
Sólo el 4% de los sitios web están listos para agentes de IA: datos de Cloudflare, OAI-AdsBot, y el afeitado Robots.txt (abril 2026)
Cloudflare Agent Readiness Score revela sólo el 4% de los dominios superiores de 200K declaran preferencias de uso de AI. OpenAI añade OAI-AdsBot sin rangos IP publicados, y Google audita directivas robots.txt sin soporte. Esto es lo que los equipos técnicos de SEO necesitan hacer esta semana.

Sólo el 4% de los sitios web están listos para agentes de IA: Cloudflare Data Exposes a Massive Readiness Gap
Cloudflare analizó 200,000 dominios superiores. OpenAI lanzó un nuevo rastreador de validación. Google está repensando la documentación de robots.txt. La relación de la web con los bots AI está siendo reescrita, y la mayoría de los sitios no se mantienen.
Key Takeaways

- Cloudflare Agent Readiness sólo 4% de los principales dominios 200K declaran preferencias de uso AI
- Menos 15 sitios en el conjunto de datos de Cloudflare tienen tarjetas de servidor MCP o catálogos de API
- El nuevo OpenAI OAI-AdsBot gates ChatGPT ad landing pages — pero no tiene rangos IP publicados todavía
- Google utiliza los datos del archivo HTTP para documentar top 10-15 robots sin soporte.txt reglas
- Cloudflare propone credenciales anónimas para reemplazar el modelo binario de detección de bots-vs-humans
- Sitios optimizados para agentes de IA ver 31% menos fichas consumidas and 66% respuestas más rápidas
1. El agente Readiness de Cloudflare Puntuación: Los datos que nadie esperaba

El 17 de abril, Cloudflare presentó el Agente Leeiness Score , una herramienta de diagnóstico que mide cómo se prepara un sitio web para la onda emergente de agentes de IA. A diferencia de las vagas listas de verificación "Listos" de AI, esta puntuación se construye sobre estándares concretos y respaldada por un análisis de 200.000 de los dominios más visitados en Internet.
Los resultados pintan una imagen espeluznante de dónde se encuentra la web.
(más escrito para motores de búsqueda, no AI)
La puntuación evalúa cuatro dimensiones, cada una apuntando a una faceta diferente de interacción de agente:
| Dimension | Lo que chequea | Normas incorporadas |
|---|---|---|
| Discoverability | ¿Pueden los agentes encontrar y entender su estructura del sitio? | robots.txt, sitemap.xml, Link Headers (RFC 8288) |
| Content | ¿Pueden los agentes consumir su contenido de manera eficiente? | Markdown for Agents support |
| Control de acceso de arranque | ¿Ha declarado preferencias por el uso de AI? | Signales de contenido, reglas de bot AI, Web Bot Auth |
| Capabilities | ¿Pueden los agentes tomar acciones o utilizar sus servicios? | Skills, API Catalog (RFC 9727), OAuth discovery, MCP Server Card, WebMCP |
La herramienta de puntuación también produce retroalimentación accionable diseñada para que los agentes de codificación implementen correcciones, lo que significa que puede alimentar su informe de Agent Readiness directamente en Claude, Cursor, o herramientas similares y obtener parches de implementación.
2. Por qué 78% tener robots.txt no significa lo que piensas
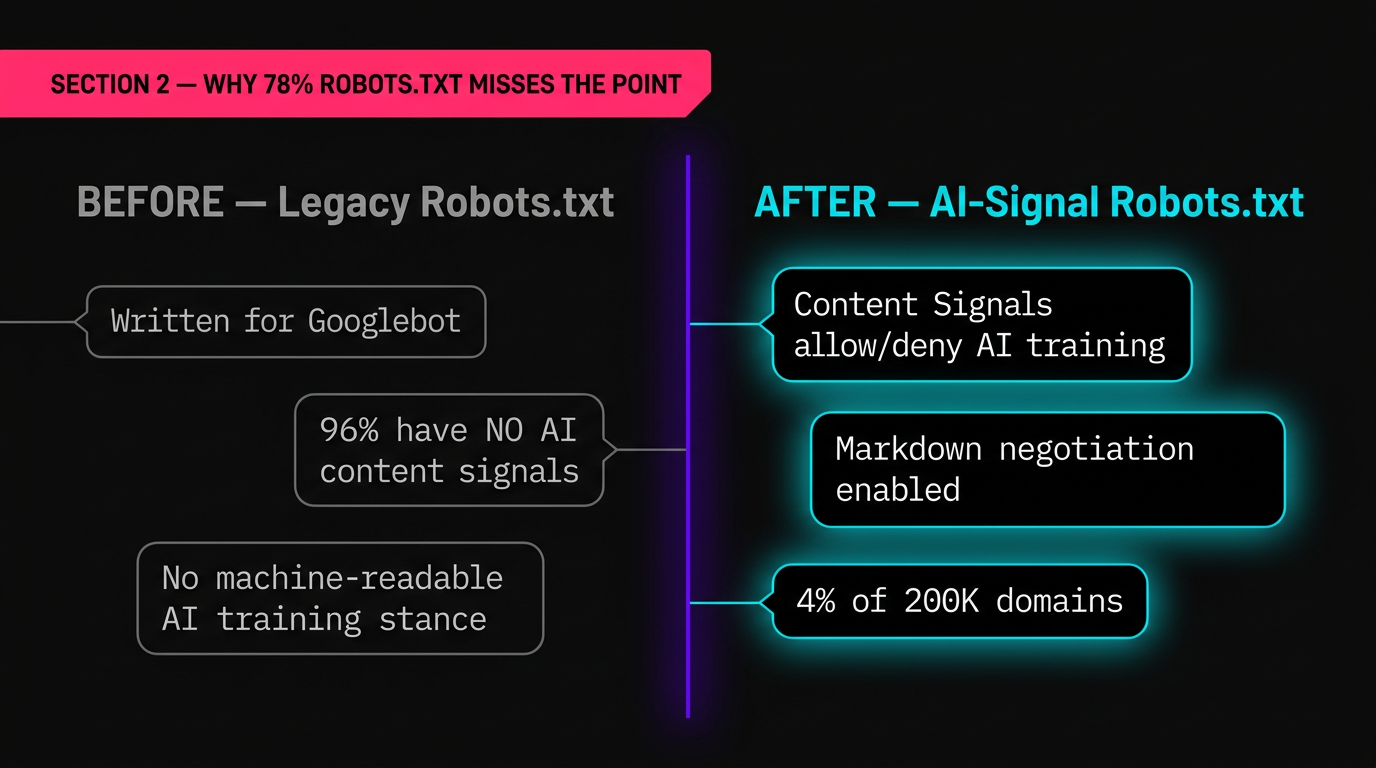
El número de titulares , 78% de los sitios principales tienen robots.txt , suena saludable hasta que examine lo que esos archivos contienen realmente. La gran mayoría fue escrita hace años para Googlebot y Bingbot. No se dirigen a la nueva generación de rastreadores de IA.
La brecha crítica está en Signales de contenido: declaraciones explícitas en robots.txt sobre cómo los sistemas AI pueden utilizar su contenido. Sólo el 4% de los 200.000 dominios analizados incluyen estas señales. Esto significa que el 96% de los principales sitios web no tienen una declaración legible por máquina sobre si los agentes de IA pueden entrenar en su contenido, resumirlo o citarlo.
La Diferencia Práctica
Un robot tradicional.txt normalmente maneja access ¿Puedes arrastrar esta página o no? Content Signals handle usage ¿Qué puedes hacer con el contenido una vez que lo hayas accedido? Esta es la distinción que importa a medida que los agentes de IA se mueven de arrastrarse a acting en contenido web.
# Traditional robots.txt (access only)
User-agent: GPTBot
Disallow: /private/ # With Content Signals (access + usage preferences)
User-agent: GPTBot
Disallow: /private/ # Content Signals
# ai-usage: no-training
# ai-usage: allow-summary
# ai-usage: allow-citation3. OpenAI-AdsBot: Un nuevo Crawler entra en la arena
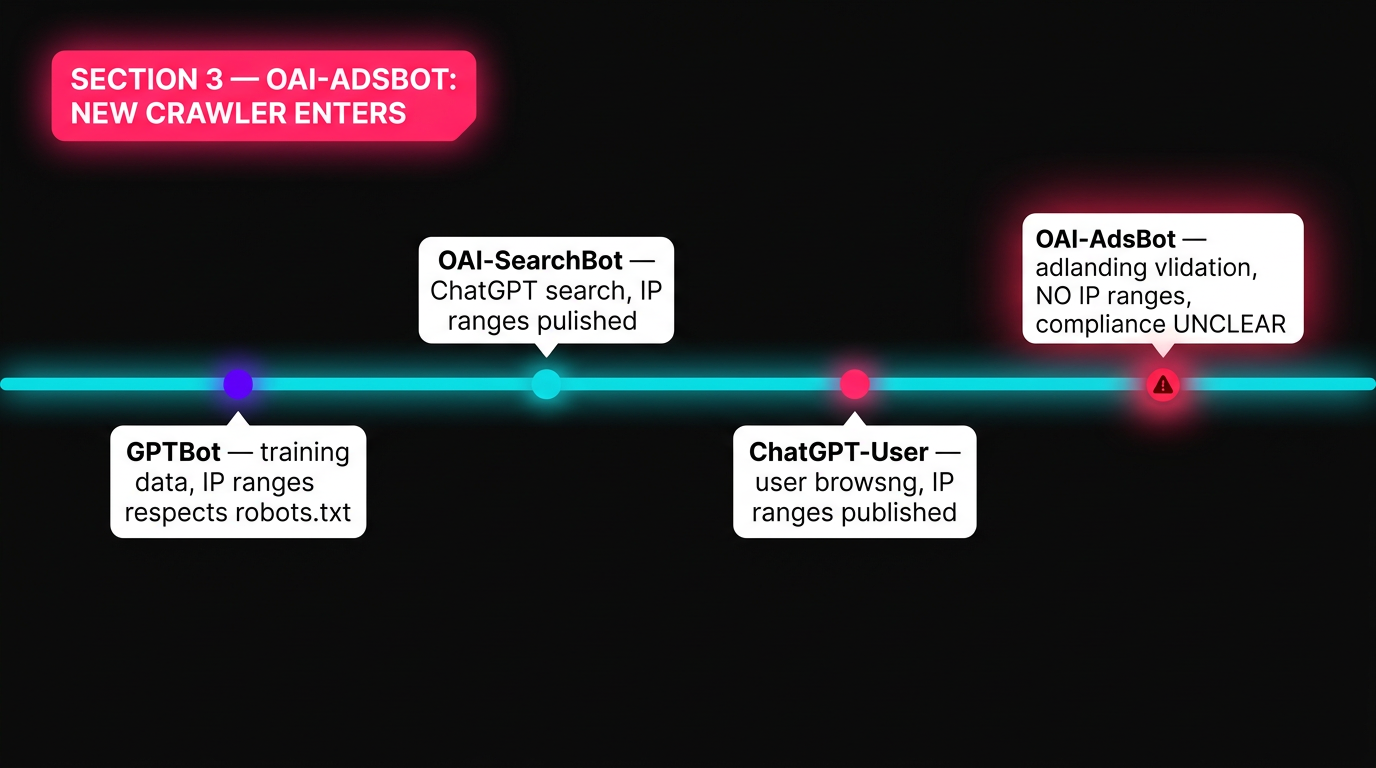
La documentación de OpenAI ahora lista cuatro bots distintos. La nueva adición , OAI-AdsBot , sirve un propósito diferente de los otros. No arrastra la web abierta. valida las páginas de aterrizaje enviadas a través de la plataforma de publicidad de ChatGPT.
| Bot | Purpose | ¿Respeta a robots.txt? | IP Ranges Publicado? |
|---|---|---|---|
| GPTBot | Reunión de datos sobre capacitación | Yes | Sí (.json) |
| OAI-SearchBot | Resultados de búsqueda de ChatGPT | Yes | Sí (.json) |
| ChatGPT-User | Navegación iniciada por el usuario | Yes | Sí (.json) |
| OAI-AdsBot | Validación de la página de aterrizaje | Unclear | No |
OAI-AdsBot realiza dos funciones cuando un anunciante envía una página de aterrizaje:
- Verificación del cumplimiento de las normas , verificar la página cumple con los estándares de publicidad de OpenAI
- Análisis de contenidos , evaluación de la página para determinar el tiempo de anuncio óptimo y la audiencia para usuarios de ChatGPT
Su cadena de usuario es:
Mozilla/5.0 AppleWebKit/537.36 (KHTML, como Gecko); compatible; OAI-AdsBot/1.0Lo que significa para los anunciantes
Si estás ejecutando o planeando campañas de anuncios de ChatGPT, tus páginas de aterrizaje deben ser accesibles a OAI-AdsBot. Configuraciones agresivas de bot-blocking (Cloudflare Bot Management, Akamai Bot Manager, reglas de WAF personalizadas) pueden bloquear inadvertidamente la validación de anuncios, evitando que sus campañas inicien.
OpenAI declara explícitamente que los datos recogidos por OAI-AdsBot son no se utiliza para entrenar modelos de IA generativos , una distinción crítica del uso de datos de GPTBot.
4. Expansión de documentación de Google Robots.txt: ¿Qué está cambiando realmente
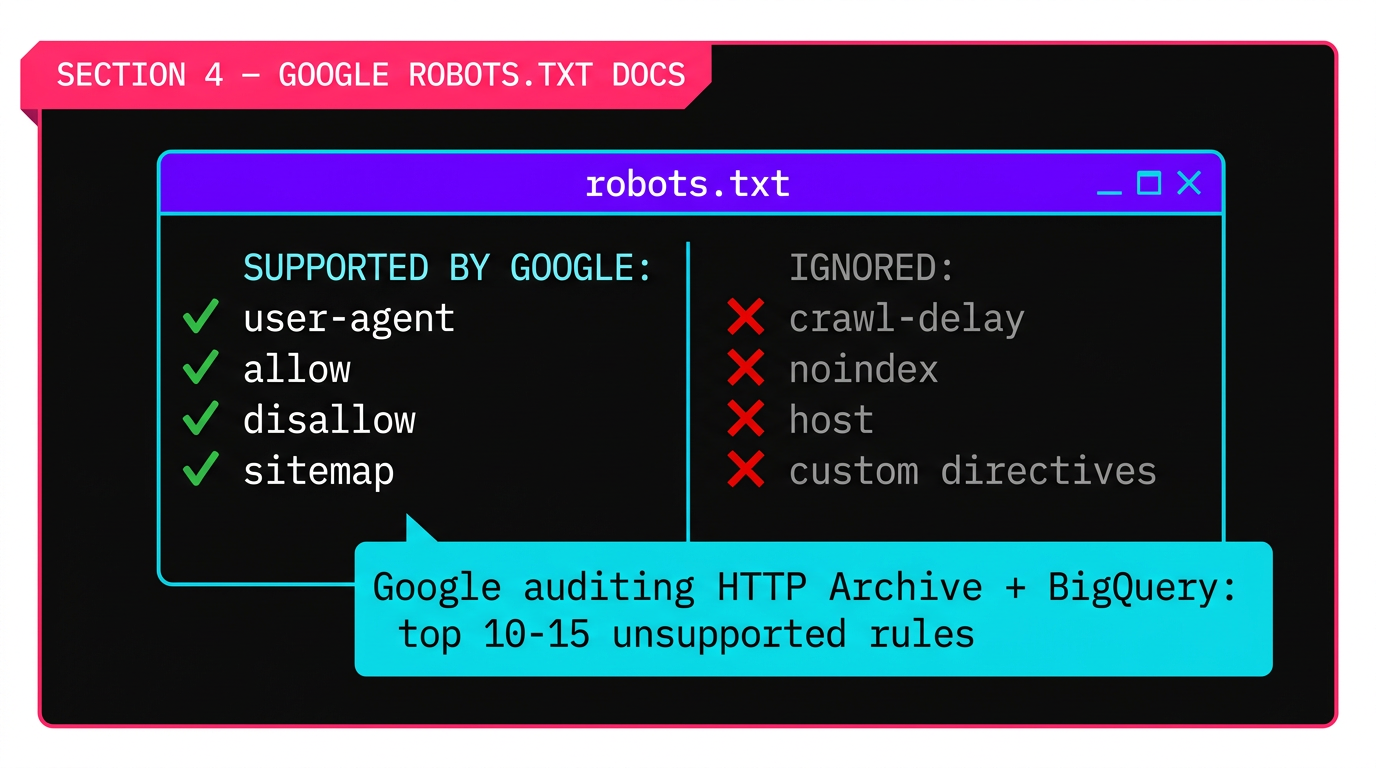
En un desarrollo separado pero relacionado, Google señaló que puede ampliar su documentación de no compatibles robots.txt directivas. Esto es un cambio de documentación, no un cambio de funcionalidad, pero importa más de lo que suena.
Google actualmente soporta exactamente cuatro robots.txt campos:
Todo lo demás, crawl-delay, noindex, host, directivas personalizadas , es ignorado por Google. Pero muchos operadores de sitios no saben eso. La investigación de datos de Google revela la magnitud de la confusión.
La metodología de investigación
En lugar de adivinar qué reglas no compatibles para documentar, Google utilizó Datos del archivo HTTP queried via BigQuery. Construyeron un analizador de JavaScript personalizado para extraer reglas de robots.txt del archivo (las redes estándar no suelen capturar estos archivos). Su hallazgo: "Después de permitir y desactivar y agente de usuario, la gota es extremadamente drástica."
El objetivo es identificar el arriba 10-15 directivas no compatibles más utilizadas y documentar formalmente que Google los ignora. Gary Illyes también indicó que Google puede Ampliar la tolerancia de los tipo , aceptando errores más comunes de las directivas apoyadas , aunque no se dieron detalles ni plazos.
crawl-delay, noindex, host, o cualquier directiva no estándar esperando que Google lo honra, no lo hace. Estas reglas pueden trabajar con otros rastreadores (Bing honors) crawl-delay, por ejemplo) pero nunca han influido en el comportamiento de Googlebot. 5. The Model Shift: From "Bots vs. Humans" to Intent-Based Signals
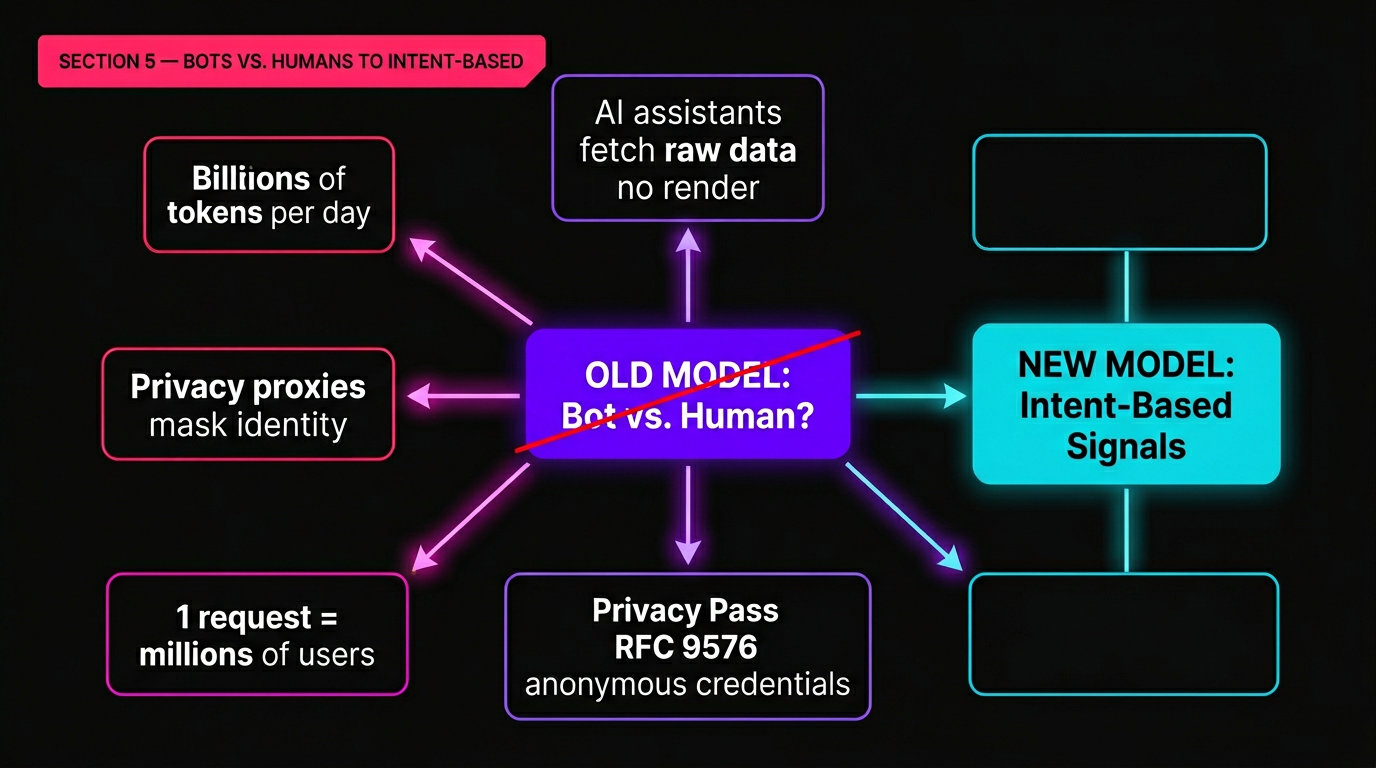
El puesto del 21 de abril de Cloudflare, "Moving past bots vs. humans", sostiene que todo el plan para la gestión de bots es obsoleto. La pregunta binaria , ¿Es esta petición de un bot o un humano? , ya no captura lo que realmente importa.
Los asistentes de IA buscan datos crudos sin hacer páginas. Los proxies de privacidad ocultan la identidad del usuario. La misma solicitud HTTP podría servir un informe privado o formar un modelo en nombre de millones de usuarios. La vieja taxonomía se descompone.
Credenciales anónimas: el reemplazo propuesto
La solución propuesta de Cloudflare se construye sobre Normas de privacidad (RFC 9576, RFC 9578), utilizando primitivos criptográficos (VOPRF y BlindRSA) para crear una nueva capa de confianza. El mecanismo básico:
- Las fichas prueban atributos, no identidad , un cliente puede demostrar "Tengo una buena historia con este servicio" sin revelar "Soy este usuario específico"
- Las fichas son inlinkable , no pueden ser correlacionados en todas las sesiones, evitando el seguimiento
- Ya a escala , Privacy Pass tokens proceso miles de millones por día en la infraestructura de Cloudflare
El límite de tarifas Trilemma
Cloudflare identifica una limitación fundamental en la gestión del bot: descentralización, anonimato y rendición de cuentas, elegir dosLos sistemas actuales generalmente logran los dos primeros mientras sacrifican la rendición de cuentas. Nuevos estándares en relación con el desarrollo del IETF intentan equilibrar los tres:
| Standard | Status | Lo que puede |
|---|---|---|
| Credenciales anónimas de tasa de emisión (ARC) | IETF development | Clientes sin identificarlos |
| Tokens de crédito anónimo (ACT) | IETF development | Acceso medido con preservación de la privacidad |
| Privacy Pass (RFC 9576/9578) | Producción (millones/día) | Probar la terminación del desafío sin cookies |
6. El nuevo sistema AI Bot: un mapa completo
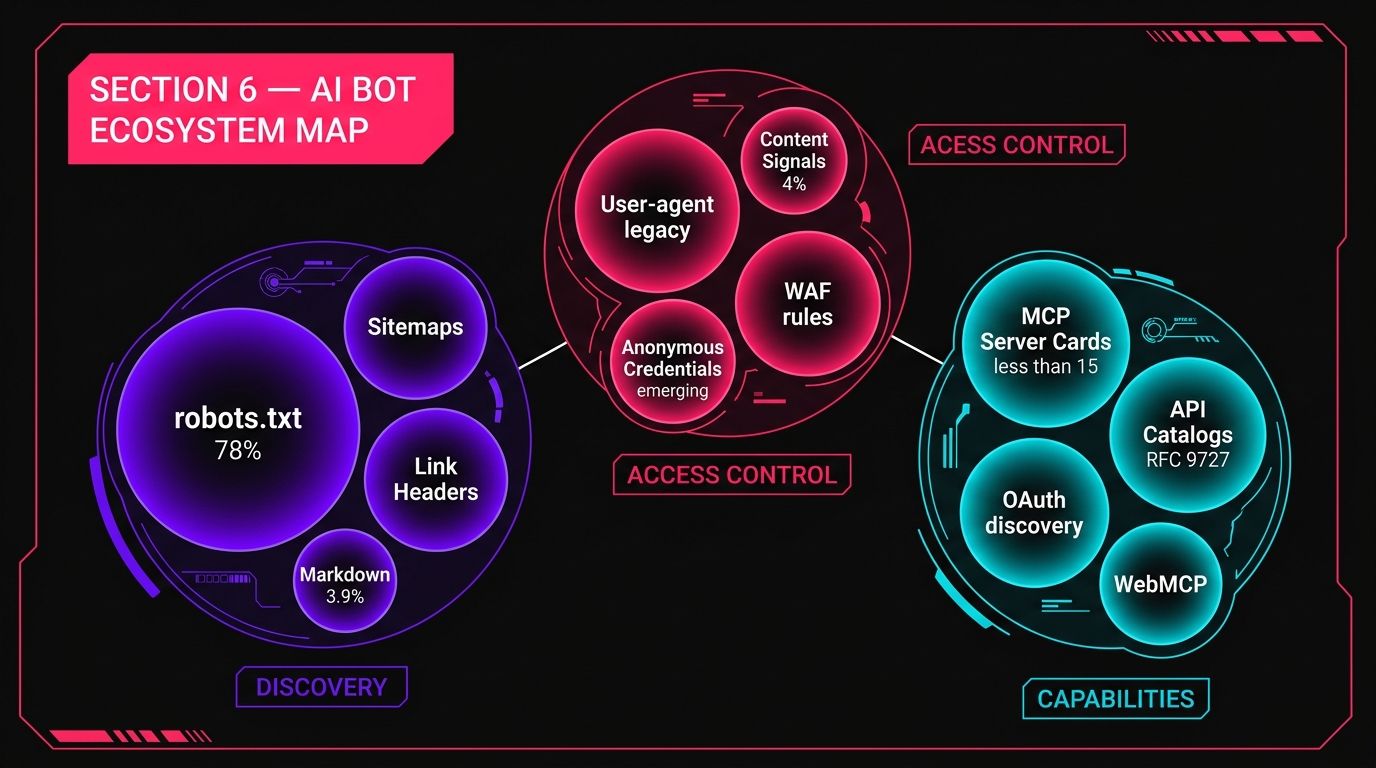
Entre la flota de bots en expansión de OpenAI, los nuevos estándares de Cloudflare y la auditoría de Google robots.txt, estamos viendo la formación de una arquitectura de tres capas para la interacción AI-web:
| Layer | Function | Estado actual |
|---|---|---|
| Discovery | Cómo los agentes encuentran y entienden la estructura del sitio | robots.txt + sitemaps (78% adopción); Link Headers y Markdown (bajo 4%) |
| Control de acceso | ¿Quién puede arrastrar lo que, y lo que pueden hacer con él | Concordancia con el usuario (legado); signos de contenido (4%); credenciales anónimas (emergente) |
| Capabilities | Qué acciones pueden tomar los agentes en su sitio | MCP Server Cards (<15 sitios); catálogos de API (RFC 9727, cerca de cero); WebMCP (experimental) |
Los datos cuentan una historia clara: la capa Discovery es madura pero mal alineada (construida para motores de búsqueda, no agentes de inteligencia artificial). La capa Control de Acceso está experimentando un repensamiento fundamental. La capa de Capacidades apenas existe fuera de un puñado de adoptantes tempranos.
Qué priorizar ahora
No todo necesita acción inmediata. Aquí hay una orden de implementación priorizada basada en los datos:
- Señales de contenido en robots.txt , El esfuerzo más bajo, el mayor impacto. Declare sus preferencias de uso de AI. (Actualmente: 4% adopción)
- negociación de contenidos de marcado , Esfuerzo moderado, pago mensurable. 31% de reducción de token para consumidores de IA. (Actualmente: 3,9%)
- Robots.txt audit , Eliminar las directivas no compatibles que pensabas que estaban trabajando. Toma 15 minutos.
- OAI-AdsBot handling , Si se ejecutan anuncios de ChatGPT, asegúrese de que las páginas de aterrizaje sean accesibles. Revisa las reglas del WAF.
- MCP Server Card / API Catalog , Sólo si usted ofrece servicios estructurados o APIs. El estándar sigue siendo muy temprano. (<15 sitios)
7. What Changes for Technical SEO Teams Esta semana

Estos desarrollos se traducen en tareas concretas para profesionales técnicos de SEO:
Inmediata (Esta semana)
- Ejecute el cheque del agente Readiness en sus dominios superiores. Documenta tu puntuación de referencia.
- Robots de auditoría.txt para directivas no estándar (crawl-delay, noindex, host) que Google nunca ha honrado.
- Chequee los registros del servidor para el tráfico OAI-AdsBot si estás corriendo o considerando anuncios ChatGPT.
- Revisar las reglas de gestión WAF/bot para asegurarse de que no bloquean la validación legítima del bot AI.
A corto plazo (Siguiente 30 días)
- Agregar signos de contenido a robots.txt declarando sus preferencias de uso de AI.
- Implementar la negociación de contenidos de marcación para páginas de contenido de alto valor y documentación.
- Crear un panel de monitoreo de rastreadores AI GPTBot, OAI-SearchBot, ChatGPT-User, OAI-AdsBot, ClaudeBot y otros.
Lista de verificación
- Aprobación de credenciales anónimas , El pase de privacidad de Cloudflare está en vivo, pero ARC y ACT todavía están en desarrollo de IETF.
- Actualización de documentación de Google robots.txt , La lista de directivas no compatibles superior 10-15 no ha sido publicada todavía.
- OAI-AdsBot IP ranges , OpenAI no ha publicado un archivo JSON todavía. Monitoree su documentación de rastreadores para actualizaciones.
Preguntas frecuentes
Es una herramienta diagnóstica que evalúa sitios web a través de cuatro dimensiones: Descubribilidad (robots.txt, mapas de sitios, encabezados de enlace por RFC 8288), Contenido (Apoyo para Agentes), Control de acceso de Bot (Señales de contenido, reglas de bot AI, Auth Web Bot), y Capacidades (Agent Skills, API Catalog via RFC 9727, OAuth discovery, MCP Server Card). La herramienta proporciona una puntuación numérica más cheques individuales de pase/fail, y genera una retroalimentación accionable que los agentes de codificación pueden implementar directamente.
Basado en el análisis de Cloudflare de 200.000 dominios más visitados: sólo el 4% declara preferencias de uso de AI a través de señales de contenido. Mientras que el 78% tiene robots.txt, la mayoría de los archivos fueron escritos para los motores de búsqueda tradicionales. Sólo el 3,9% apoya la negociación de contenidos de marcado. Menos de 15 sitios en todo el conjunto de datos de 200K tienen MCP Server Cards o API Catalogs, la infraestructura necesaria para que los agentes tomen acciones en un sitio.
OAI-AdsBot es el nuevo rastreador de OpenAI para validar páginas de aterrizaje de anuncios de ChatGPT. A diferencia de GPTBot (que arrastra la web abierta para datos de capacitación), OAI-AdsBot sólo visita páginas enviadas como destinos de anuncios. Comproba el cumplimiento de las políticas y analiza el contenido para la asignación de anuncios. Críticamente, los datos recogidos por OAI-AdsBot son not solía entrenar modelos de IA. Sin embargo, actualmente no tiene rangos de IP publicados y no está claro si respeta robots.txt.
Esta es actualmente una brecha en la documentación de OpenAI. Mientras GPTBot y OAI-SearchBot respetan robots.txt, OpenAI no ha especificado si OAI-AdsBot lo hace. No existe ningún archivo JSON de rango IP para verificación. Si ejecuta anuncios ChatGPT, bloquear este bot puede prevenir la validación de anuncios. Los anunciantes deben blanquear el agente del usuario OAI-AdsBot/1.0 en las páginas de aterrizaje de anuncios. Para los no convertidores, monitoree los registros para la cadena de usuario y considere contactar con OpenAI para la documentación de rango IP.
No. Google se está expandiendo documentation, no funcionalidad. Google todavía sólo admite cuatro directivas: user-agent, allow, disallow, y sitemap. El cambio es que Google está utilizando los datos HTTP Archive/BigQuery para identificar los 10-15 más utilizados unsupported directivas y documentarán formalmente que son ignoradas. Gary Illyes también insinuó en la expansión de la tolerancia de la tipo para las directivas apoyadas. Esta es una actualización de claridad, no un cambio técnico.
Las credenciales anónimas son fichas de reserva de privacidad (construidas en Privacy Pass RFC 9576/9578) que permiten a los clientes probar atributos ("tengo buena historia") sin revelar identidad. Cloudflare procesa miles de millones de estos diariamente. Para SEO, esto importa porque podría reemplazar la cadena de usuario-agente que coincida como el método de identificación de bot primario. En lugar de bloquear por nombre bot, los sitios verificarían capacidades y autorización , cambiar la gestión del bot de la identidad a la intención. Nuevos estándares de IETF (ARC, ACT) están extendiendo esto a la limitación de tarifas y acceso medido.
Basado en los datos, priorizar en este orden: (1) Añadir señales de contenido a robots.txt declarando preferencias de uso de AI , sólo 4% de los sitios hacen esto. (2) Implementar la negociación de contenidos de marcado , sitios que lo hacen ver 31% menos fichas consumidas y 66% más rápido respuestas de inteligencia artificial. (3) Robots de auditoría.txt para directivas no estándar (crawl-delay, noindex, host) que Google ignora. (4) Si se ejecutan anuncios de ChatGPT, asegúrese de que las páginas de aterrizaje sean accesibles a OAI-AdsBot. (5) Considere las tarjetas de servidor MCP o los catálogos de API sólo si ofrece servicios estructurados, el sistema es extremadamente temprano (menos de 15 sitios).
Escucha este artículo
NotebookLM audio resumen se añadirá aquí.
Sources
- Cloudflare, "Introduciendo la puntuación del Agente Readiness. ¿Está listo su agente del sitio?" (17 de abril de 2026)
https://blog.cloudflare.com/agent-readiness/ - Cloudflare, "Moving past bots vs. humans" (21 de abril de 2026)
https://blog.cloudflare.com/past-bots-and-humans/ - Search Engine Journal , "OpenAI's Crawler Docs Now List OAI-AdsBot For ChatGPT Ads" (23 de abril de 2026)
https://www.searchenginejournal.com/openais-crawler-docs-now-list-oai-adsbot-for-chatgpt-ads/549980/ - Search Engine Journal , "Google May Expand Unsupported Robots.txt Rules List" (23 de abril de 2026)
https://www.searchenginejournal.com/google-may-expand-unsupported-robots-txt-rules-list/549944/ - Cloudflare , "Construyendo la nube de agentes: todo lo que lanzamos durante la Semana 2026" (20 de abril de 2026)
https://blog.cloudflare.com/agents-week-in-review/
Sobre el autor
 Sobre el autor
Sobre el autor Francisco Leon de Vivero
Francisco es un estratega senior de SEO y vicepresidente de crecimiento en Growing Search, con más de 15 años de experiencia en búsqueda de empresas. Anteriormente sirvió como Jefe de Plan Global SEO en Shopify de 2015 a 2022 y se centra en SEO técnico, estrategia de búsqueda internacional y optimización de plataformas.