
Abril 2026: Actualización básica Aftermath, el GSC Impresions Bug, y por qué LLM Bots Ahora fuera de Crawl Googlebot
Análisis profundo de la actualización del núcleo de Google 2026, la Consola de Búsqueda de 10 meses impresiones bug, LLM bot gate dominance, y cómo AI Resúmenes están remodelando CTR orgánico. Estrategias de recuperación factibles para cada equipo de SEO.

1. Marzo 2026 Actualización básica: Análisis completo de rollos y hoja de ruta de recuperación

The Full Update Sequence Matters La mayor cobertura se centra en la actualización del núcleo en aislamiento. Es un error. Google desplegó tres cambios algoritmos distintos dentro de una ventana de 14 días, y la comprensión de la secuencia es crítica para la atribución precisa del rendimiento.
Descubrir actualización , Google ajustó cómo las superficies de contenido en Google Discover se alimentan, afectando los patrones de tráfico para los editores muy dependientes en Discover.
Actualización de Spam , Completed in under 20 hours, making it the shortest confirmed spam update in Search Status Dashboard history. Este eslabón objetivo Spam, obstrucción y patrones de redirección manipuladores.
Actualización básica , El evento principal. Descrito por Google como "una actualización regular diseñada para mejorar la superficie relevante, el contenido satisfactorio para los buscadores de todo tipo de sitios". Montaje total: 12 días.
Por qué esto importa: Si su tráfico cayó entre el 24 de marzo y el 8 de abril, usted podría estar tratando con sanciones de spam, reevaluación de la calidad básica, o ambos. El diagnóstico de la causa equivocada conduce a la estrategia de recuperación incorrecta.
¿Qué Industrias y Tipos de Sitio fueron más duras? La actualización del núcleo de marzo 2026 aplicó escrutinio intensificado a las categorías de contenido de YMYL (Tu dinero o tu vida). Los sitios web en los verticales de servicios de salud, finanzas, legales y caseros experimentaron la volatilidad más significativa porque
Google mantiene este contenido a las normas más altas de E-E-A-T (Experiencia, experiencia, autoridad, confianza). Pero el patrón más profundo va más allá de los verticales de la industria. Según el análisis de fuentes cruzadas, la actualización impactó fuertemente tres arquetipos específicos del sitio que la mayoría de la cobertura ha perdido:
Los tres tipos del sitio más duro
- Editoriales de profundidad. Los sitios que ampliaron la producción de contenidos en temas relacionados flojamente durante los últimos años lucharon significativamente. Los sistemas de Google ahora penalizan el esguince tópico sin experiencia demostrada , publicar 500 artículos en 50 temas indica una granja de contenido, no autoridad.
- Negocios locales que fueron demasiado genéricos. Sitios locales que se convirtieron en demasiado amplios, apartándose de sus servicios reales y de su enfoque geográfico, perdieron la visibilidad. Un fontanero en Denver blogging sobre consejos generales de renovación del hogar en todo el país es el ejemplo clásico.
- Comercio electrónico con infraestructura de categoría fina. La actualización exponía vulnerabilidades en sitios que dependían de copia de categoría fina, texto del fabricante duplicado y experiencias de filtrado débiles. Las páginas de producto sin descripciones originales y páginas de categoría con contenido de caldera fueron especialmente afectadas.
The Recovery Roadmap
Google's own guidance is to wait at least one full week after completion (meaning after April 15) before drawing conclusions from the data. Su período de referencia debe ser las semanas antes del 27 de marzo, en comparación con el desempeño después del 8 de abril. Si necesita una lectura externa en donde su sitio realmente se encuentra, nuestro
asesor técnico de SEO Los compromisos emparejan el diagnóstico de nivel de registro a continuación con una auditoría de contenido E-E-A-T. Esto es lo que hay que hacer mientras tanto:Lista de recuperación de actualización básica
- Auditoría su página de señales E-E-A-T por página. ¿Tus páginas de top-traffic tienen bios autor con credenciales verificables? ¿Está citando fuentes primarias o simplemente resumiendo otros resúmenes?
- Segmenta tus datos por ventana de actualización. Compare el 24 al 25 de marzo (spam update) por separado del 27 de marzo al 8 de abril (core update). Diferentes gotas requieren diferentes correcciones.
- Chequee por agravar las penas. Si tanto el spam como las actualizaciones básicas le afectaron, diríjase a los problemas de spam primero , limpieza de enlaces, auditorías de redireccionamiento, cheques de obstrucción , antes de abordar la calidad del contenido.
- Añadir investigación original y experiencia de primera mano. Los sistemas de Google recompensan cada vez más el contenido que ofrece algo nuevo: datos originales, entrevistas de expertos, estudios prácticos de casos.
- Revise el contenido de YMYL con escrutinio extra. La salud, las finanzas y las páginas legales necesitan una experiencia demostrable. Considerar la posibilidad de agregar insignias de examen de expertos, citando profesionales médicos o jurídicos y vinculando con fuentes autorizadas.
2. The 10-Month GSC Impresions Bug: Lo que sus datos realmente parecían
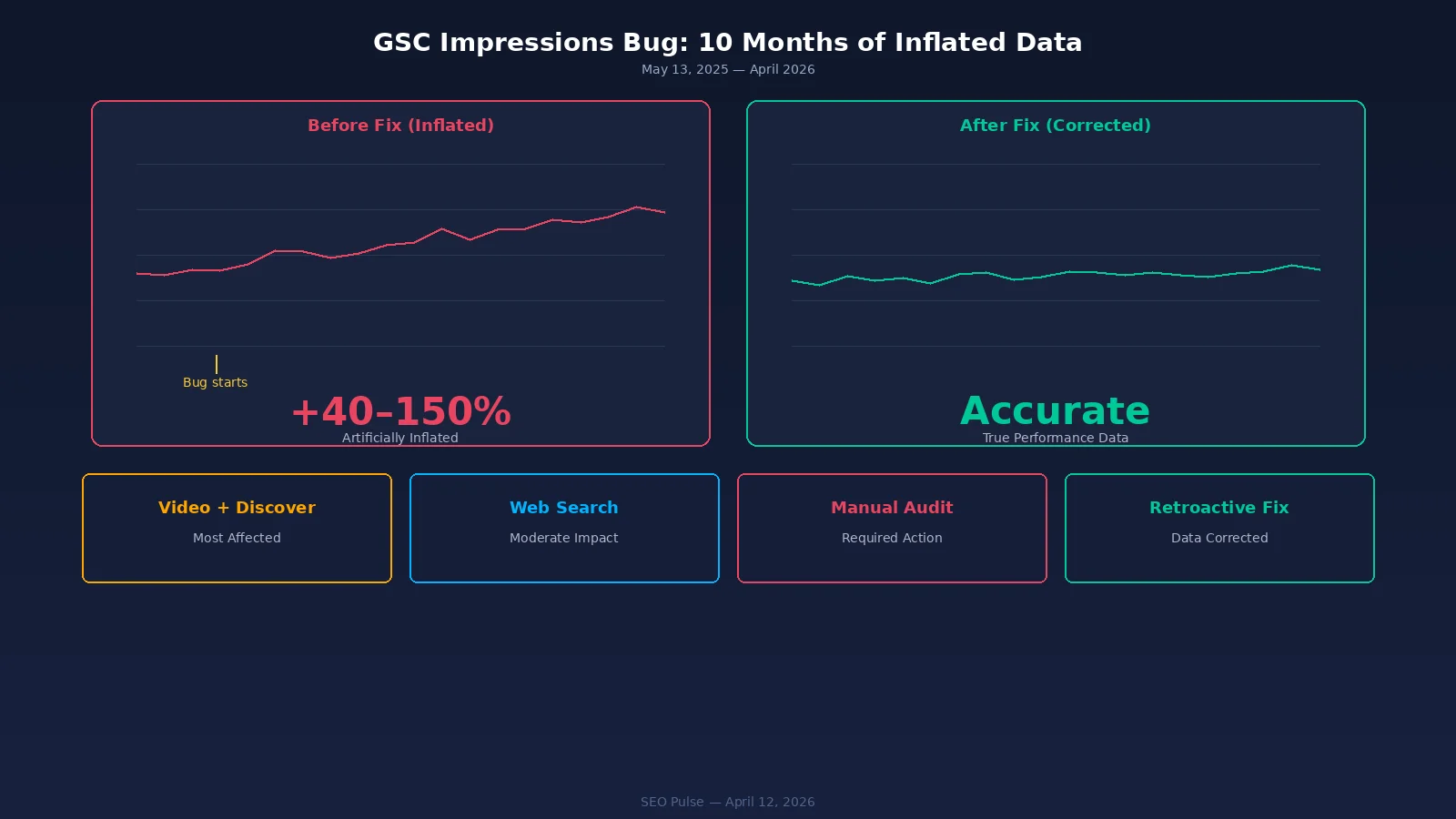
Lo que fue Afectado , y Lo que no fue
Google confirmó que los clics y otras métricas directas no fueron afectados. El error fue aislado para impresionar el registro. Sin embargo, esta distinción es menos tranquilizadora de lo que suena, porque cualquier métrica derivada de impresiones fue corrompida. Esto incluye:
| Metric | ¿Afectado directamente? | Impact |
|---|---|---|
| Impressions | Sí, sobre reportado | La impresión cruda cuenta inflado desde mayo 2025 |
| Clicks | No | Los datos del clic seguían siendo exactos |
| CTR (Tasa de estudio) | Sí, artificialmente deflado | El denominador de impresión superior hizo que CTR parezca inferior a la realidad |
| Posición media | Potentially skewed | Otras impresiones registradas pueden haber alterado promedios de posición |
| Listados de Mercante / Google Imágenes | Sí , especialmente afectado | Los sitios de eCommerce confiando en estos filtros vieron la mayor distorsión |
The Ripple Effect on Strategic Decisions
Piense en qué 10,5 meses de datos desinflados de CTR significa en la práctica. Los equipos que observan la disminución de CTR pueden haber lanzado campañas de optimización para problemas que no existían. El contenido que parecía estar infravalorando en CTR puede haber estado funcionando bien. Los resultados de la prueba A/B para las etiquetas de título y las meta descripciones realizadas durante este período pueden ser reevaluados.
Medidas inmediatas: Bandera todos los informes y tableros de control de GSC que abarcan el 2025 de mayo a través del presente como potencialmente conteniendo datos de impresión inflada. Google dice que las correcciones aparecerán "en las próximas semanas", y verás que las impresiones disminuyen a medida que la solución se propaga.
GSC Bug Remediation Steps
- Re-baseline sus datos de impresión. Una vez que las correcciones de Google se implementan completamente, establezca nuevas bases de referencia utilizando los datos corregidos. No compare los datos corregidos contra datos históricos no corregidos.
- Reevaluar las decisiones de optimización CTR. Si cambiaste las etiquetas de título o meta descripciones basadas en bajo CTR durante el período afectado, esos cambios pueden haber sido innecesarios.
- Informe del cliente de auditoría. Si usted ha estado reportando el crecimiento de la impresión a clientes o partes interesadas, prepare la comunicación sobre la corrección de datos y lo que significa para los números reportados anteriormente.
- Referencia cruzada con herramientas de terceros. Compare sus tendencias de impresión GSC contra herramientas de seguimiento de rangos y plataformas de análisis que miden el tráfico de forma independiente.
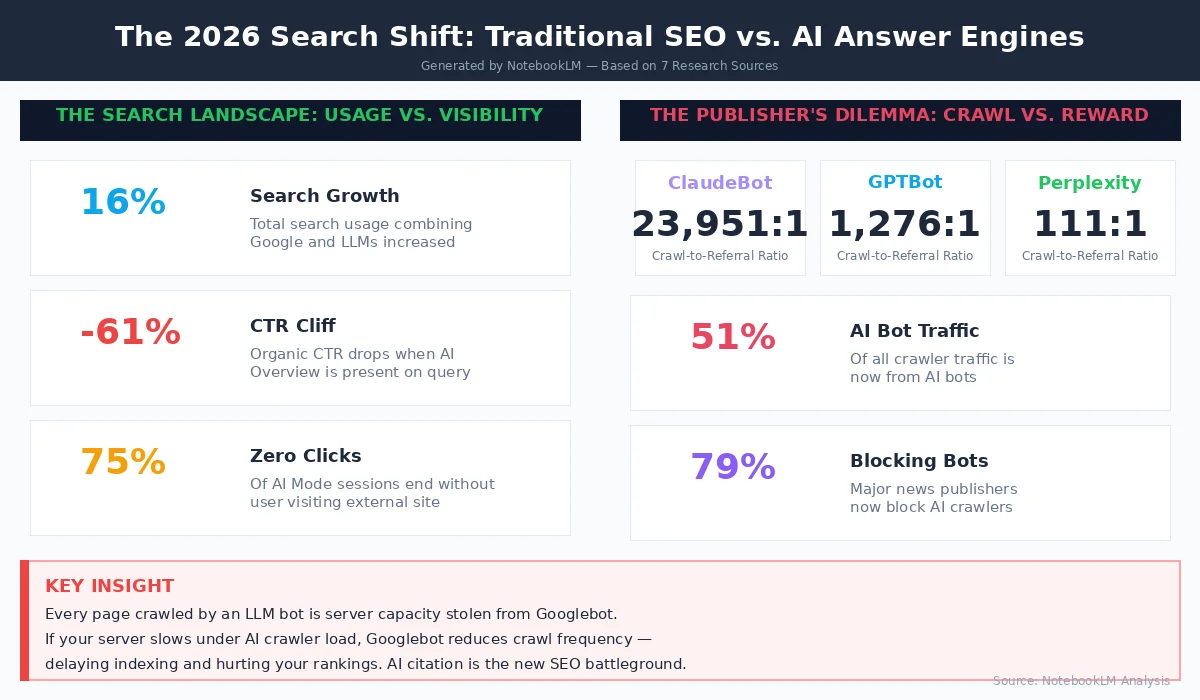
3. LLM Bots Ahora Crawl 3.6× Más que Googlebot, y ese es un problema
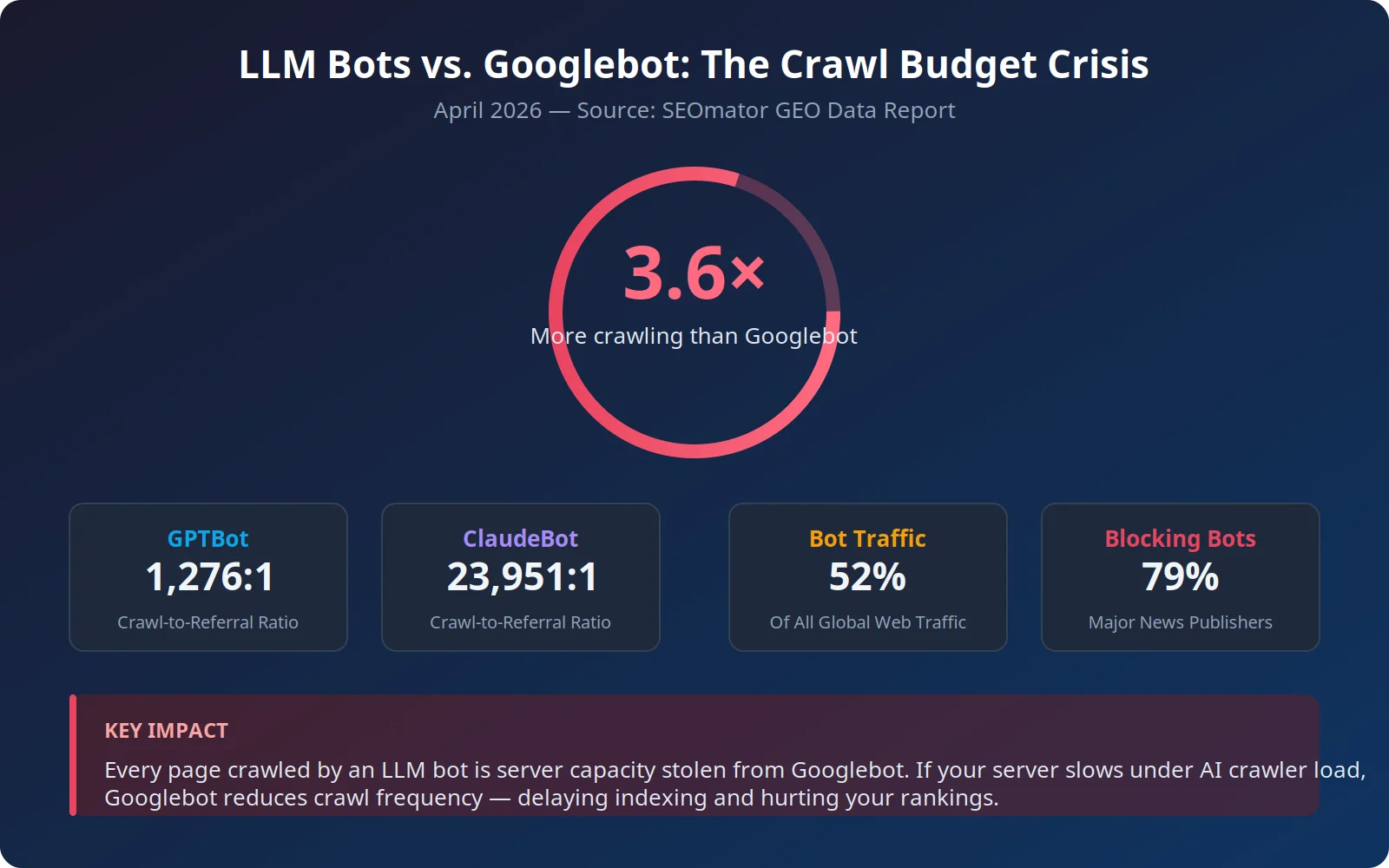
La crisis del presupuesto Crawl Cada página arrastrada por un bot LLM es la capacidad del servidor que podría haber servido a
Googlebot. Para los sitios de empresa, la situación ya es crítica: los rastreadores de IA ahora consumen hasta 40% de la actividad total de los rastreadores. Colectivamente, los bots LLM representan el 51.69% de todo el tráfico de rastreadores, superando los motores de búsqueda tradicionales (Googlebot + Bingbot + YandexBot), que se sitúan en sólo 34.46%. Cuando los rastreadores AI generan una carga excesiva, los servidores responden más lentamente, y Googlebot puede reducir su frecuencia de rastreo como resultado. Esto crea un efecto de cascada: indexación más lenta de nuevos contenidos, actualizaciones de resultados de búsqueda retardadas y rendimiento de SEO degradado, todo causado por bots que envían virtualmente cero tráfico de referencia a su sitio. Los ratios de gate-to-referral cuentan la historia completa. ClaudeBot se arrastra 23.951 páginas para cada visita de referencia que genera. La relación de GPTBot es de 1.276 a 1. ¿Y el peor delincuente? Meta-ExternalAgent, que representa el 36.10% de todo el tráfico de rastreadores AI pero ofrece un mecanismo de referencia absolutamente cero, es pura extracción sin nada a cambio.
Industry-Level Crawl Impact: Who's Subsidizing AI Training? La carga no se distribuye uniformemente en las industrias. Los sitios minoristas absorben el 20,56% de todo el tráfico de los rastreadores de IA, pero sufren los peores ratios de gate-to-referencia, subvencionando eficazmente la formación del modelo LLM con sus datos de productos y costos de infraestructura. Los sitios financieros, por el contrario, reciben las mejores tasas de referencia de IA , Perplejidad devuelve 1 referencia para cada 42 páginas arrastradas en contenido financiero, una relación dramáticamente mejor que cualquier otra vertical. Sólo DuckDuckGo consigue casi la paridad en 1.5:1 gate-to-refer, mientras que Meta y OpenAI solo representan más del 70% de todo el tráfico de rastreadores AI. Esta concentración significa que su estrategia de gestión de bots realmente se reduce a manejar sólo dos o tres jugadores principales.
The JavaScript Rendering Gap
There's an additional technical wrinkle: none of the major AI bots can currently render JavaScript. Según un
Estudio Vercel sobre el comportamiento de los rastreadores AI, OpenAI's, Antropopic's, Meta's, ByteDance's y Perplexity's, todos fallan en ejecutar JavaScript del lado del cliente. Esto significa que están arrastrando su código HTML crudo y faltando cualquier contenido que se haga dinámicamente, mientras que todavía consume sus recursos del servidor.LLM Bot Defense Strategy
- Auditoría tus registros del servidor. Identifica qué bots LLM están arrastrando tu sitio, con qué frecuencia, y qué páginas están golpeando más duro. La mayoría de los sitios se sorprenderán por el volumen.
- Implementar reglas selectivas robots.txt. Bots de entrenamiento Bloque LLM (GPTBot, CCBot, Bytespider) que proporcionan valor de referencia cero al tiempo que permite bots de búsqueda de IA que pueden citar su contenido.
- Considere la limitación de tarifas. Usar la tasa de nivel de servidor que limite las solicitudes de bot LLM por segundo sin bloquearlas directamente, preservando la posibilidad de citación de AI mientras protege el rendimiento.
- Supervisar el impacto del presupuesto de los rastreadores. Compare la frecuencia de rastreo de Googlebot antes y después de implementar restricciones de bot LLM. Puede ver el aumento de la tasa de rastreo de Googlebot a medida que la capacidad del servidor se libera.
- Adopte el estándar llms.txt. Este protocolo emergente le permite especificar qué contenido LLM bots debe priorizar, dándole más control sobre cómo su contenido es consumido por sistemas AI.
4. AI Overviews Are Crushing Organic CTR en 61%: The Survival Playbook
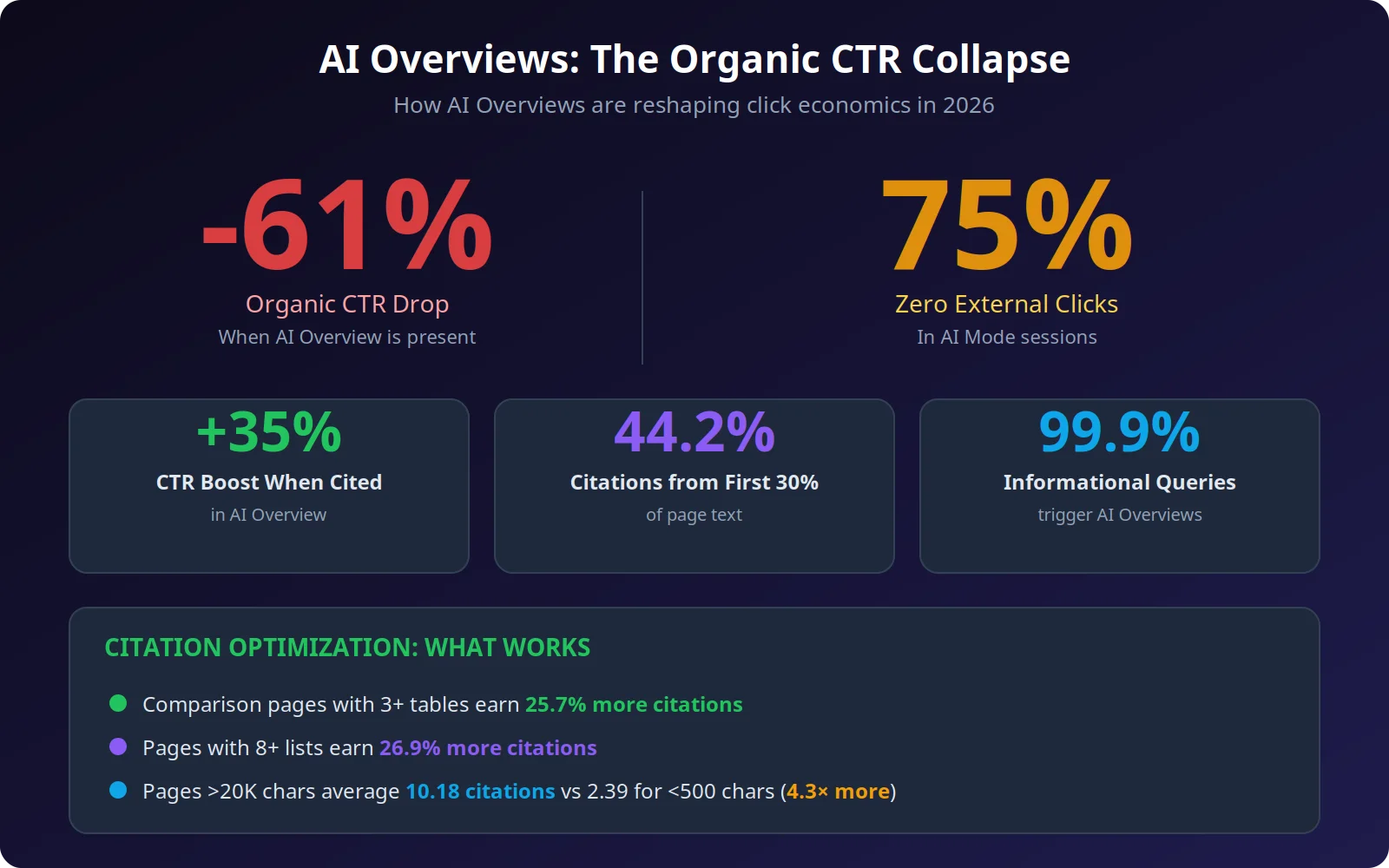
The Citation Economy
Hay un forro de plata, y es significativo: cuando su marca aparece como una cita dentro de una visión de AI, su CTR orgánico realmente aumenta en un 35%. El desafío ha pasado de la clasificación a ganar citas, y los dos requieren diferentes estrategias de optimización , una brecha que cerramos en nuestra
Programa AI SEO and compromisos de marketing de contenidos. Las investigaciones muestran que el 44.2% de todas las citas de LLM provienen del primer 30% del texto de una página. Esto significa que tu contenido introductorio tiene una influencia desproporcionada en si los sistemas AI te citan. Las páginas con tablas de comparación (tres o más) ganan 25,7% más citas, mientras que las páginas de validación con ocho o más listas ganan 26,9% más. El contenido más largo también gana: páginas superiores a 20.000 caracteres promedio 10.18 citas ChatGPT versus sólo 2.39 para páginas inferiores a 500 caracteres.The Factual Density Advantage
Here's the data point that should reshape your content strategy: a typical AI Overview-cited article covers 62% more facts than non-cited alternatives, and core sources cover 42% of key facts for their topic. En otras palabras, los sistemas AI no solo buscan contenido relevante, sino que buscan la versión más densa de la misma. Los artículos gruesos y de nivel superficial no lo cortarán aunque estén bien tradicionalmente. ### What Content Formats Win by Query Type The format that earns the most AI citations varies dramatically by query type. En todos los LLMs, los listicles son el formato más comúnmente citado en el 21,9%, aumentando a 40,86% para consultas comerciales y 43,8% en las respuestas de ChatGPT. Pero para las consultas informativas, los artículos dominan al 45.48%, una distinción crítica para la planificación de contenidos. Tal vez la información más accionable: páginas que usan 120 a 180 palabras entre encabezados reciben 70% más citas de ChatGPT en comparación con páginas con secciones bajo 50 palabras. Esto sugiere un "tamaño de cama" óptimo para contenido legible por IA, lo suficientemente detallado como para proporcionar un valor independiente, pero lo suficientemente estructurado para una extracción fácil.
Key Takeaway: Tune for Citation, Not Just Ranking
El juego SEO se ha dividido en dos pistas paralelas. Track one es la optimización de ranking tradicional para el 0.1% de las consultas informativas y todas las consultas transaccionales/navegacionales que no desencadenan Resúmenes AI. Track dos es la optimización de citas , estructurando su contenido para que los sistemas AI referencia y enlace con usted. Las marcas ganadoras en 2026 están jugando ambas pistas simultáneamente.
Cómo Ganar AI Información general Citaciones
- Cargue su experiencia. Ponga su contenido más autorizado y rico en datos en el primer 30% de la página. Los sistemas AI citan desproporcionadamente el contenido introductorio.
- Use formatos de comparación estructurados. Las páginas con tres o más tablas de comparación ganan 25.7% más citas AI. Estructura tu contenido con tablas de comparación claras y ricas en datos.
- Publicar la investigación y los datos originales. Los sistemas AI citan preferentemente fuentes primarias sobre contenido derivado. Las encuestas originales, estudios y conjuntos de datos son imanes de citación.
- Implementar el marcado de esquema completo. Los datos estructurados ayudan a los sistemas AI a comprender y extraer su contenido con precisión. Enfóquese en el artículo, FAQ, HowTo y esquema de producto.
- Construir señales de autoridad de marca. Los sistemas AI confían más marcas establecidas. Consistent publication cadence, expert author bios, and gained backlinks from authoritative domains all contribute.
- Escribe más, más contenido completo. Las páginas superiores a 20.000 caracteres ganan 4.3 veces más citas que el contenido de forma corta. La profundidad supera la brevedad en la economía de citación.
5. Nuevo GSC semanal & Vistas mensuales: Cómo utilizarlas
Aunque menos dramática que las otras historias de esta semana, la adición de Google de las vistas semanales y mensuales de agregación a los informes de resultados de Search Console es una característica realmente útil que aborda un punto de dolor de larga data para los practicantes de SEO. Anteriormente, Search Console solo mostraba datos diarios, lo que dificultaba identificar tendencias significativas sin agregación manual de datos. Fluctuaciones diarias , patrones semanales / fin de semana, picos de un solo paso de los eventos de noticias, anomalías de rastreo , creó el ruido que oscureció cambios de rendimiento real. Las nuevas vistas le permiten cambiar entre la agregación diaria, semanal y mensual directamente en la interfaz.Practical Applications
The weekly view is ideal for evaluating the impact of specific changes: a new piece of content published, a technical fix deployed, or an algorithm update rolling out. En lugar de tratar de ver las tendencias de globo a través de datos diarios marcados, se obtienen comparaciones semanales limpias. La opinión mensual tiene un propósito diferente: presentación de informes de los interesados y análisis de tendencias a largo plazo. Proporciona el tipo de datos limpios y direccionales que tiene sentido en los paneles ejecutivos y las revisiones trimestrales sin requerir que usted exporte datos a una hoja de cálculo para la agregación manual.
Nota de fecha: Dada la impresión de GSC bug discutido anteriormente, la vista mensual es especialmente útil ahora mismo. Una vez que las correcciones de impresión de Google están completamente desplegadas, la agregación mensual ayudará a suavizar la transición entre los datos dañados y corregidos, haciendo más limpio la identificación de tendencias durante este período desordenado.
6. Su plan de acción semana por semana
Así es como priorizar todo lo discutido en este artículo durante las próximas cuatro semanas:Diagnóstico y auditoría. Bandera todos los informes del GSC que abarcan mayo 2025-presentan como impresiones potencialmente infladas. Registros del servidor de auditoría para el volumen de los robots LLM. Comience segmentando sus datos de tráfico por la ventana de actualización de spam del 24 al 25 de marzo y la ventana de actualización del núcleo del 27 al 8 de abril.
Implementar la gestión de bots. Deploy selective robots.txt rules and rate limiting for LLM bots. Iniciar la auditoría E-E-A-T de las páginas de YMYL de alto tráfico. Reevaluar las decisiones de optimización de CTR tomadas entre mayo de 2025 y ahora.
Tune for AI citations. Reestructurar sus páginas de información de mayor valor a la experiencia de carga delantera y añadir tablas de comparación. Implementar o actualizar el marcado de esquemas en contenido clave. Comience a publicar investigación original o contenido basado en datos.
Medida e itinerario. Compare los datos de GSC post-corrección contra las bases de referencia pre-bug. Evaluar los cambios de frecuencia de gateo Googlebot después de las restricciones de bot LLM. Evaluar si las estrategias de recuperación de actualización básica están mostrando señales tempranas.
7. Preguntas frecuentes
¿Cuándo comenzó y terminó la actualización básica del 2026 de marzo?
La actualización básica del 2026 de marzo comenzó el 27 de marzo de 2026 a las 2:00 AM PT y terminó el 8 de abril de 2026, para un despliegue total de 12 días. Fue precedido por una actualización de spam el 24 al 25 de marzo y una actualización Discover en febrero de 2026.
¿Cuánto tiempo debo esperar antes de analizar mis datos básicos de actualización?
Google recomienda esperar al menos una semana completa después de la actualización completada (después del 15 de abril de 2026) antes de sacar conclusiones. Su período de comparación de referencia debe ser las semanas antes del 27 de marzo, medido contra el rendimiento después del 8 de abril.
¿Fue mi Consola de Búsqueda los clics afectados por el fallo de las impresiones?
No. Google confirmó que los clics y otras métricas directas no fueron afectados. Sólo los recuentos de impresión fueron sobre-reportados, que a su vez desinflaron artificialmente sus cálculos CTR. El error corrió desde el 13 de mayo de 2025 a través de la salida de la solución a partir del 3 de abril de 2026.
¿Debería bloquear todos los bots LLM en robots.txt?
No necesariamente. Un bloque de manta evita que los sistemas AI citen su contenido, lo que puede proporcionar un aumento del 35% de CTR cuando sucede. En su lugar, considere bloquear selectivamente bots de entrenamiento (GPTBot, CCBot, Bytespider) al tiempo que permite bots de búsqueda de IA que pueden conducir citas y tráfico de referencia.
¿Cómo puedo obtener mi contenido citado en AI Overviews?
Centrarse en el contenido experto de carga frontal en el primer 30% de sus páginas, utilizando tablas de comparación estructuradas, publicando investigación original, implementando el marcado de esquema completo y la autoridad de la marca de construcción. Páginas de más de 20.000 caracteres ganan 4.3 veces más citas AI que el contenido de forma corta.
¿Cuál es el estándar de llms.txt?
Similar a robots.txt para motores de búsqueda, llms.txt es un protocolo emergente que le permite especificar qué contenido LLM bots debe priorizar al arrastrar su sitio. Da a los editores más control sobre cómo los sistemas AI consumen y citan su contenido.
Mira el Recap de 60 segundos
Las cinco historias de este artículo en un minuto. Perfecto para compartir con tu equipo.
Ver el vídeo completo
Análisis extendido de los mayores desarrollos de SEO de esta semana, el límite de 2MB, guerras de comercio y actualización básica después.
Sobre el autor
 Sobre el autor
Sobre el autor Francisco Leon de Vivero
Francisco es un estratega senior de SEO y vicepresidente de crecimiento en Growing Search, con más de 15 años de experiencia en búsqueda de empresas. Anteriormente sirvió como Jefe de Plan Global SEO en Shopify de 2015 a 2022 y se centra en SEO técnico, estrategia de búsqueda internacional y optimización de plataformas.