
Cloudflare Agent Readiness Score — Sólo el 4% de los sitios están preparados para agentes de inteligencia artificial
Cloudflare Radar analizó 200,000 dominios y encontró sólo 4% declara preferencias de IA. Además: AI Training Redirects enforce canonicals for GPTBot and ClaudeBot, y el punto ciego de citación Reddit de ChatGPT explicó.

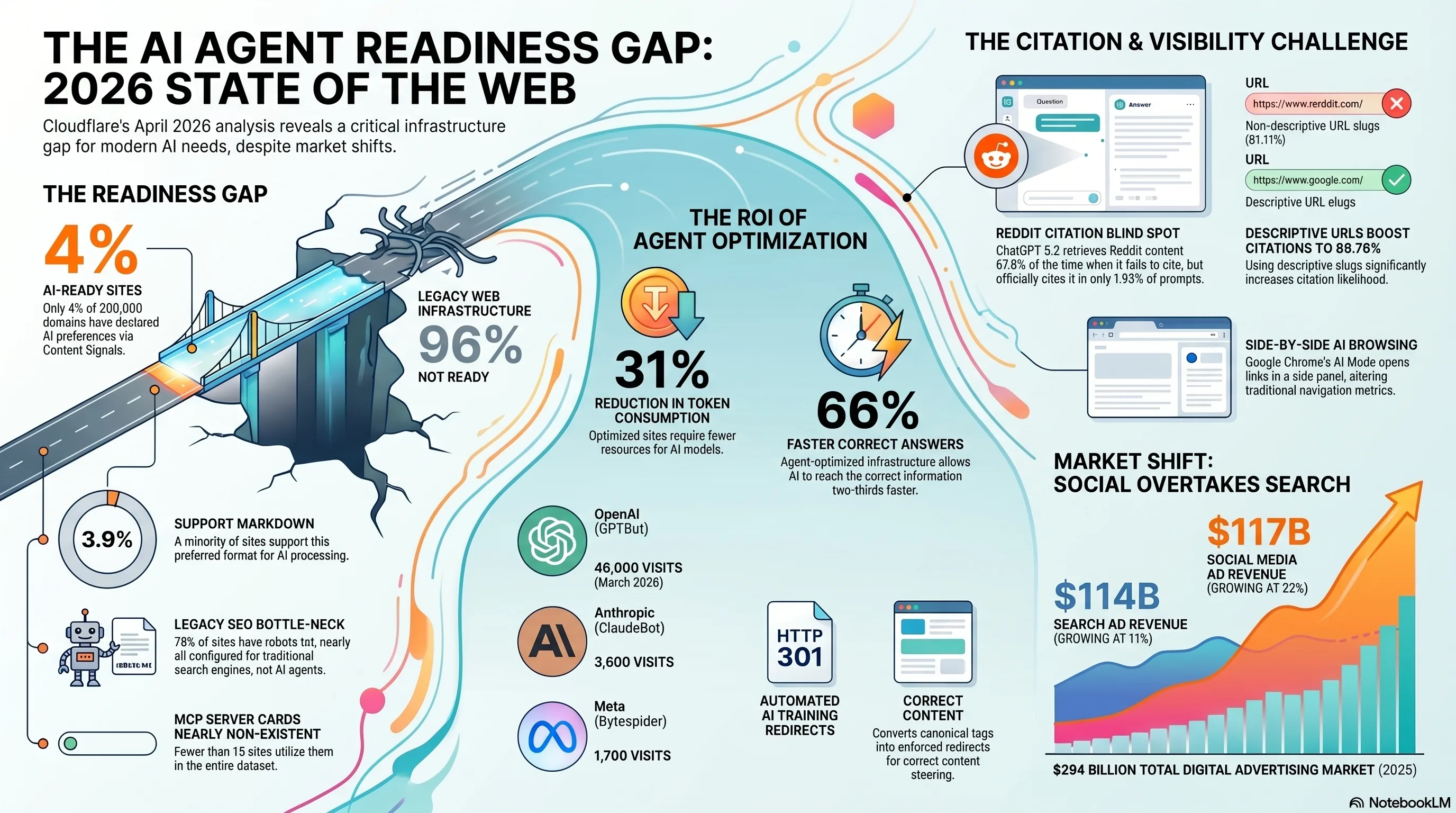
Cloudflare acaba de publicar la primera auditoría a gran escala de cómo está preparada la web para los agentes de IA, y la respuesta es: apenas en absoluto. A través de 200.000 dominios analizados por Cloudflare Radar, sólo 4% han declarado preferencias de IA. Las tarjetas MCP Server existen en menos de 15 sitios. Mientras tanto, las nuevas redirecciones de entrenamiento AI de Cloudflare convierten etiquetas canónicas en redirigidos duros 301 para los rastreadores de IA como GPTBot y ClaudeBot, un cambio fundamental en cómo los editores pueden hacer cumplir la jerarquía de contenidos para tuberías de entrenamiento de LLM. Esto viene junto con nuevos datos sobre el punto ciego de citación Reddit de ChatGPT y el momento histórico cuando las redes sociales publican una búsqueda abrumada.
1. Cloudflare Agent Readiness Score , Sólo 4% de los sitios de 200K Declare AI Preferencias
Cloudflare Radar ha escaneado 200.000 dominios para producir el primer Agent Readiness Score , una métrica compuesta que mide cómo los sitios web preparados son para la interacción con el agente AI. Los resultados están sobrios para cualquiera que aposte la web de agente está a la vuelta de la esquina. La puntuación evalúa cuatro capas de preparación de la IA: si los archivos 'robots.txt` de un sitio se dirigen a los rastreadores de IA, ya sea que exponga 'llms.txt` o `llms-full.txt` para los resúmenes de contenido amigable con LLM, ya sea que declare preferencias de IA estructuradas, y si soporta protocolos de agentes emergentes como MCP Server Cards.
Las cuatro capas de preparación
Capa 1: robots.txt (78% tienen uno, casi ninguna dirección AI). La gran mayoría de los sitios web tienen un archivo 'robots.txt`, pero estos fueron escritos para Googlebot y Bingbot. No incluyen directivas para GPTBot, ClaudeBot, Bytespider u otros rastreadores de entrenamiento de IA. Tener un `robots.txt` es necesario pero no suficiente, sin directivas específicas de AI, usted no tiene una posición declarada sobre el rastreo de IA. Ninguno. Capa 2: llms.txt adopción (cerca de cero). El estándar `llms.txt`, propuesto como el equivalente AI de `robots.txt`, proporciona un resumen legible por máquina del contenido de un sitio sintonizado para el consumo de LLM. La adopción es funcionalmente cero fuera de los sitios de documentación de herramientas del desarrollador. El compañero `llms-full.txt`, que proporciona acceso completo al contenido, es incluso más raro. Capa 3: declaraciones de preferencia AI (4%). Sólo el 4% de los dominios 200K tienen una declaración explícita sobre cómo los sistemas AI deben interactuar con su contenido. Esto incluye directivas 'robots.txt' específicas de AI, etiquetas meta, encabezados HTTP, o datos estructurados que indican políticas de acceso a AI. El otro 96% está operando en un estado predeterminado no regulado, los rastreadores de AI deciden por sí mismos. Capa 4: MCP Server Cards (menos de 15 sitios). La especificación de la tarjeta de servidor del Protocolo Modelo, que permite a los sitios declarar sus capacidades, los puntos finales de API y los esquemas de datos a los agentes de IA, existe en menos de 15 sitios web a nivel mundial. Esta es la capa que permitiría la verdad interacción con los agentes (Reserva, compra, consulta) en lugar de arrastrarse y leer. Apenas existe todavía.Lo que esto significa en la práctica: La red de agentes está siendo construida sobre una fundación donde el 96% de los sitios no han declarado preferencias de IA. Los agentes de IA están haciendo inferencias acerca de las políticas del sitio, las capacidades y el acceso a contenidos basados en señales diseñadas para una época diferente. La brecha entre la promesa del comercio de agentes y la realidad de la preparación web es enorme.
La brecha de preparación de la industria El
4% promedio enmascara una variación significativa entre los sectores:
| Sector | Tasa de declaración de AI | Mecanismo primario |
|---|---|---|
| Herramientas de desarrollo / documentación | ~18% | llms.txt + AI robots.txt directivas |
| Noticias / editores de medios | ~12% | bloques de arrastre AI en robots.txt |
| E-commerce | ~3% | La mayoría robots legados.txt sólo |
| Pequeña empresa / local | <1% | No hay configuración específica de AI |
| Enterprise SaaS | ~8% | Mezclado, algunos llms.txt, algunos bloques |
Key takeaway
La web de agentes requiere que los editores declaren activamente sus políticas y capacidades de IA. El 96% no ha comenzado. Los primeros impulsores que establecen llms.txt, directivas de robots.txt específicas de AI, y declaraciones de capacidad estructurada tendrán una ventaja agravante ya que los agentes de IA viajan cada vez más a través del tráfico basado en estas señales.
2. Sitios optimizados para el agente: 31% de las fichas más bajas, 66% Respuestas más rápidas
El análisis de Cloudflare no paraba de medir la preparación, sino que también cuantificaba la diferencia de rendimiento entre los sitios optimizados por agentes y no optimizados cuando los agentes de IA realmente consumen su contenido.Por qué esto importa para citación y visibilidad La mejora de la precisión de recuperación , 2.4x , es el número más consecuente aquí. Los agentes de IA que sacan de sitios optimizados son considerablemente más propensos a extraer la respuesta correcta y atribuirla adecuadamente. Esto se conecta directamente con el
ChatGPT mecánicos de citación cubrimos antes: el rango de recuperación es la señal dominante para si se cita una página, y las páginas optimizadas para agentes mejoran su posición de recuperación haciendo que su contenido sea más parseable.Sitio no optimizado
- Agente analiza HTML completo incluyendo nav, anuncios, pieers
- Consumo de fichas: ~4,200 por página promedio
- Retrieval accuracy: baseline
- Latencia de la respuesta: base
- Contenido mezclado con caldera en ventana context
Sitio optimizado para agentes
- Agente lee llms.txt o contenido semántico limpio
- Consumo de fichas: ~2,900 por página promedio (31% menos)
- Retrieval accuracy: 2.4x baseline
- Respuesta de latencia: 66% más rápido
- Señal de contenido puro, sin ruido en la ventana contextual
La ventaja agravante: Optimización del agente crea un bucle de retroalimentación positivo. Los sitios optimizados se recuperan con más precisión, lo que mejora las tasas de citación, lo que aumenta el tráfico de agentes, lo que justifica una mayor inversión de optimización. Los sitios que comienzan ahora serán difíciles de desplazar una vez que los patrones de enrutamiento de agente se solidifiquen.
3. Cloudflare AI Training Redirects , Canonical Tags Conviértete en 301 para AI Crawlers
Cloudflare lanzó una nueva característica que cambia cómo los editores pueden hacer cumplir la jerarquía de contenidos para los rastreadores de entrenamiento AI: AI Training Redirects. Convierte sus etiquetas "rel=canónicas" existentes en redirecciones duras 301, pero sólo para los rastreadores de IA identificados.
Cómo funciona Cuando un visitante humano o
Googlebot solicita una URL no canónica, digamos, una versión paginada, una variante del parámetro, o una copia sindicada, reciben una respuesta normal de 200 con una etiqueta 'rel=canical' que apunta a la URL preferida. La etiqueta canónica es una pista. Googlebot puede o no seguirlo, como
Los 9 escenarios de anulación canónica de Mueller show. Cuando GPTBot, ClaudeBot o Bytespider solicita esa misma URL no canónica, Cloudflare intercepta la solicitud al borde y devuelve una 301 redireccion permanente a la URL canónica. El rastreador AI nunca ve el contenido duplicado. Se ve obligado a la versión canónica. Parada completa. Los datos internos de Cloudflare revelan la escala de los sitios de tráfico de rastreadores AI con esta característica activada:| Arrastre de inteligencia artificial | Visitas aproximadas | Organization |
|---|---|---|
| GPTBot | ~46,000 | OpenAI |
| ClaudeBot | ~3,600 | Anthropic |
| Bytespider | ~1,700 | Meta / ByteDance |
Por qué esto importa para SEO La característica resuelve un problema que es frustrado editores desde que los rastreadores de AI se generalizaron:
las etiquetas canónicas son consejos para todos los rastreadores, incluidos los AI. Un oleoducto de entrenamiento de AI que ingiere una variante de URL paginada o parametizada trenes en contenido que no se suponía que viera como una página independiente. Peor aún, puede indexar la versión no canónica como fuente separada, diluyendo la autoridad canónica en los datos de entrenamiento del modelo AI. Con AI Training Redirects, la relación canónica se convierte en un duro redireccion para los rastreadores de AI solamente. Los visitantes humanos y los motores de búsqueda tradicionales siguen recibiendo la respuesta normal. Es un mecanismo quirúrgico que no rompe el SEO existente o la experiencia del usuario.Nota de aplicación: AI Training Redirects es un panel de control Cloudflare, sin necesidad de cambios de código. Lee su existente
rel=canonical
tags y aplica la lógica redireccionable en el borde CDN. Si tus etiquetas canónicas son precisas, habilitar la función es una mejora de un clic. Si tus etiquetas canónicas tienen errores (y muchos), arreglar los primeros , un 301 redireccion a la canónica equivocada es peor que ninguna redireccion en absoluto.
Caveat: Esta característica se dirige actualmente a GPTBot, ClaudeBot y Bytespider basado en cadenas de agentes de usuario. Los rastreadores de IA que no se identifican, o que usan agentes de usuario rotativos, evitarán la redireccion. Es un mecanismo de aplicación para los rastreadores obedientes, no una solución universal. Las visitas ~46K de GPTBot sugieren que OpenAI está jugando por las reglas de identificación; si todos los laboratorios de AI siguen haciéndolo es una pregunta abierta.
Key takeaway
Si está en Cloudflare, active AI Training Redirects hoy, siempre que sus etiquetas canónicas sean exactas. Garantiza que los oleoductos de capacitación de IA solo ingieren sus versiones URL preferidas, evitando que el contenido duplicado de contaminar los datos de entrenamiento de LLM. Para los sitios que no son de Cloudflare, el concepto es replicable con la lógica de los trabajadores del borde en cualquier CDN que apoye el enrutamiento basado en el usuario.
4. ChatGPT Cites Reddit Sólo 1.93% , El estudio de 1.4M-Prompt
Ahrefs analizó 1.4 millones de solicitudes de ChatGPT y encontró una desconexión llamativa: Las páginas de Reddit son recuperadas constantemente por la búsqueda de ChatGPT pero casi nunca citadas en la respuesta final. La tasa de citas es sólo 1.93%. Cubrimos este estudio y sus implicaciones plenas en nuestro análisis de los mecánicos de citas de ChatGPT, pero el hallazgo merece atención aquí por lo que revela sobre la estructura URL y el comportamiento de citación.
La señal de la estructura URL El hallazgo más accionable de los datos Ahrefs es el papel de la estructura URL en las tasas de citación:
Para SEOs: La estructura URL siempre ha importado para la clasificación de Google. Ahora importa la cita de AI también. Si usted está ejecutando un sitio con estructuras permalink limpias y contenido concentrado, ya tiene una ventaja estructural sobre foros, plataformas sociales y sitios con esquemas de URL complejos. Mantén cortos, centrados en palabras clave, y descriptivos, están siendo leídos por máquinas tomando decisiones de citación.
5. IAB 2025: Social Media Ads Overtake Search for the First Time
El informe de la Oficina Interactiva de Publicidad 2025 marca un cruce histórico: los ingresos de la publicidad de las redes sociales (117 mil millones de dólares) han superado la publicidad de búsquedas (14 mil millones de dólares) por primera vez. El gasto total de anuncios digitales de EE.UU. alcanzó $294 mil millones.The budget rebalancing risk: Cuando los CMOs ven titulares de búsqueda "requisitos sociales", la reasignación presupuestaria sigue. Los equipos de SEO deben preparar un caso respaldado por datos para el ROI de la búsqueda orgánica, especialmente porque la búsqueda de AI crea nuevos canales de cita y visibilidad que las redes sociales no pueden reproducir. El Loop de abeto afectando la calidad del contenido social realmente fortalece el caso de contenido de búsqueda orgánica autorizado.
6. Modo de IA de Chrome: Crecimientos de lado a lado
Google está probando una integración de modo AI directamente en Chrome que permite navegación lado a lado , un panel auxiliar de AI que se sienta junto a la ventana del navegador normal. Los usuarios pueden hacer preguntas sobre la página que están viendo, obtener resúmenes, comparar productos a través de pestañas y desencadenar acciones de agente sin salir del sitio actual. Esto es distinto del modo AI existente de Google en los resultados de búsqueda. Chrome AI Mode opera a nivel del navegador, no el nivel de resultados de búsqueda. Significa: - Cada página web se convierte en un contexto AI. El panel AI puede leer y resumir el contenido de la página, extraer puntos de datos y hacer referencias cruzadas con otras pestañas abiertas. - Comparison shopping se automatiza. Abrir tres páginas de producto, pedir Chrome AI para compararlas, obtener una comparación estructurada sin visitar un sitio de revisión. - Las acciones en página se convierten en agentes. La AI puede interactuar potencialmente con elementos de página, rellenar formularios, activar reservas, añadir a la cesta, desenfocar la línea entre la navegación y la terminación de tareas impulsada por el agente. Para SEOs, Chrome AI Mode representa una nueva superficie donde la calidad del contenido impacta directamente el compromiso del usuario. Los sitios con HTML bien estructurado y semánticamente claro producirán mejores resúmenes y comparaciones de IA que los sitios con marcado desordenado. Esto se conecta directamente a los hallazgos de preparación del agente de Cloudflare: las mismas optimizaciones que ayudan a los rastreadores de IA , HTML semántico limpio, datos estructurados, caldera mínima , ayudará a Chrome AI Mode a la superficie de su contenido eficazmente.implicación inmediata: Si Chrome AI Mode se enrolla ampliamente, el problema "zero-click" se expande de los resultados de búsqueda a toda la experiencia de navegación. Los usuarios pueden extraer valor de su página a través del panel AI sin desplazarse, hacer clic o interactuar con sus CTAs. Páginas sintonizadas para la legibilidad de IA, encabezados claros, datos estructurados, respuestas concisas, se realizarán mejor en el panel IA, pero también puede dar a los usuarios menos razón para interactuar con la página en sí. Esta es la misma tensión que AI Overviews, ahora aplicada a cada página en la web.
7. Sintesis estratégica, Acciones inmediatas y de mediano plazo
Los desarrollos de esta semana convergen en un solo tema: la web está siendo re-intermediada por agentes de IA, y los sitios que declaran sus preferencias y sintonizan su contenido para el consumo de máquina primero capturarán la visibilidad desproporcionada.
Acciones inmediatas (esta semana)
| Action | Priority | Effort |
|---|---|---|
| Auditoría tus robots.txt para directivas de rastreadores de IA. Añade reglas explícitas para GPTBot, ClaudeBot, Bytespider y otros rastreadores de AI. Decide: bloquear, permitir o acceder selectivo. | High | 30 min |
| Activar Cloudflare AI Training Redirects (si en Cloudflare). Verifica tus etiquetas canónicas primero son exactas. | High | 15 minutos |
Cree un archivo llms.txt. Comience con un resumen conciso del contenido, propósito y páginas clave de su sitio. Lugar en la raíz: /llms.txt. | Medium | 1 hora |
| Limpiar las estructuras URL. Asegurar que las páginas de aterrizaje clave utilicen slugs cortos, descriptivos, centrados en palabras clave, que se utilizan como señales de calidad de citación por los sistemas AI. | Medium | Variable |
| Revise tráfico de rastreadores AI en registros del servidor. Identifica qué bots AI están arrastrando tu sitio, con qué frecuencia, y qué páginas más golpean. | Medium | 1 hora |
Medidas de mediano plazo (anexo de 30 días)
| Action | Priority | Effort |
|---|---|---|
| Implementar datos estructurados para capacidades de agente. Si su sitio es compatible con transacciones (reserva, compra, programación), declare estos como acciones estructuradas. Este es el precursor de las tarjetas MCP Server. | High | 1-2 días |
| Contenido de tune para la eficiencia de token. Reduzca el HTML de la caldera, mejore el marcado semántico y asegure que el contenido principal sea fácilmente extraíble del cromo de página. | Medium | Ongoing |
| Construya una capa de contenido IA. Para tus 20 páginas superiores, crea versiones concisas, legibles por máquina que sirven agentes AI sin la capa de diseño visual. | Medium | 1 semana |
| Preparar una búsqueda vs. defensa del presupuesto social. Utilice los datos IAB + sus propios datos de rendimiento orgánico para construir el caso para mantener la inversión de búsqueda como tomas sociales en el gasto total de anuncios. | Low | 2 a 3 horas |
| Monitor Chrome AI Mode beta. Si su sitio está en verticales es probable que se vea afectado (comercio electrónico, SaaS, viaje), prueba cómo sus páginas se renderizan en el panel AI de Chrome y sintonice en consecuencia. | Low | Ongoing |
La imagen más grande de
Cloudflare Agent Readiness Score es el primer punto de referencia cuantitativo para un cambio que definirá SEO en los próximos 2-3 años. La web fue construida para los navegadores humanos, luego sintonizada para los rastreadores de búsqueda, y ahora está siendo re-establecido para los agentes de inteligencia artificial. Cada transición ha favorecido a los primeros impulsores , sitios que adoptaron meta tags prematuramente dominado búsqueda temprana, sitios que adoptaron datos estructurados temprano dominado resultados ricos. El patrón repite. El 4% de los sitios que han declarado preferencias de IA hoy refinará su enfoque como estándares maduros. El 96% que no ha comenzado se enfrentará a una desventaja agravante ya que los agentes de IA favorecen cada vez más los sitios que hablan su idioma. Un detalle
evaluación técnica de la SEO es la manera más rápida de identificar lagunas y construir una hoja de ruta.Key takeaway
La preparación del agente AI no es una preocupación futura, es una ventaja competitiva actual. El aumento de la eficiencia del 31% y la mejora de la velocidad del 66% para los sitios optimizados se traducen directamente en mejores tasas de citación y mayor visibilidad en el descubrimiento mediado por AI. Empieza con robots.txt y llms.txt esta semana. Construir hacia declaraciones de capacidad estructuradas en el próximo trimestre.
Preguntas frecuentes
¿Cuál es la puntuación del agente Readiness de Cloudflare?
Cloudflare Agent Readiness Score es una métrica compuesta que mide cómo se prepara un sitio web para la interacción con el agente AI. Evalua cuatro capas: directivas de robots.txt específicas de AI, adopción de archivos llms.txt, declaraciones explícitas de preferencia AI y soporte para protocolos de agente como tarjetas de servidor MCP. Cloudflare Radar escaneado 200,000 dominios y encontrado sólo 4% tiene preferencias de AI declaradas.
¿Qué es llms.txt y debería crear uno?
llms.txt es un archivo estándar propuesto (ubicado en la raíz de su sitio, como robots.txt) que proporciona un resumen legible por máquina del contenido de su sitio sintonizado para el consumo de LLM. Ayuda a los agentes de IA a entender el propósito de su sitio, páginas clave y estructura de contenido sin analizar HTML completo. Creando uno se recomienda , contribuye a la reducción de token del 31% y 66% más rápido generación de respuesta que Cloudflare midió para sitios optimizados para agentes.
¿Cómo funciona Cloudflare AI Training Redirects?
AI Training Redirects convierte tus etiquetas rel=canónicas existentes en redirecciones duras 301, pero sólo para los rastreadores IA identificados (GPTBot, ClaudeBot, Bytespider). Cuando un humano o Googlebot visita una URL no canónica, reciben una respuesta normal de 200 con el indicio canónico. Cuando un rastreador de IA visita la misma URL, Cloudflare devuelve una red de 301 a la versión canónica, asegurando que los conductos de entrenamiento de IA sólo ingieren su contenido preferido. Es un panel de control en Cloudflare, no se requieren cambios de código.
¿Por qué ChatGPT cita Reddit tan rara vez a pesar de recuperarlo constantemente?
El estudio rápido de Ahrefs de 1,4 millones encontró ChatGPT cita las páginas Reddit en sólo 1,93%. Los principales factores son la estructura de URL roscada compleja de Reddit (que marca mal como una señal de calidad de cita), la alta relación de ruido de comentario a firma en la mayoría de los hilos, y la naturaleza generada por el usuario del contenido que hace más difícil para ChatGPT atribuir reclamaciones autorizadas. Las páginas con estructuras URL limpias se citan al 89,78% cuando se recuperan, en comparación con el 81,11% para URLs complejas.
¿La publicidad de redes sociales realmente ha superado la búsqueda?
Sí. El informe de la IAB 2025 muestra los ingresos de publicidad de redes sociales alcanzaron $117 mil millones, superando la publicidad de búsqueda a $114 mil millones por primera vez. El gasto total de anuncios digitales de EE.UU. alcanzó $294 mil millones. La búsqueda no está disminuyendo, creció 11% año tras año. Social simplemente creció más rápido al 16%, impulsado por integraciones de video y comercio de forma corta. Ambos canales se están volviendo a formar simultáneamente por AI.
¿Qué es Chrome AI Mode y cómo difiere de la búsqueda de Google AI?
Chrome AI El modo es un asistente de IA a nivel de navegador que se sienta junto a la ventana de navegación normal, permitiendo la interacción lateral con cualquier página web. A diferencia del modo AI de Google en los resultados de búsqueda (que funciona en el nivel de consultas/results), Chrome AI Mode opera en cualquier página, resumiendo contenido, comparando productos a través de pestañas, y potencialmente desencadenando acciones en página. Amplia el "clic cero" activo de los resultados de búsqueda a toda la experiencia de navegación.
¿Qué debo hacer esta semana para mejorar la preparación del agente AI?
Comience con tres acciones: (1) Auditoría sus robots.txt y añadir directivas explícitas para los rastreadores de IA , GPTBot, ClaudeBot, Bytespider. (2) Si usted está en Cloudflare, active AI Training Redirects después de verificar sus etiquetas canónicas son exactos. (3) Crear un archivo llms.txt en su raíz del sitio con un resumen conciso de su contenido y páginas clave. Estos tres pasos te mueven del 96% sin preferencias de IA al 4% que han comenzado a declararlos.
Sobre el autor
