Google Botón trasero Política de limpieza y el estudio de certificación de 815K-Page
Google añade el secuestro de botón de vuelta a las políticas de spam con un plazo de cumplimiento del 15 de junio. Más: AirOps' 815,000-page study reveals shorter content wins ChatGPT citations — retrieval rank beats domain authority, and 'ultimate guides' underperform focused articles.
Actualizado 14 de abril de 2026Francisco Leon de Vivero
Artículo archivado
Este artículo se publicó originalmente en 14 de abril de 2026 y no se ha actualizado.
Se conserva aquí como referencia histórica. Algunas herramientas, recomendaciones, detalles de algoritmos y enlaces pueden estar desactualizados o ya no ser precisos. Para orientación actual, consulta las páginas de servicio actualizadas de Francisco o reserva una consulta enfocada.
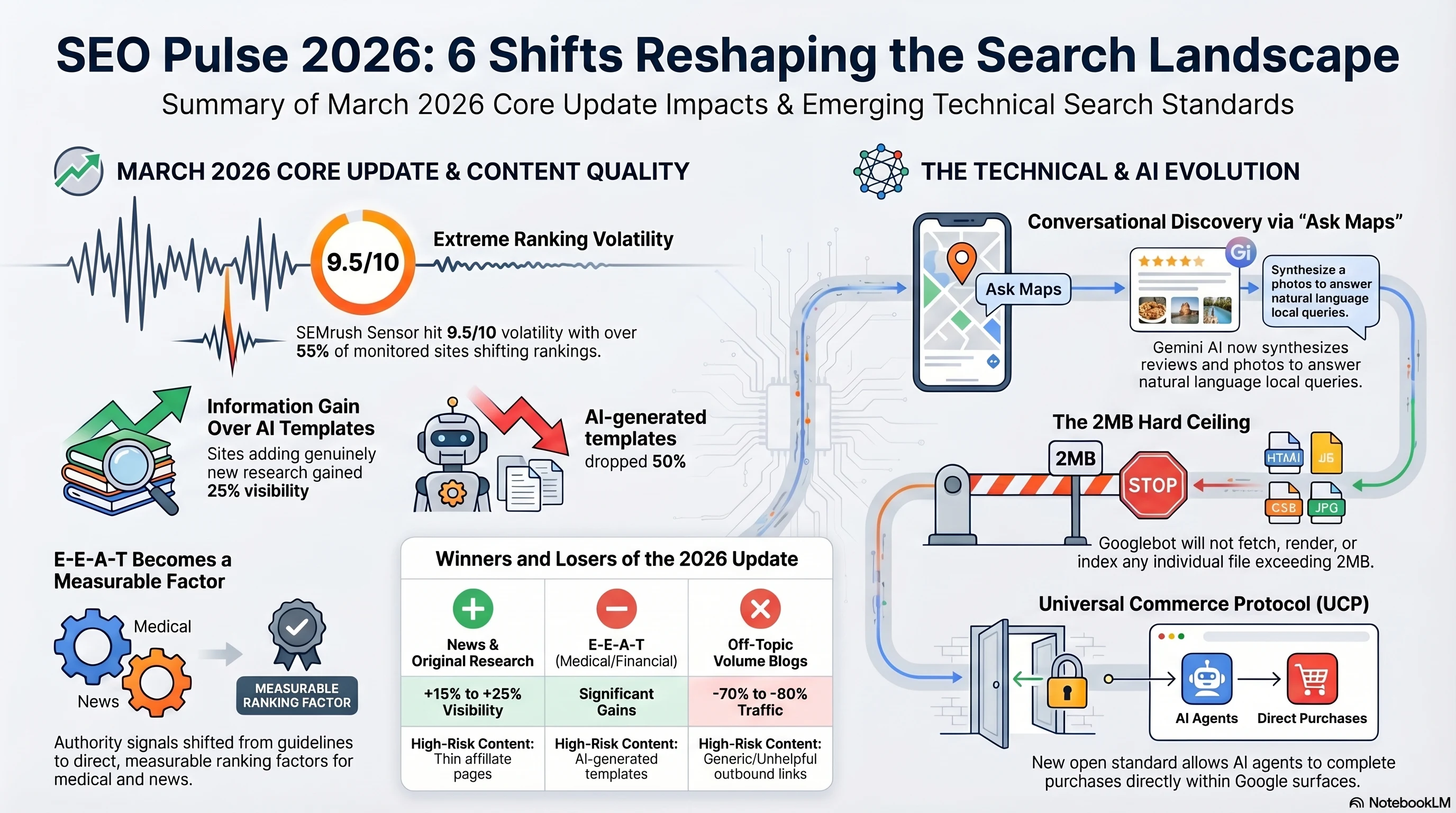
Dos historias valen entradas reales del calendario hoy. Google acaba de clasificar el secuestro de botón trasero como spam — el mismo nivel que el malware, con un plazo de cumplimiento de 15 de junio que da a los sitios exactamente 62 días para auditar cada llamada de la API de historia en sus páginas. Separadamente, AirOps publicó el mayor estudio público del comportamiento de citación de ChatGPT: 815.000 pares de páginas de consulta a través de 15.000 consultas, y los hallazgos revocan varias suposiciones sobre qué contenido se cita. Más corto tiempo. El marcador supera la autoridad de dominio. Y el 85% de las páginas que ChatGPT recupera nunca aparece en la respuesta final.
Los seis turnos conduciendo la estrategia SEO esta semana, desde la nueva política de spam de Google a los mecánicos de citas de ChatGPT.
1. Back Button Hijacking is Now Spam , Enforcement June 15
El 13 de abril de 2026, Google Search Central publicó una nueva política de spam añadiendo el secuestro del botón de atrás al "prácticas dolorosas" categoría , el mismo nivel de clasificación como distribución de malware y software no deseado. Esto no es una guía suave. Lleva sanciones de acción manual, demociones algorítmicas a través de SpamBrain, y la descalificación potencial de Google Ads.
15 de junioComienzo de la aplicación
62 díasVentana de cumplimiento
2 caminosAcciones manuales + SpamBrain
Riesgo de los anunciosVinculado a la elegibilidad desde el dic 2024
¿Qué es exactamente el secuestro del botón de atrás? El secuestro del botón de atrás ocurre cuando un sitio manipula la navegación del navegador para evitar que los usuarios regresen a la página de la que vinieron. En lugar de volver, los usuarios se redireccionan a páginas que nunca visitaron , anuncios intersticiales, redirecciones de afiliados, trampas de recomendación. El comportamiento infla las métricas de página y las impresiones de anuncios al mismo tiempo que hace que la web sea mediblemente peor para los usuarios. La definición de política de
Google es precisa: cualquier práctica donde *"un sitio interfiere con la navegación del navegador del usuario manipulando la historia del navegador u otras funcionalidades, impidiéndoles utilizar su botón de espalda."*
Los tres métodos de API de historia
Google está apuntando Las políticas nombran tres mecanismos JavaScript utilizados para el secuestro de botones:
// These are flagged when used deceptively:
historia.pushState() // Inserts fake entries into browser history
historia.replaceState() // Overwrites the current history entry
escucha del evento popstate // Intercepts back-button clicks
Las aplicaciones legítimas de una sola página utilizan estas API constantemente, React Router, Vue Router, y Next.js dependen de `pushState` para la navegación al lado del cliente. La distinción que Google dibuja es deceptive uso: insertar entradas que el usuario nunca navegaba a, o interceptar el botón de atrás para redirigir a los usuarios a páginas de monetización en lugar de su página anterior real.
El código de terceros es tu problema. Google declara explícitamente que la responsabilidad se extiende a todos los scripts en la página , incluyendo código de plataforma de anuncios, gestores de etiquetas y bibliotecas de terceros. Si el JavaScript de un vendedor secuestra el botón de atrás en su sitio, se enfrenta a la pena, no al vendedor. Un detalle auditoría técnica de la SEO es la manera más rápida de superar todos los scripts de historia antes del 15 de junio.
Dos vías de aplicación
Pathway
Mechanism
Cómo se resuelve
Acción manual de spam
Revisores humanos reducen o eliminan la visibilidad de la búsqueda
Solicitud de reconsideración después de solucionar el problema
Democión automatizada
SpamBrain algoritmos demota las páginas afectadas
Resuelve con el tiempo a medida que el cumplimiento mejora
Hay una tercera consecuencia que la mayoría de la cobertura se ha perdido: desde diciembre 2024, Google ha vinculado las acciones manuales de búsqueda de spam a Elegibilidad de Google Ads. Una acción manual para el secuestro de botones de espalda podría matar simultáneamente la visibilidad orgánica y la publicidad pagada para el dominio afectado. El radio de explosión es más amplio que cualquier actualización previa de la política de spam.
¿Quién debería estar auditando ahora mismo el blog de
Google llama a los agregadores de recetas, sitios de noticias con intersticiales, y páginas de afiliados pesados como delincuentes comunes. Pero el riesgo real es menos obvio. Cualquier sitio que ejecute múltiples redes de anuncios, scripts de afiliados o plugins de compromiso a través de un gestor de etiquetas está expuesto. Estos scripts interactúan de maneras difíciles de predecir, y un solo proveedor que inyecte llamadas "pushState" puede desencadenar la violación de la política.
Lista de comprobación de cuentas para esta semana:
Busque su base de código para history.pushState, history.replaceState, y popstate
Abrir Chrome DevTools → Aplicación → Back/forward cache → navegación de prueba en 10 páginas de alto tráfico
Revise cada script cargado a través de su administrador de etiquetas (GTM, Tealium, etc.)
Las páginas de prueba con scripts de anuncios activados , el botón de atrás siempre debe volver al árbitro
Pregunte a los vendedores de anuncios por escrito si sus scripts modifican la historia del navegador
Botón de atrás secuestro de tiempo de ejecución, anuncio del 13 de abril, fecha límite del 15 de junio, dos vías de ejecución paralelas.
Key takeaway
Tienes 62 días. Los scripts de terceros son su responsabilidad. Una acción manual puede matar tanto la clasificación orgánica como la elegibilidad de Google Ads. Iniciar la auditoría ahora, no en junio.
2. El estudio de 815K-Page: Qué contenido realmente obtiene citado por ChatGPT
AirOps publicó el mayor estudio público de los mecánicos de citación ChatGPT el 13 de abril de 2026, analizando 815.000 pares de página de consulta en 15.000 consultas, 548.534 páginas recuperadas y 82.108 citas en 10 industrias. El análisis de Kevin Indig en Growth Memo añade una segunda lente con 16.851 consultas y 353.799 páginas. Juntos, nos dan la primera imagen estadísticamente significativa de lo que gana una cita de ChatGPT, y la respuesta mejora varias suposiciones ampliamente sostenidas.
15%Páginas recuperadas que se citan
58%Tasa de certificación en posición de recuperación 0
14%Tasa de certificación en posición de recuperación 10
3.5×Ventajas de la cita: Google #1 vs. más allá 20
Encontrar #1: El rango de recuperación es la señal dominante El único predictor más fuerte de si
ChatGPT cita una página es su posición de recuperación, el orden en que la búsqueda interna de ChatGPT devuelve la página. En la posición 0, la tasa de citación es
58%. En la posición 10, cae a 14%Eso es una caída más pronunciada que la propia curva orgánica de Google CTR. La implicación práctica: El sistema de recuperación de ChatGPT se apoya fuertemente en el índice de Google. Clasificación de páginas en la cuenta 20 de Google para 55.8% de todas las citaciones de ChatGPT. Una página ranking #1 en Google tiene un 43.2% tasa de citas en ChatGPT , 3.5× más alto que las páginas ranking más allá de la posición 20. Google SEO es, contraintuitivamente, el canal de más alto uso para la visibilidad de ChatGPT. ## Finding #2: Domain authority is irrelevant Este es el resultado más contraintuitivo del estudio. AirOps encontró que DA 20-40 sitios ganado 26.0% de citas , más de 80-100 sitios en 25.4%. Las páginas de alta-DA tienen una tasa *más baja* de citas por recuperación: 15,0% versus 21.5-23,6% para DA 0-80 páginas. El resumen contundente del estudio: *"Las páginas siempre citadas tienen menor DA que las páginas nunca recitadas."* La autoridad del dominio ayuda con la recuperación , conseguir tirado en la ventana contextual de ChatGPT , pero perjudica activamente la tasa de citación una vez recuperado. ¿Por qué? Los sitios de alto nivel tienden hacia un contenido amplio y completo que diluye la pertinencia específica de la consulta. Gran marca, respuesta difusa. No se cita.
Tasas de citación de ChatGPT por posición de recuperación, autoridad de dominio y longitud de contenido, el conjunto de datos combinados de 815K-page AirOps + Growth Memo.
3. The Death of the Ultimate Guide (for AI Citations)
El hallazgo más accionable del estudio se refiere a la estructura del contenido. "Guías íntimas" completas, la estrategia de contenido que dominaba SEO de 2018 a 2024, son los intérpretes menos confiables en ChatGPT.
Tipo de contenido
Cuenta de palabras
Comportamiento de citación
Páginas siempre recitadas
500 a 2.000 palabras
Centrado, alto partido de consulta, encabezados directos
Artistas mixtos
La palabra más alta cuenta
más alto DA, pero menos confiable tasa de citación
páginas nunca recitadas
Variable
Coincidente de baja partida, amplia cobertura de temas
Páginas que abarcan 26-50% de los subtópicos fan-out de ChatGPT páginas outperform que cubren el 100%. Cubrir cada subtema agrega exhaustivamente sólo 4.6 puntos porcentuales sobre ninguno. La tesis "10x content" , que más tiempo, más contenido completo gana , es mensurablemente falso para la cita de AI. Parada completa. El perfil de contenido óptimo:
- 500 a 2.000 palabras , lo suficientemente ajustado para mantener el enfoque específico de la consulta
- 7–20 subpartidas , suficiente estructura para la recuperación, no tanto diluye relevancia
- Direcciones que responden directamente a la consulta , las páginas con el partido de la partida 0,90+ alcanzan la tasa de citación 41% versus 30% inferior a 0,50
- Una pregunta, una mejor respuesta , no respuestas adecuadas a veinte preguntas tangenciales
La excepción de Wikipedia: Wikipedia consigue una tasa de citación del 59% a pesar de un rango de recuperación mediana de 24 y la puntuación más baja del partido de consulta (0.576). Indemniza con cobertura estructurada exhaustiva, 4,383 palabras promedio, 31 listas, 6,6 cuadros por artículo. Esto funciona porque la escala y la estructura de Wikipedia son únicas. Para todos los demás, victorias más cortas y enfocadas.
La muerte de la guía final , centró 500–2.000 páginas de palabras con encabezados alineados con la consulta superan la forma completa de la citación AI.
4. Fan-Out Queries: El canal de descubrimiento oculto
Uno de los hallazgos más importantes del estudio para los estrategas de contenido es cómo ChatGPT realmente encuentra contenido. Cuando un usuario hace una pregunta a ChatGPT, el sistema no sólo busca esa consulta. Genera fan-out subqueries , versiones descompuestas, reformuladas de la pregunta original, y busca cada una de forma independiente. Los números son llamativos:
- 89.6% de búsquedas de ChatGPT desencadenan 2 + consultas de fans
- 32.9% de páginas citadas se descubren sólo a través de fan-out , no la consulta original
- 95% de las consultas de fans tienen cero volumen de búsqueda mensual en las herramientas de palabras clave tradicionales Un tercio de las citas de ChatGPT van a páginas que nunca aparecen en un flujo de trabajo de investigación de palabras clave. El sistema de recuperación interna de ChatGPT descompone preguntas de maneras que no mapean cómo los humanos buscan en Google. Una página sobre "mejor CRM para las organizaciones sin fines de lucro" podría ser citada en respuesta a "cómo una pequeña caridad gestionar las relaciones con los donantes" , a través de una consulta fan-out que el creador de contenido nunca apuntaba. Esto es, aparentemente, cómo funciona el descubrimiento de contenido en 2026.
Fan-out behaviour varies by intent
Tipo de consulta
Comportamiento de Fan-out
Tasa de citación
Sensibilización del producto
Se expande en subcuestiones de características/beneficios
18.3%
How-to
42.6% cerca de la palabra, descanso descompuesto en pasos
16.9%
Comparison
38.4% dividido en subcuestiones por opción
13.1%
Validation
40.6% cerca de la palabra
11.3%
El descubrimiento de productos y las consultas tienen las mayores tasas de citación. Consultas de comparación y validación , donde ChatGPT está tratando de confirmar o contrastar , citar menos fuentes, en parte porque el modelo tiene mayor confianza interna en las afirmaciones de hecho que puede hacer referencia cruzada.
Las consultas de fans como el canal de descubrimiento oculto, un tercio de las citas de ChatGPT provienen de sub-queries invisibles a herramientas de investigación de palabras clave.
5. Alineación Título-Query: El elevador de Citación 2.2×
AirOps midió la superposición de títulos, el porcentaje de palabras de consulta que aparecen en la etiqueta de título de la página, y encontró una relación lineal limpia con las tasas de citación:
Recaída de la matrícula
Tasa de citación
50%+ superposición
20.1%
<10% de superposición
9.3%
Eso es un 2.2× ascensor desde la alineación de título más fuerte, sin cambiar ninguna otra variable. Y no se detiene en el `etiqueta. Los encabezados H1 y H2 funcionan como señales relevantes durante la recuperación también. La métrica de la partida de Kevin Indig lo confirma: páginas con 0.90+ encabezados semejanza cosine a la consulta alcanzan tasas de citación del 41% frente al 30% para páginas inferiores a 0.50. El mecanismo es sencillo: el sistema de recuperación de ChatGPT utiliza el texto de encabezado como una señal de relevancia primaria, similar a cómo Google utiliza etiquetas de título para clasificar pero con aún más peso. Páginas cuyos epígrafes *son* la consulta , o parafrases cercanos , se citan. Páginas con titulares inteligentes y ajustados que no contienen los términos de consulta se recuperan y luego se descartan. <div class="pulse4-callout">
<p><strong>Implicación práctica:</strong> Si optimizas por citas de IA junto a la clasificación de Google, utiliza encabezados descriptivos sobre encabezados inteligentes. "Cómo migrar desde Shopify a WooCommerce" superará "The Ultimate Platform Switch Guide" en la cita de ChatGPT cada vez, incluso si el segundo título gana más clics en Google.</p>
</div> <div class="pulse4-image">
<figure>
<img src="/assets/images/posts/back-button-chatgpt/section-5-title-query-alignment.webp?v=2" alt="Infographic showing title-query overlap vs citation rate: 50%+ overlap yields 20.1% citation rate versus 9.3% for under 10% overlap , a 2.2× lift" width="1600" height="900" loading="lazy">
<figcaption>La alineación de la serie de títulos conduce a un elevador de citación 2.2×, los encabezados descriptivos golpearon a los inteligentes en la recuperación de ChatGPT.</figcaption>
</figure>
</div> <h2 id="q2-strategy">6. Lo que significa estrategia de contenido en Q2 2026</h2> Los datos de AirOps crean un tenedor claro en la estrategia de contenido. Google y ChatGPT ahora premian significativamente diferentes estructuras de contenido, y la brecha se está ampliando a medida que el sistema de recuperación de ChatGPT madura. Elige a tu público. Construye para ello deliberadamente. <h3>For Google organic rankings</h3><p>- Full coverage still works , topical authority matters - Backlinks and domain authority remain solid ranking signals - Long-form content (2,000-5,000 words) performs well for competitive head terms - E-E-A-T signals (author credentials, citations, experience demonstrations) are weighted heavily ### For ChatGPT citations - Focused, single-topic pages (500-2,000 words) outperform full guides - Domain authority is irrelevant , retrieval rank and heading match dominate - Descriptive, query-matching headings lift citation rates 2.2× - Moderate subtopic coverage (26-50%) beats exhaustive coverage - Google ranking is still the primary input , 55.8% of ChatGPT citations come from Google top-20 pages The resolution isn't to choose one or the other. Build</p><strong>páginas de concentrado</strong> , un solo tema, 1000-1,500 páginas de palabras con encabezados precisos , y vincularlos a grupos de temas más amplios. Las páginas centrales sirven <a href="/es/ai-seo/">ChatGPT y AI cita de búsqueda</a>. El cluster sirve a Google autoridad tópica a través de disciplina <a href="/es/content-marketing/">estrategia de contenido</a>. Ambos se benefician de la clasificación de Google, que sigue siendo la entrada común para ambos sistemas. Para una lectura de la fuente primaria, la totalidad <a href="https://www.airops.com/report/influence-of-retrieval-fanout-and-google-serps-in-chatgpt" target="_blank" rel="noopener">AirOps 815K-page citation study</a> vale la pena trabajar. <div class="pulse4-image">
<figure>
<img src="/assets/images/posts/back-button-chatgpt/section-6-q2-2026-content-strategy.webp?v=2" alt="Infographic contrasting Google-optimized content (long-form, high DA, backlinks) with ChatGPT-optimized content (focused 500–2,000 word hubs, heading match, moderate coverage) for Q2 2026 content strategy" width="1600" height="900" loading="lazy">
<figcaption>Q2 2026 estrategia de contenido , páginas centrales enfocadas para la cita de ChatGPT, vinculadas a grupos más amplios para la autoridad tópica de Google.</figcaption>
</figure>
</div> <h2 id="compliance">7. El Calendario de Cumplimiento: Qué hacer esta semana</h2> <h3 id="back-button-hijacking-audit-deadline-june-15">Botón de seguridad de la auditoría de secuestro (deadline: 15 de junio)</h3>
1. <strong>Día 1:</strong> Grep your JavaScript for `history.pushState`, `history.replaceState`, and `popstate`. Bandera de todos los casos.
2. <strong>Día 2:</strong> Administrador de etiquetas de auditoría contenedores , exportar todas las etiquetas, buscar la manipulación de la historia en scripts de anuncios, scripts de afiliados y plugins de compromiso.
3. <strong>Día 3:</strong> Pruebe las 20 páginas de tráfico más alta manualmente: haga clic a través de Google, luego haga clic en atrás. Si no aterrizas en Google, tienes una violación.
4. <strong>Día 4-5:</strong> Contacta con los proveedores que ejecutan scripts ofensivos. Obtener la eliminación o fijar los plazos por escrito.
5. <strong>Semana 2:</strong> Deploy fixes, re-test, document compliance for potential reconsideration request. <h3>ChatGPT citación optimización (en curso) 1. Identifica tus 20 páginas principales por el ranking de</h3><p>Google. Estos son tus candidatos de citación ChatGPT de mayor probabilidad. 2. Reescribir las partidas H1 y H2 para que coincidan directamente con las consultas que desea ser citado para. 3. Si cualquier página excede las 3.000 palabras, considere dividirlo en páginas temáticas específicas. 4. Añada datos estructurados (esquema FFAQ, HowTo schema) para mejorar las señales de recuperación. 5. Monitor ChatGPT citaciones utilizando herramientas como Otterly.ai o pruebas manuales, busque su marca y temas clave en ChatGPT semanal.</p><div class="post-related">
<h2>Artículos relacionados</h2>
<ul>
<li><a href="/es/insights/core-update-ask-maps/">Marzo 2026 Actualización básica Aftermath, Pregunte Mapas Revolución, y el Error GSC de 11 meses</a><span class="post-related__meta">Abril 14, 2026 , Búsqueda local AI + recuperación GSC</span></li>
<li><a href="/es/insights/2mb-agentic-commerce/">El 2MB Cutoff de Googlebot, la carrera de armas de comercio, y quién Won the March Core Update</a><span class="post-related__meta">Abril 13, 2026 , Límites Crawl + UCP vs OpenAI</span></li>
<li><a href="/es/insights/core-update-gsc-llm/">Abril 2026: Actualización básica Aftermath, el GSC Impresions Bug, y por qué LLM Bots Ahora fuera de Crawl Googlebot</a><span class="post-related__meta">12 de abril de 2026, tendencias de los rastreadores de LLM</span></li>
</ul>
</div> <h2 id="faq">8. Preguntas frecuentes</h2> <div class="pulse4-faq"> <div class="pulse4-faq-item">
<h4>¿Cuál es la nueva política de spam de Google?</h4>
<p>Anunciado Abril 13, 2026, Google ahora clasifica el secuestro del botón de atrás como spam bajo su categoría "prácticas dolorosas", el mismo nivel que la distribución del malware. Sitios que manipulan la historia del navegador mediante JavaScript ( <code>history.pushState</code>, <code>history.replaceState</code>, <code>popstate</code> oyentes) para evitar que los usuarios navegan hacia atrás enfrentarán acciones manuales o demociones algorítmicas a través de SpamBrain. La ejecución comienza el 15 de junio de 2026.</p>
</div> <div class="pulse4-faq-item">
<h4>¿Qué métodos de API de la historia cubre la política de secuestro de botones traseros?</h4>
<p>Google flags de uso engañoso de <code>historia.pushState()</code>, <code>historia.replaceState()</code>, y <code>popstate</code> oyentes del evento. Cualquier script , incluyendo bibliotecas de anuncios de terceros y gestores de etiquetas , que inserta entradas falsas en la historia del navegador o intercepta clics de back-button para redirigir usuarios a páginas no visitadas viola la política. Los dueños del sitio son responsables incluso cuando el código del delito viene de proveedores externos.</p>
</div> <div class="pulse4-faq-item">
<h4>¿Cuántas páginas recupera ChatGPT contra cita?</h4>
<p>AirOps analizó 548.534 páginas recuperadas por ChatGPT a través de 15.000 consultas y encontró sólo el 15% fueron citados en respuestas finales. 58% de las páginas recuperadas nunca se citan, 25% siempre se citan cuando se recuperan, y 17% caen entre. El estudio produjo 82.108 citas totales para análisis.</p>
</div> <div class="pulse4-faq-item">
<h4>¿Importa la autoridad de dominio para citas de ChatGPT?</h4>
<p>No. AirOps encontró autoridad de dominio es irrelevante para ChatGPT cita probabilidad. DA 20-40 sitios ganaron 26.0% de citas versus 25.4% para DA 80-100 sitios. Las páginas de alta-DA en realidad tenían una tasa de citas por recuperación inferior (15,0%) en comparación con DA 0-80 páginas (21,5-23,6%). El rango de recuperación y la alineación en el encabezado son predictores mucho más fuertes.</p>
</div> <div class="pulse4-faq-item">
<h4>¿Cuál es la longitud y estructura óptimas de contenido para las citas de ChatGPT?</h4>
<p>Las páginas entre 500 y 2.000 palabras con 7-20 subpartidas funcionan mejor. Los "guías íntimas" son los intérpretes menos fiables. Cubrir el 26-50% de los subtópicos fan-out de ChatGPT que cubren el 100%. Los titulares deben coincidir directamente con la consulta , las páginas con el partido de la partida 0.90+ lograr una tasa de citas del 41% frente al 30% para las páginas inferiores a 0.50.</p>
</div> <div class="pulse4-faq-item">
<h4>¿Qué son las consultas de fans en ChatGPT y por qué importan para SEO?</h4>
<p>Las consultas Fan-out son sub-queries ChatGPT genera desde la pregunta original del usuario para recopilar información desde múltiples ángulos. 89.6% de las búsquedas disparan 2+ consultas de fans, y el 32,9% de las páginas citadas se descubren sólo a través de fan-out, no la consulta original. El 95% de las consultas de fans tienen un volumen de búsqueda mensual cero, lo que significa que la investigación de palabras clave tradicionales las extraña por completo.</p>
</div> <div class="pulse4-faq-item">
<h4>¿Cómo correlaciona el ranking de SERP de Google con citas de ChatGPT?</h4>
<p>Las 20 páginas de SERP de Google representan el 55,8% de todas las citas de ChatGPT. Páginas ranking #1 en Google son citados por ChatGPT 43.2% del tiempo , una ventaja de 3.5× sobre páginas ranking más allá de la posición 20. Google SEO sigue siendo el canal de más alto uso para la visibilidad de ChatGPT.</p>
</div> </div> <h2 id="about-the-author">Sobre el autor</h2> <div class="prose-author">
<img class="prose-author__image" src="/assets/images/francisco/francisco-conference.jpg" alt="Francisco Leon de Vivero at an industry conference">
<div class="prose-author__body">
<p class="eyebrow">Sobre el autor</p>
<h3>Francisco Leon de Vivero</h3>
<p>Francisco es un experto mundial en SEO y VP de Crecimiento en Growing Search con más de 15 años de experiencia en toda la empresa, comercio electrónico y búsqueda internacional. Ex Jefe de Plan Global SEO en Shopify, ahora ayuda a las marcas y equipos de comercio electrónico a construir una estrategia SEO de alto nivel. Ponente en UnGagged, SEonthebeach y Quondos. Publicado en Forbes y Huffington Post. Juzgado para premios canadienses y europeos de búsqueda.</p>
<p class="prose-author__links">
<a href="https://www.linkedin.com/in/seofrancisco/" target="_blank" rel="noopener">LinkedIn</a>
<a href="https://www.youtube.com/c/SEOFrancisco/videos" target="_blank" rel="noopener">YouTube</a>
<a href="/es/consultation/">Reserva una consulta</a>
</p>
</div>
</div>
</div>
<div class="post-next-steps">
<div class="section-heading post-next-steps__heading">
<p class="eyebrow">Siguiente paso</p>
<h2>Convierte esta lectura en un plan SEO más actual.</h2>
<p>Usa la página actual más relevante si este tema sigue en tu roadmap, y revisa las pruebas y rutas de contacto si quieres apoyo directo.</p>
</div>
<div class="path-grid">
<article class="path-card path-card--accent path-card--service card-with-mark">
<div class="service-mark" aria-hidden="true">
<svg viewBox="0 0 64 64" aria-hidden="true" focusable="false">
<defs>
<linearGradient id="grad-tech" x1="0%" y1="0%" x2="100%" y2="100%">
<stop offset="0%" stop-color="#23b7ff" />
<stop offset="100%" stop-color="#1a6fff" />
</linearGradient>
</defs>
<rect x="17" y="17" width="30" height="30" rx="9" fill="url(#grad-tech)" />
<path d="M24 28h16M24 36h11" fill="none" stroke="#fff" stroke-width="4.5" stroke-linecap="round" />
<circle cx="44" cy="36" r="4" fill="#ff9e3d" />
</svg>
</div>
<p class="audience-card__kicker">Página de servicio actual</p>
<h3><a href="/es/technical-seo-advisory/">Technical SEO Advisory</a></h3>
<p>El objetivo no es la comprobación de cuentas. Está traduciendo cuestiones técnicas complejas en acciones prioritarias que los equipos de desarrollo y marketing pueden ejecutar realmente.</p>
<a class="text-link" href="/es/technical-seo-advisory/">Explorar este servicio</a>
</article>
<article class="path-card">
<p class="audience-card__kicker">Experiencia</p>
<h3><a href="/es/experience/">Ver la prueba detrás del asesoramiento.</a></h3>
<p>Revisa la experiencia de Francisco en plataformas, charlas, premios, jurados y liderazgo antes de contactarlo.</p>
<a class="text-link" href="/es/experience/">Revisar experiencia</a>
</article>
<article class="path-card">
<p class="audience-card__kicker">Contacto</p>
<h3><a href="/es/consultation/#cal-inline-embed">Inicia una consulta enfocada.</a></h3>
<p>Usa la página de consulta si quieres convertir este tema en prioridades claras, próximos pasos y avance SEO medible.</p>
<a class="text-link" href="/es/consultation/#cal-inline-embed">Reservar consulta</a>
</article>
</div>
</div>
</div>
<aside class="post-sidebar">
<div class="sticky-card sticky-card--service card-with-mark">
<div class="service-mark" aria-hidden="true">
<svg viewBox="0 0 64 64" aria-hidden="true" focusable="false">
<defs>
<linearGradient id="grad-tech" x1="0%" y1="0%" x2="100%" y2="100%">
<stop offset="0%" stop-color="#23b7ff" />
<stop offset="100%" stop-color="#1a6fff" />
</linearGradient>
</defs>
<rect x="17" y="17" width="30" height="30" rx="9" fill="url(#grad-tech)" />
<path d="M24 28h16M24 36h11" fill="none" stroke="#fff" stroke-width="4.5" stroke-linecap="round" />
<circle cx="44" cy="36" r="4" fill="#ff9e3d" />
</svg>
</div>
<p class="eyebrow">Ruta actual del tema</p>
<h2>Technical SEO Advisory</h2>
<p>Soporte técnico de SEO para equipos que se ocupan de la rastreabilidad, indexación, migraciones, estructura del sitio, renderización, Vitales de Core Web y atrasos de ingeniería.</p>
<a class="button button--secondary" href="/es/technical-seo-advisory/">Explorar página actual</a>
</div>
<div class="sticky-card author-card">
<div class="author-card__image">
<picture><source type="image/webp" srcset="/assets/optimized/bTHSfTn-Ag-240.webp 240w, /assets/optimized/bTHSfTn-Ag-360.webp 360w, /assets/optimized/bTHSfTn-Ag-480.webp 480w" sizes="14rem"><img src="/assets/optimized/bTHSfTn-Ag-240.jpeg" alt="Francisco Leon de Vivero" loading="lazy" decoding="async" width="480" height="508" srcset="/assets/optimized/bTHSfTn-Ag-240.jpeg 240w, /assets/optimized/bTHSfTn-Ag-360.jpeg 360w, /assets/optimized/bTHSfTn-Ag-480.jpeg 480w" sizes="14rem"></picture>
</div>
<p class="eyebrow">Sobre Francisco</p>
<h2>Francisco Leon de Vivero</h2>
<p>VP de Growth en Growing Search y experto global en SEO con más de 15 años de experiencia en Shopify, enterprise SEO, programas internacionales, jurado de premios y conferencias.</p>
<ul class="feature-list feature-list--compact">
<li>Ex Head of Global SEO Framework en Shopify</li>
<li>VP of Growth en Growing Search</li>
<li>Speaker, educador y jurado de premios de búsqueda</li>
<li>Enfoque en SEO técnico, internacional y orientado a crecimiento</li>
</ul>
<a class="button button--secondary" href="/es/about/">Ver perfil completo</a>
</div>
<div class="sticky-card">
<p class="eyebrow">¿Necesitas ayuda experta?</p>
<h2>Convierte estos insights SEO en un plan de acción.</h2>
<p>Reserva una hora enfocada si quieres convertir estas ideas en prioridades claras y progreso SEO medible.</p>
<a class="button button--primary" href="/es/consultation/#cal-inline-embed">Reserva una Consulta de $200</a>
<a class="button button--ghost" href="/es/case-studies/">Ver casos de estudio</a>
</div>
<div class="sticky-card">
<p class="eyebrow">Leer después</p>
<ul class="related-posts">
<li>
<a href="/es/insights/faq-schema-ai-pivot/">Google Killed FAQ Resultados ricos: El tiempo completo y por qué Schema ahora sirve AI, no SERPs</a>
<span>13 de mayo de 2026</span>
</li>
<li>
<a href="/es/insights/openai-crawl-gpt5-ai-overviews-seo/">OpenAI Crawl Activity Triples Post-GPT-5 Mientras que AI Resúmenes Cortar los clics orgánicos 38% ← SEO Data Briefing</a>
<span>30 de abril de 2026</span>
</li>
<li>
<a href="/es/insights/openai-web-crawl-seo-study/">OpenAI Tripled Its Web Crawl: What the 7-Billion Log File Study Means for Your SEO</a>
<span>28 de abril de 2026</span>
</li>
</ul>
<a class="text-link" href="/es/blog/">Ver todos los artículos</a>
</div>
</aside>
</div>
</article>
</main>
<footer class="site-footer">
<div class="container site-footer__grid">
<div class="site-footer__intro">
<p class="footer-kicker">SEO Francisco</p>
<h2 class="site-footer__title"><span class="site-footer__title-line">Francisco</span>Leon de Vivero</h2>
<p class="site-footer__lede">Francisco lidera crecimiento en Growing Search y ayuda a las marcas a conectar SEO técnico, visibilidad internacional, sistemas de contenido y resultados de negocio medibles.</p>
<div class="footer-pill-row">
<span class="footer-pill">VP de Growth en Growing Search</span>
<span class="footer-pill">Oficinas en Toronto y Montreal</span>
<span class="footer-pill">Más de 15 años en SEO</span>
<span class="footer-pill">SEO técnico, Shopify e internacional</span>
</div>
</div>
<div class="site-footer__panel site-footer__panel--explore">
<p class="footer-kicker">Explorar</p>
<div class="site-footer__stack">
<div class="site-footer__group">
<p class="site-footer__subhead">Navegación</p>
<ul class="footer-list footer-list--primary">
<li><a href="/es/services/">Servicios</a></li>
<li><a href="/es/industries/">Industrias</a></li>
<li><a href="/es/case-studies/">Casos</a></li>
<li><a href="/es/tools/">Herramientas</a></li>
<li><a href="/es/blog/">Blog</a></li>
<li><a href="/es/about/">Sobre mí</a></li>
<li><a href="/es/contact/">Contacto</a></li>
</ul>
</div>
<div class="site-footer__group">
<p class="site-footer__subhead">Servicios</p>
<div class="footer-service-grid">
<a class="footer-service-link" href="/es/international-seo/">SEO internacional</a>
<a class="footer-service-link" href="/es/technical-seo-advisory/">Asesoría técnica SEO</a>
<a class="footer-service-link" href="/es/shopify-seo/">Shopify SEO</a>
<a class="footer-service-link" href="/es/toronto-seo-consultant/">Consultor SEO en Toronto</a>
<a class="footer-service-link" href="/es/ai-seo/">SEO para IA</a>
<a class="footer-service-link" href="/es/ai-seo-audit/">Auditoría SEO para IA</a>
<a class="footer-service-link" href="/es/content-marketing/">Marketing de contenidos</a>
<a class="footer-service-link" href="/es/link-building/">Link Building</a>
<a class="footer-service-link" href="/es/online-reputation-management/">Reputación online</a>
<a class="footer-service-link" href="/es/youtube-seo/">YouTube SEO</a>
<a class="footer-service-link" href="/es/growth-accelerator-team/">Growth Accelerator Team</a>
</div>
</div>
</div>
</div>
<div class="site-footer__panel">
<p class="footer-kicker">Contacto</p>
<ul class="footer-list">
<li><a href="#" data-chat-toggle>Chat con Sophie</a></li>
<li><a href="https://wa.me/16474930660" target="_blank" rel="noreferrer">WhatsApp</a></li>
<li><a href="/es/consultation/#cal-inline-embed">Reserva una Consulta de $200</a></li>
<li><a href="https://www.growingsearch.com/" target="_blank" rel="noreferrer">Growing Search</a></li>
<li><a href="/es/blog/">Blog y artículos</a></li>
<li><a href="https://ca.linkedin.com/company/growingsearch" target="_blank" rel="noreferrer">LinkedIn</a></li>
<li><a href="tel:+16474930660">+1 647 493 0660</a></li>
</ul>
</div>
<div class="site-footer__panel">
<p class="footer-kicker">Oficinas</p>
<ul class="footer-list footer-list--offices">
<li>
<strong>Toronto</strong>
<span>240 Richmond Street W, Toronto, ON Canada M5V 1V6</span>
</li>
<li>
<strong>Montreal</strong>
<span>1275 Avenue Des Canadiens-De-Montreal L'Avenue, Montreal, Quebec H3B 0G4</span>
</li>
</ul>
</div>
</div>
<div class="container site-footer__meta">
<p>Reserva una consulta SEO enfocada de $200 o explora soporte de crecimiento más amplio con Growing Search.</p>
<p>Toronto y Montreal, Canadá</p>
<a href="/llm.txt" class="site-footer__sitemap-link">LLM.txt</a>
<a href="/es/sitemap/" class="site-footer__sitemap-link">Mapa del sitio</a>
</div>
</footer>
<div class="chat-dock" data-chat-dock>
<section class="chat-panel" id="site-chat-panel" data-chat-panel hidden aria-labelledby="site-chat-title">
<div class="chat-panel__header">
<div>
<p class="chat-panel__eyebrow">SEO Francisco</p>
<h2 id="site-chat-title">Contactar a Francisco</h2>
</div>
<button class="chat-panel__close" type="button" data-chat-close aria-label="Cerrar chat">Cerrar</button>
</div>
<div class="chat-thread" data-chat-thread aria-live="polite" aria-atomic="false"></div>
<form class="chat-form" data-chat-form>
<label class="sr-only" for="site-chat-input">Respuesta del chat</label>
<input class="chat-form__input" id="site-chat-input" data-chat-input type="text" autocomplete="off" placeholder="Escribe tu respuesta">
<div class="chat-form__actions">
<button class="button button--primary" type="submit" data-chat-submit>Enviar</button>
<button class="button button--ghost chat-form__restart" type="button" data-chat-restart hidden>Empezar de nuevo</button>
</div>
<p class="chat-form__help" data-chat-help>Este chat recopila tu nombre, email y mensaje antes de enviar la consulta.</p>
<p class="chat-form__status" data-chat-status aria-live="polite"></p>
</form>
</section>
</div>
<aside class="sophie-scroll-card" data-sophie-scroll-card aria-label="Chat con Sophie" hidden>
<button class="sophie-scroll-card__close" type="button" data-sophie-scroll-dismiss aria-label="Minimizar invitación de chat de Sophie">×</button>
<div class="sophie-scroll-card__media">
<img src="/assets/images/sophie/sophie-chat-openart-low-blue.webp" alt="Sophie, asistente de chat de SEO Francisco" width="1792" height="1008" loading="lazy" decoding="async">
<span class="sophie-scroll-card__call" aria-hidden="true">
<svg viewBox="0 0 24 24" focusable="false"><path d="M22 16.92v3a2 2 0 0 1-2.18 2 19.79 19.79 0 0 1-8.63-3.07 19.5 19.5 0 0 1-6-6A19.79 19.79 0 0 1 2.12 4.18 2 2 0 0 1 4.11 2h3a2 2 0 0 1 2 1.72c.12.9.32 1.77.59 2.61a2 2 0 0 1-.45 2.11L8 9.69a16 16 0 0 0 6.31 6.31l1.25-1.25a2 2 0 0 1 2.11-.45c.84.27 1.71.47 2.61.59A2 2 0 0 1 22 16.92Z"/></svg>
</span>
</div>
<div class="sophie-scroll-card__body">
<p>¿Necesitas una respuesta SEO rápida?</p>
<div class="sophie-scroll-card__actions" aria-label="Opciones de contacto">
<button class="sophie-scroll-card__cta" type="button" data-chat-toggle data-sophie-scroll-cta aria-controls="site-chat-panel" aria-expanded="false">
<svg viewBox="0 0 24 24" aria-hidden="true" focusable="false"><path d="M21 15a2 2 0 0 1-2 2H8l-5 4V5a2 2 0 0 1 2-2h14a2 2 0 0 1 2 2z" fill="none" stroke="currentColor" stroke-width="2" stroke-linecap="round" stroke-linejoin="round"/></svg>
Chatear con Sophie
</button>
<a class="sophie-scroll-card__cta sophie-scroll-card__cta--whatsapp" href="https://wa.me/16474930660" target="_blank" rel="noreferrer" data-sophie-scroll-dismiss-link>
<svg viewBox="0 0 24 24" aria-hidden="true" focusable="false"><path d="M17.47 14.38c-.3-.15-1.76-.87-2.03-.97-.27-.1-.47-.15-.67.15s-.77.97-.94 1.17c-.17.2-.35.22-.65.07-.3-.15-1.26-.46-2.4-1.48-.89-.79-1.49-1.77-1.66-2.07-.17-.3-.02-.46.13-.61.14-.14.3-.35.45-.52.15-.17.2-.3.3-.5.1-.2.05-.37-.02-.52-.08-.15-.67-1.61-.92-2.2-.24-.58-.49-.5-.67-.51h-.57c-.2 0-.52.07-.8.37-.27.3-1.04 1.02-1.04 2.49s1.06 2.88 1.21 3.08c.15.2 2.1 3.2 5.08 4.49.71.31 1.26.49 1.69.63.71.23 1.36.2 1.87.12.57-.09 1.76-.72 2.01-1.41.25-.7.25-1.29.17-1.41-.07-.13-.27-.2-.57-.35zM12.05 21.78c-1.79 0-3.55-.48-5.08-1.39l-.36-.22-3.78.99 1.01-3.69-.24-.38A9.82 9.82 0 0 1 2.2 12.05c0-5.46 4.45-9.9 9.91-9.9a9.83 9.83 0 0 1 7 2.9 9.82 9.82 0 0 1 2.9 7c-.01 5.46-4.45 9.9-9.91 9.9l-.05-.17zM12.05 0C5.44 0 .1 5.34.1 11.92a11.87 11.87 0 0 0 1.6 5.97L0 24l6.3-1.65a11.9 11.9 0 0 0 5.69 1.45h.05C18.64 23.8 24 18.46 24 11.92 24 5.34 18.66 0 12.05 0z" fill="currentColor"/></svg>
WhatsApp
</a>
</div>
</div>
<button class="sophie-scroll-card__mini" type="button" data-sophie-scroll-restore aria-label="Restaurar opciones de contacto de Sophie">
<span class="sophie-scroll-card__mini-avatar">
<img src="/assets/images/sophie/sophie-chat-openart-low-blue.webp" alt="" width="96" height="96" loading="lazy" decoding="async">
</span>
<span class="sophie-scroll-card__mini-phone" aria-hidden="true">
<svg viewBox="0 0 24 24" focusable="false"><path d="M22 16.92v3a2 2 0 0 1-2.18 2 19.79 19.79 0 0 1-8.63-3.07 19.5 19.5 0 0 1-6-6A19.79 19.79 0 0 1 2.12 4.18 2 2 0 0 1 4.11 2h3a2 2 0 0 1 2 1.72c.12.9.32 1.77.59 2.61a2 2 0 0 1-.45 2.11L8 9.69a16 16 0 0 0 6.31 6.31l1.25-1.25a2 2 0 0 1 2.11-.45c.84.27 1.71.47 2.61.59A2 2 0 0 1 22 16.92Z"/></svg>
</span>
</button>
</aside>
</body>
</html>