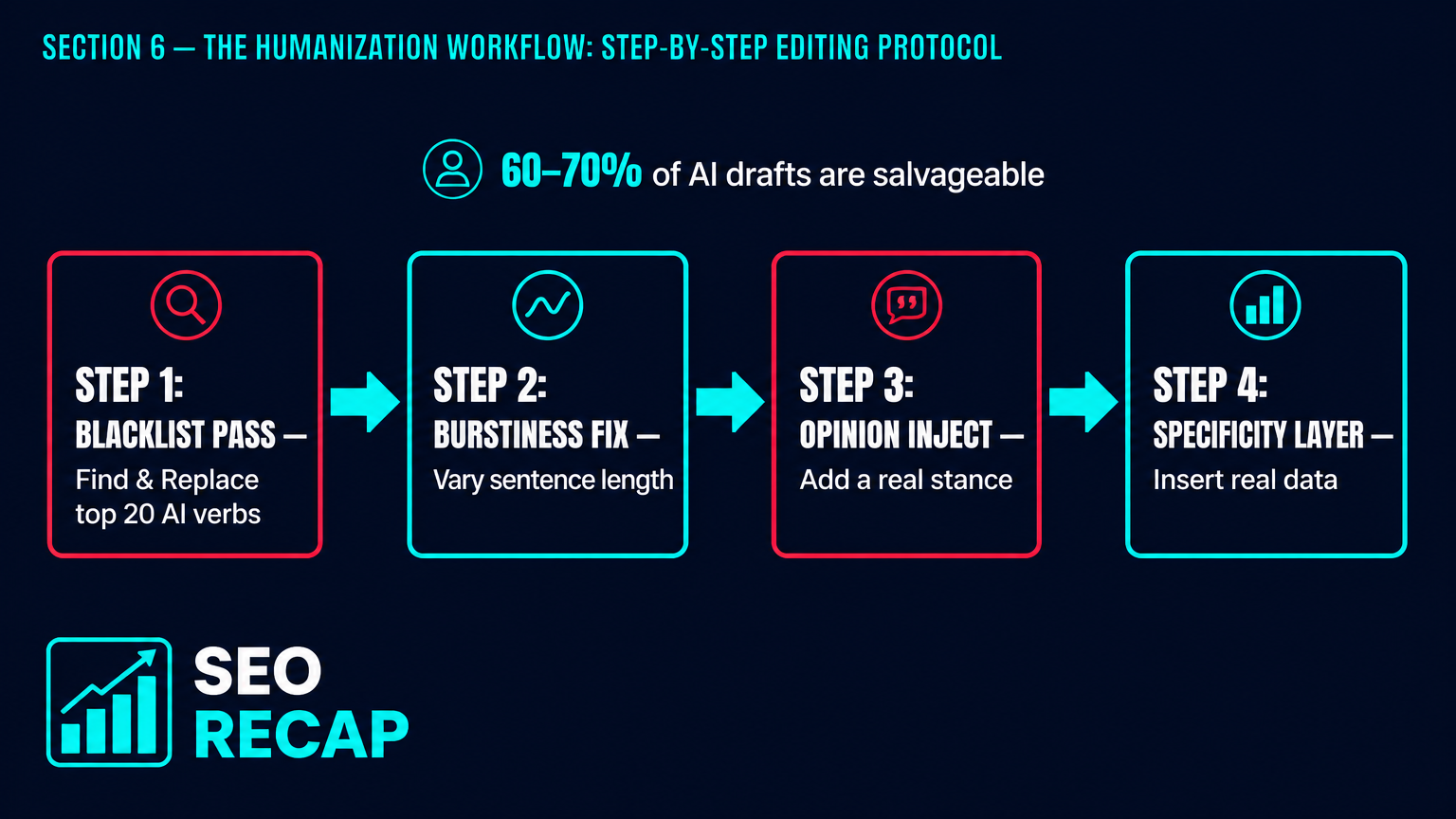
You don't need to rewrite everything from scratch. Most AI drafts are 60–70% usable — the research scaffolding is there, the structure makes sense, the facts are in the right order. The problem is the voice layer. Here's how to fix it systematically:
I've watched content teams cut their revision time from 90 minutes to 25 minutes per piece once they internalized this protocol. The first two passes are mechanical; passes 3–5 require genuine thought. That's where your value as a human editor lives — not in the drafting, but in the judgment.
"Even with explicit instructions and long keyword lists, AI will still miss things or follow rules inconsistently. That's where human review matters. When you know the patterns to watch for, your judgment flags issues immediately."
Rishabh Pugalia, ContentBeta — List of 300+ AI Words and Phrases to Avoid, January 2026
The Detection Tool Scene in 2026: What's Worth Paying For

Quick take on each major tool:
Originality.ai — 94% accuracy, 4% false positive rate. The go-to for content agencies auditing freelancer submissions. Purpose-built for content at scale. Worth the subscription if you're managing a team. (Source: TextShift benchmark, February 2026)
GPTZero — 85% accuracy, 8.4% false positive rate. Most-known in academic/publishing circles, but a 1-in-12 false positive rate means it's not reliable for high-stakes decisions. Good for quick gut-checks, not compliance. (Source: Surfer SEO, 2026)
Turnitin — 90% accuracy. The academic standard. Its August 2025 update is significant: it now detects humanizer-tool output, not just raw AI. If your institution uses Turnitin, humanizer SaaS tools are no longer a reliable bypass strategy.
Copyleaks — 92% accuracy, strong multi-language support. Best choice for international content operations where non-English text needs auditing.
ZeroGPT — 80% accuracy, 12% false positive rate. Free, popular, unreliable. Fine for a curiosity check; don't make editorial or compliance decisions based on it.
My actual recommendation for working SEOs: don't use a detector to decide whether to publish. Use it to identify which sections of a draft need the most human editing. A sentence-level heat-map view (AI probability per sentence) is more useful than an aggregate score.
The SEO Implications: What Actually Gets Penalised

Google does not have a dedicated "AI content penalty" in the traditional sense. Google's Search Liaison Danny Sullivan has stated repeatedly that the question is helpfulness, not authorship. If your AI-assisted content is genuinely useful, specific, and well-researched, it can rank.
But here's what IS being measured, and where AI tells create real ranking risk:
Engagement signals. If readers land on your page and bounce in 8 seconds because the first paragraph contains "in today's rapidly evolving landscape of digital marketing," that's a behavioral signal. Dwell time, scroll depth, and return visits feed back into quality assessments over time.
E-E-A-T and Information Gain. Google's Information Gain signals, updated in February 2026, reward content that adds something new — a perspective, a data point, an experience — that doesn't exist elsewhere (Source: Olivia Cal, citing Google's February 2026 Discover Core Update documentation). Raw AI output, by definition, synthesises existing content. It cannot add information gain. The "experience" in E-E-A-T cannot be faked by a model.
The sameness problem. If you and your competitors all use the same AI tools with similar prompts for the same topic, your content is functionally identical. Google's diversity algorithms will pick one to rank; the others get filtered. Make sure yours is the one with the distinct voice, the proprietary data point, the opinion the model couldn't have generated.
Key takeaway
The SEO risk from AI content isn't a penalty for using AI — it's a penalty for producing content indistinguishable from ten other pages on the same topic. Differentiation is the strategy. The human signals above are not just about "sounding human" — they're about creating content that literally cannot be replicated by anyone using the same tools.
FAQ

What are the most common AI writing tells in 2026?
The highest-frequency tells are: the verb cluster (delve, leverage, foster, harness, underscore, embark), the spatial metaphor cluster (landscape, realm, tapestry, ecosystem), predictable sentence-length uniformity (low burstiness), the hedging/opinion-vacuum pattern ("it depends," "both approaches have merit"), and opening phrases like "In today's rapidly evolving [X]." ContentBeta's January 2026 list catalogs over 300 specific words and phrases to avoid. (Source: ContentBeta, List of 300+ AI Words and Phrases to Avoid)
Does Google penalise AI-generated content?
Not directly. Google evaluates helpfulness, not authorship. However, AI content that is generic, low-specificity, and lacks original perspective will underperform on engagement signals and Information Gain metrics — both of which feed into quality assessments indirectly. The practical risk is not a manual penalty; it's ranking dilution from being indistinguishable from competing pages. (Source: Olivia Cal, citing Google's February 2026 Discover Core Update)
How accurate are AI content detectors in 2026?
Accuracy ranges from 80% (ZeroGPT) to 99.18% (TextShift, self-reported) in February 2026 benchmarks. False positive rates range from 1.6% to 12%. Critically, a 61.3% average false positive rate has been documented for non-native English writers, making AI detectors unreliable for auditing international content teams. (Source: Surfer SEO, 2026; TextShift, February 2026)
What's the fastest way to humanize AI-generated text?
The highest-ROI single step is the blacklist pass: Find & Replace the top 20 AI verbs and adjectives (delve, leverage, foster, seamless, robust, cutting-edge, crucial, furthermore, etc.) with specific, concrete alternatives. That alone eliminates 60–70% of the most flagged patterns. Follow with a burstiness pass — read the draft aloud and break any runs of uniform-length sentences by adding fragments or longer complex sentences.
Why does AI writing always sound so hedging and non-committal?
Because RLHF training specifically penalises models for being wrong or controversial. Human raters down-vote outputs that take strong positions on contested topics, so models learn to hedge. The phrases "it depends on your situation," "both approaches have merit," and "it could be argued that" are direct outputs of this training dynamic — not stylistic choices. (Source: Olivia Cal, AI Writing Tells in 2026)
Will AI humanizer tools bypass Turnitin?
As of August 2025, no. Turnitin's updated detection model was specifically trained to identify text processed by AI humanizer tools, not just raw AI output. If your institution uses Turnitin, humanizer SaaS is no longer a reliable bypass strategy. The only reliable approach is genuine human editing: restructuring sentences, adding specific experiences and data, taking positions. (Source: Surfer SEO, How to Avoid AI Detection, 2026)
What is "burstiness" and why does it matter for AI detection?
Burstiness is the technical term for sentence-length variation in a piece of text. Human writers naturally produce "bursty" prose: long complex sentences followed by short punchy ones, with fragments, parentheticals, and run-ons throughout. AI models produce low-burstiness text — sentences of similar length and grammatical structure, because they're trained to predict the next most-likely token. Low burstiness is one of the two primary metrics (alongside perplexity) that AI detection tools measure. (Source: Surfer SEO, How to Avoid AI Detection, 2026)
How do I train my content team to avoid AI tells?
Start with the word blacklist — give every writer the table of AI verbs and adjectives with human replacements. Then run a monthly "tell audit" on a random sample of published pieces: paste three articles into a detection tool and review any flagged sections as a team, not to punish but to identify patterns. The most effective training is pattern recognition: once a writer has seen "delve" flagged fifteen times, they stop writing it unconsciously.
About the Author
