
ChatGPT Cites Search Pages at 88.5% While AI Overviews Lose 61% CTR — The Data Behind AI Search's Split Personality ← SEO Pulse — April 27, 2026
El estudio de Ahrefs de las indicaciones de ChatGPT 1.4M revela que las páginas de búsqueda se citan en 88,5% mientras que Reddit se sienta en 1,9%. Mientras tanto, AI Vista general CTR se estrelló 61% y Google

1. 1.4 Millones de propensos: Lo que realmente conduce las citas de ChatGPT
El 15 de abril, Xibeijia Guan publicó el estudio empírico más grande hasta la fecha sobre cómo ChatGPT selecciona qué páginas citar. El conjunto de datos: 1,4 millones ChatGPT 5.2 de escritorio de febrero de 2025, produciendo aproximadamente 23 millones de URL citados y 3 millones de URLs de búsqueda no recitadas. La tasa general de citación en todas las URL recuperadas es casi exactamente 50/50 — 49.98% citado versus 50.02% no citado. Pero ese promedio esconde una jerarquía dramática.
Páginas del índice de búsqueda general , los resultados web estándar que los objetivos tradicionales de SEO , se citan a una tasa de 88.46%. Eso no es un tipo. Casi nueve de cada diez páginas de índice de búsqueda ChatGPT recupera el final citado en la respuesta final. Los artículos de prensa llegan al 12,01%. Reddit, a pesar de ser la fuente única más grande por volumen con más de 16 millones de URL recuperadas, administra sólo 1.93%. YouTube (0,51%) y fuentes académicas (0,40%) redondean el fondo.
| Tipo de fuente | URL recuperadas | Tasa de Citación | Share of All Non-Cited |
|---|---|---|---|
| Búsqueda (web) | 25,563,589 | 88.46% | , |
| News | 3,940,537 | 12.01% | , |
| 16,182,976 | 1.93% | 67.8% | |
| YouTube | 953,693 | 0.51% | , |
| Academia | 185,337 | 0.40% | , |
La implicación es tenue: si quieres que ChatGPT cite tu contenido, la visibilidad tradicional del índice de búsqueda es por lejos el camino más confiable. Ser descubierta a través de la búsqueda web estándar produce una tasa de citas del 88,5%, aproximadamente 46 veces mayor que Reddit y 175 veces superior a YouTube. Las marcas que invierten fuertemente en Reddit SEO o YouTube para la visibilidad de AI están optimizando para el canal equivocado.
2. Fanout Queries: La señal oculta que determina las citas AI

El hallazgo más consecuente del estudio Ahrefs no es sobre tipos de fuentes, es sobre cómo ChatGPT decide internamente qué citar. Cuando un usuario envía un mensaje, ChatGPT no simplemente busca el texto rápido. Genera una serie de sub-preguntas internas llamadas "querías de exploradores", rompiendo el impulso original en ángulos de investigación específicos. El equipo de Guan computed cosine similarity entre estas consultas de fanout y los títulos de página usando modelos de incrustación de código abierto, revelando una brecha significativa entre páginas citadas y no recitadas.
La diferencia entre citado (0.602) y no recitado (0.484) semejanza del título de página al impulso original es sustancial, un 24,4% diferencia. Pero la alineación de la consulta de fanout es aún más fuerte en 0.656, lo que demuestra que las sub-cuestaciones internas de ChatGPT son el verdadero mecanismo de selección. El título de su página no necesita coincidir con lo que el usuario escribió literalmente. Necesita igualar lo que ChatGPT pide internamente sobre el tema.
Slugs URL y frescura: Señales secundarios pero reales
Dos señales adicionales salieron de los datos. Razones de URL de lenguaje natural (por ejemplo, /why-chatgpt-cites-pages/
) obtuvo una tasa de citación del 89,78% frente al 81,11% para las manchas opacas (por ejemplo, /p/12847
) , una ventaja de 8,67 puntos porcentuales. ChatGPT utiliza la estructura URL como una heurística relevante. Parada completa.
La frescura importa, pero no uniformemente. Para el contenido general de la búsqueda, la edad media de las páginas citadas fue de aproximadamente 500 días (~1,3 años), con citas que iban a las páginas tan antiguas como 2.700 días (7,4 años). El contenido establecido y autorizado sigue ganando citas sin ser nuevo. Para el contenido de noticias, el patrón revierte: las noticias citadas tenían una edad mediana de ~200 días contra ~300 días para noticias no recitadas.
Deja de optimizar los títulos de página puramente para la consulta exacta del usuario. En su lugar, piense en qué sub-cuestión generaría una AI al investigar su tema. Una página titulada "How React Server Components Handle State Hydration" superará "React Server Components Guide" porque coincide con una consulta de fanout específica que el modelo genera cuando un usuario pregunta sobre la arquitectura React. La especificidad y la precisión semántica superan la amplitud.
3. La Paradoja Reddit: 16 millones de retenciones, 1.93% Citaciones

La posición de Reddit en los datos exige su propia sección porque desafía una suposición ampliamente sostenida. Desde agosto de 2024 de Google tratar con los datos de entrenamiento de Reddit para AI, y la subida de Reddit en visibilidad orgánica, muchos SEO han tratado la optimización de Reddit como un camino de puerta delantera a citas de AI. Los datos Ahrefs cuentan una historia diferente.
ChatGPT recuperó más de 16 millones de URLs Reddit en todo el período de estudio, más que cualquier otra fuente única. Sin embargo, citó sólo el 1,93% de ellos, y Reddit representó un 67,8% asombroso de todas las URL no recitadas en todo el conjunto de datos. El contenido de Reddit funciona como material de investigación de antecedentes para ChatGPT , contexto que consume durante el razonamiento, pero al final no será superficial para los usuarios.
¿Por qué la brecha? La explicación más probable es el arbitraje de señal de autoridad. Las publicaciones de Reddit carecen de metadatos estructurados, gobernanza editorial y credibilidad institucional que el sistema de citación de ChatGPT parece ponderar. Un hilo Reddit puede proporcionar un contexto anecdótico útil, pero cuando ChatGPT selecciona fuentes para atribuir en una respuesta, gravita hacia páginas que llevan marcadores tradicionales de la autoridad web: estructuras URL limpias, títulos descriptivos, metadatos de publicación y credibilidad tópica a nivel de dominio.
Esto no significa que Reddit sea inútil para SEO, todavía conduce tráfico de referencia directo y puede influir en los rankings de búsqueda tradicionales. Pero como canal para la adquisición de citas de AI, los datos son inequívocos: invertir en su propio contenido índice de búsqueda (el 88,5% de tasa de citación) ofrece aproximadamente 46x el rendimiento de citas de AI del contenido de Reddit (1,93%). Las marcas deben reasignar presupuestos de visibilidad de IA en consecuencia.
4. AI Resúmenes CTR Crashed 61% , Pero la historia completa es más sutil
El 26 de abril, Search Engine Journal informó sobre un estudio interactivo de Seer analizando 5.47 millones de consultas en 53 marcas de septiembre a noviembre de 2025. La conclusión del titular: AI Vista general de la tasa de clics cayó 61% de Q3 a Q4 2025. Pero el desglose mes a mes es más complejo que el titular sugiere.
| Month | Impresiones de visión general de la IA | Clicks | CTR |
|---|---|---|---|
| Septiembre 2025 | 15,8 millones | 398,798 | 2.52% |
| Octubre 2025 | 33,1 millones (+109%) | 400,271 (+0.4%) | 1.21% (-52%) |
| Noviembre 2025 | 39,5 millones (+19%) | 301,783 (-25%) | 0.76% (-37%) |
El CTR de octubre se redujo a la mitad, pero los clics fueron planos (+0,4%). Todo el descenso del CTR en octubre fue impulsado por una explosión del 109% en las impresiones de AI Overview, no un colapso del clic. Google estaba mostrando AI Resúmenes sobre dramáticamente más consultas, que diluyó el CTR matemáticamente sin destruir el volumen de clic absoluto. Como señaló Seer Interactive: "La caída de Octubre fue sobre todo una historia de crecimiento de impresiones, no una historia de colapso de clics".
Noviembre es donde se vuelve genuinamente preocupante. Las impresiones crecieron otro 19% pero los clics realmente cayeron 25%, un declive real y absoluto en el tráfico a los sitios de editor. El CTR alcanzó el 0,76%, lo que significa que menos de 1 de 130 impresiones AI Resumen dio lugar a un clic. Esto se ajusta a lo que han medido múltiples estudios independientes:
El único punto brillante: las páginas realmente citadas dentro de AI Resúmenes reciben 120% más clics por impresión que las páginas no recitadas en el mismo SERP. Ser citado en la Reseña de la AI no sólo preserva su tráfico, lo amplifica en relación con competidores no recitados. Sin embargo, incluso las páginas citadas rezagadas detrás de las mismas páginas en SERPs sin AI Resúmenes alrededor del 38%.
El descenso del 61% CTR es real, pero es un compuesto de dos fenómenos diferentes: la dilución de la impresión (Google mostrando AIOs en más consultas) y la supresión del clic genuino (los usuarios obtienen respuestas sin hacer clic). Para los profesionales, la distinción importa. La dilución de la impresion significa que su contenido aparece en más contextos de AI Vista general, que es en realidad una oportunidad si usted sintoniza para la cita de AIO. Hacer clic en la supresión de las consultas de información puede ser permanente, lo que significa cambiar hacia el contenido de transacción y navegación donde los clics siguen siendo esenciales.
5. Google "Bounce Clicks" Defensa: Tres Apariencias, Datos Cero

El 23 de abril de 2026, el VP de Google de Búsqueda Liz Reid le dijo a Bloomberg que AI Resúmenes reducen principalmente "clices de rebote" , visitas donde los usuarios vuelven rápidamente a buscar sin contenido atractivo. Reid caracterizó esto como la eliminación de tráfico de baja calidad en lugar de eliminar visitas genuinas, afirmando que los usuarios que buscan más lee todavía haga clic a través de los editores.
Esta es la tercera vez que Google ha desplegado esta historia. En un blog de agosto de 2025, Google reclamó volumen de clic orgánico de Search fue "relatively estable" año tras año y que "clics de calidad" había aumentado. En una entrevista de Wall Street Journal de octubre de 2025, Reid usó explícitamente la frase "clic superior" y afirmó que los ingresos ad con AI Resúmenes permanecieron "relatively estable".
En todas las tres apariciones, Google ha proporcionado cero datos de soporte: sin gráficos, sin porcentajes, sin comparaciones de año a año, sin metodología para distinguir los clics de rebote de los clics totales, y sin acceso a datos que permitan la verificación independiente. Tres veces. Nada.
Qué datos independientes realmente muestra
| Source | Dataset | Finding |
|---|---|---|
| Chartbeat / Reuters Institute (2026) | 2.500+ editores a nivel mundial | Google búsqueda referencia tráfico ~33%; Descubre referencias abajo 21% YoY |
| Interactivo de vidente (Q3-Q4 2025) | 5.47M consultas, 53 marcas | CTR orgánico en consultas AIO 61% |
| Pew Research | 68.000 consultas | 8% click rate con AIOs vs 15% sin |
| Contenido digital Siguiente (2025) | 19 editores, mayo-junio | Mediana 10% YoY Google referencia disminución |
| Ahrefs (2026) | 146 millones de resultados | 20.5% AI Información general frecuencia de activación en todas las consultas |
El hallazgo del Instituto Chartbeat/Reuters es especialmente dañino a la historia de Google. Un 33% declinación en el tráfico de referencia de búsqueda a través de 2.500+ editores no es un fenómeno de "clic superior", es una reducción fundamental en el tráfico que llega a los sitios editores. Si Google era correcto que sólo se eliminaran los rebotes de baja calidad, las métricas de compromiso en el tráfico restante deberían haber mejorado proporcionalmente. Ningún conjunto de datos de editor ha mostrado ese patrón.
La afirmación de "clices de rebote" de Google puede contener un núcleo de verdad, algunas respuestas de AI Resúmenes satisfacen trivialmente consultas informativas que habrían generado rebote rápido. Pero la magnitud de la evidencia independiente muestra que el tráfico disminuye mucho más que lo que podría explicar la "extracción de rebote". Hasta que Google publique datos verificables que distingan clics falsos de visitas comprometidas, esta historia debe ser tratada como posicionamiento corporativo, no hallazgo empírico. El 33% del tráfico de editores y 21% Descubra gota medida por Chartbeat no rebotan los clics que desaparecen.
6. Sólo el 4% de la Web está listo para IA-Agent (Datos de Cloudflare)

Mientras que la industria SEO debate las tasas de clic a través, un problema estructural se está construyendo bajo la superficie. El 17 de abril, Cloudflare publicó su Agent Readiness Score, un plan para medir lo bien que los sitios web apoyan a los agentes de inteligencia artificial, junto con datos de 200.000 de los dominios más visitados. Los resultados muestran una enorme brecha de infraestructura entre dónde está la web y dónde debe estar.
The Agent Readiness Score evalúa cuatro dimensiones: Discoverability (robots.txt, sitemaps, HTTP Link headers), Content (Apoyo de marcado para los agentes), Control de acceso de arranque (Directrices específicas de la AI utilizando Signals de Contenido) y Capabilities (MCP Server Cards, catálogos de API, OAuth discovery, índices de habilidad de agente). Mientras que el 78% de los sitios tienen un archivo robots.txt, "la gran mayoría están escritos para los rastreadores tradicionales del motor de búsqueda, no agentes de inteligencia artificial", según el análisis de Cloudflare. Un robots.txt de 2019 no es infraestructura de IA. Es sólo un archivo.
El rendimiento Gap es medible
Cloudflare valoró su propia documentación, que optimizaba para la legibilidad de los agentes de IA, contra sitios no optimizados. Los resultados fueron sorprendentes: 31% menos fichas consumidas en promedio, y 66% más rápido finalización de las consultas técnicas cuando un agente de IA (Kimi-k2.5 via OpenCode) respondió preguntas muy específicas. Los ahorros de token solo se traducen en la reducción de costes reales para cualquier sistema AI que procesa su contenido a escala.
Las técnicas de optimización incluyen servir cada página en una /index.md camino para el acceso directo a la marcación, creando llms.txt archivos que proporcionan listas de lectura estructuradas para LLMs, eliminando aproximadamente 450 páginas de lista de directorios que proporcionaron "valor semántico pequeño", e incorporando directivas de agentes ocultos en páginas HTML que instruyen sistemas AI para solicitar versiones de marcado en su lugar.
AI Crawler Redirect Data
Una característica de Cloudflare compañera, redirecciona para la formación de IA, reveló datos concretos sobre el comportamiento de los rastreadores de IA. En la propia documentación para desarrolladores de Cloudflare, los rastreadores de AI accedieron a páginas 4.8 millones de veces más de 30 días. Sólo la documentación de Legacy recibió 46.000 arrastres de OpenAI, 3.600 de Antrópico, y 1.700 de Meta en marzo de 2026. Estos rastreadores estaban accediendo al contenido deprecado a pesar de las etiquetas canónicas, las directivas noindex y los banners de deprecación, ninguno de los cuales AI entrenamiento los rastreadores respetan.
La solución de Cloudflare convierte ya existente <link rel="canonical"> tags into HTTP 301 reddirects for verified AI training gateers. En los primeros siete días después del despliegue, el 100% de las solicitudes de arrastre de entrenamiento de IA a páginas con etiquetas canónicas no autoreferencias fueron redirigidas con éxito lejos del contenido deprecatado.
Si ChatGPT cita páginas de índice de búsqueda al 88,5%, y los rastreadores de IA están ingiriendo 4,8 millones de páginas al mes de un solo sitio de documentación, entonces la calidad de lo que esos rastreadores encuentran forma directamente si su contenido se cita. El 96% de los sitios web que no han declarado preferencias de IA o formatos de contenido legibles por agentes implementados están dejando los resultados de la citación de IA al azar. Los datos de Cloudflare hacen concreto los elementos de acción: implementar llms.txt, servir alternativas de marcado, añadir directivas Content Signal, y redirigir a los rastreadores AI lejos de páginas deprecatadas.
7. The Practitioner's Playbook: Optimizing for Both AI Surfaces
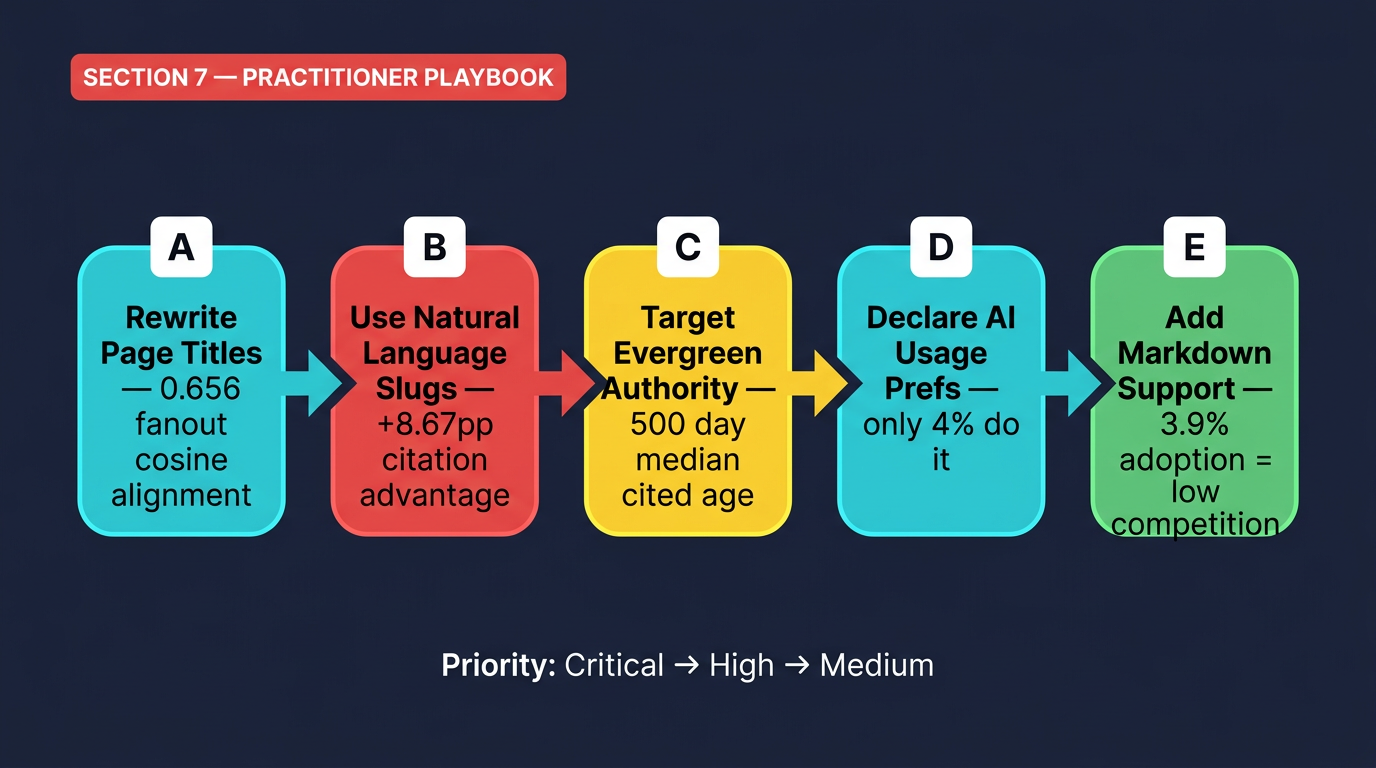
Los datos de esta semana cuentan una historia coherente: ganar citas de AI es altamente factible si sintonizas las señales correctas, y la barra competitiva sigue siendo notablemente baja. Aquí hay un plan de acción priorizado construido a partir de la investigación.
Para la optimización de la Citación de ChatGPT
| Action | Apoyo a los datos | Priority |
|---|---|---|
| Reescribir títulos de página para la precisión semántica , igualar las sub-cuestaciones que una AI generaría, no sólo la consulta de superficie del usuario | 0.656 semejanza cosina para alineación de la consulta de fanout vs. 0.484 para no recitado | Critical |
| Use slugs de URL de lenguaje natural (carriles descriptivos y legibles) | 89,78% de la tasa de citas frente al 81,11% de las manchas opacas | High |
| Centrarse en la visibilidad del índice de búsqueda sobre Reddit/YouTube/presencia social | 88.5% tasa de citación para la búsqueda vs. 1.93% para Reddit | Critical |
| Para el contenido siempreverde, priorice la profundidad sobre la frescura | Mediana citada edad de página: 500 días; más antigua citada páginas: 2.700+ días | Medium |
| Para el contenido de noticias, publicar y actualizar dentro de la ventana de frescura de 200 días | Edad mediana de noticias citada: 200 días vs. 300 para no recitar | Medium |
Para la supervivencia de la IA
| Action | Apoyo a los datos | Priority |
|---|---|---|
| Pursue AIO citation , páginas citadas obtienen 120% más clics que páginas no recitadas en el mismo SERP | Seer Interactive: citado vs. uncited click differential | Critical |
| Cambio de contenido informativo hacia la intención media-funnel/transaccional donde AI Resúmenes suprimen menos clics | El descenso del 61% del CTR se concentró en consultas informativas | High |
| Monitoreo de tendencias CTR orgánicas mensualmente, el 2026 de febrero rebote a 2,4% sugiere que CTR no es permanente en 0,76% | Datos de las vigas: CTR recuperado del 1,3% (Dec) al 2,4% (Feb) | Medium |
| Construir canales de tráfico directos (email, social, comunitario) como cobertura contra la caída de referencia de búsqueda | Chartbeat: 33% declinación del tráfico de editores; Descubre 21% | High |
Para la infraestructura de inteligencia artificial
| Action | Apoyo a los datos | Priority |
|---|---|---|
Crear un llms.txt archivo en la raíz del sitio con jerarquía de contenido estructurada | Sólo el 4% de los sitios han declarado preferencias de IA, oportunidad masiva de primera escala | High |
Servir alternativas de marcado en /index.md caminos o vía el encabezado Aceptar | 3.9% de adopción; 31% de reducción de token + 66% más rápido de terminación de consultas AI | Medium |
| Agregar las directivas de signos de contenido para las preferencias de entrenamiento/input | 4% adopción en los dominios superiores 200K | Medium |
| Redirigir a los rastreadores de IA lejos de contenido deprecated/legacy usando 301s basados en canónica | Cloudflare: 46K GPTBot se arrastra en páginas heredadas en un mes | High |
Preguntas frecuentes
¿Qué porcentaje de los resultados de búsqueda de ChatGPT se citan en las respuestas?
Según un estudio de Ahrefs de 1,4 millones de solicitudes de ChatGPT, las páginas del índice de búsqueda general se citan a una tasa de 88,46%. Pero esto varía drásticamente por tipo fuente: los artículos de noticias se citan en 12,01%, Reddit posts en tan solo 1,93%, YouTube en 0,51%, y fuentes académicas en 0,40%. La tasa general de citación en todas las URL recuperadas es de aproximadamente un 50%, aunque este promedio está fuertemente marcado por el volumen masivo de retrievales incitados de Reddit.
¿Cuánto han bajado las tasas de clics de AI Overview a finales de 2025?
AI Overview CTR cayó 61% de Q3 a Q4 2025, según un estudio interactivo de Seer de 5.47 millones de consultas en 53 marcas. CTR cayó del 2,52% en septiembre al 0,76% en noviembre de 2025. Gran parte de este descenso fue impulsado por una explosión del 150% en las impresiones de AI Vista general en lugar de un colapso proporcional en los clics , el volumen de clic de octubre fue realmente plano en comparación con septiembre a pesar de la halving CTR.
¿Cuál es la señal más fuerte para ser citado por ChatGPT?
La alineación semántica entre el título de su página y las "carteras" internas de ChatGPT es la señal de cita más fuerte. ChatGPT genera sub-cuestiones al procesar un prompt, y la similitud cosine entre estas consultas de fanout y citados títulos de página promedio 0,56, en comparación con 0,484 para páginas no recitadas. Optimizar para las sub-cuestaciones específicas ChatGPT genera, no sólo el impulso de usuario de nivel superficial, es la estrategia más impactante para ganar citas de IA.
¿Cuáles son los "clices de rebote" de Google y es la explicación creíble?
Liz Reid de Google caracterizó los clics eliminados como "clices de rebote" , visitas donde los usuarios rápidamente vuelven a buscar sin contenido atractivo. Afirma que AI Resúmenes reducen principalmente estas visitas de baja calidad preservando un compromiso más profundo. Pero a través de tres apariciones públicas (agosto 2025, octubre 2025, abril 2026), Google ha proporcionado cero datos de apoyo: no hay gráficos, porcentajes o comparaciones año tras año. Investigación independiente de Chartbeat/Reuters Institute muestra una caída del 33% en el tráfico de búsqueda de Google editor y una disminución del 21% en Discover derivaciones, contradiciendo la historia de "sólo clics falsos".
¿Cuál es el puntaje del agente Readiness de Cloudflare y qué mide?
Cloudflare Agent Readiness Score evalúa lo bien que los sitios web soportan los agentes de IA en cuatro dimensiones: Descubribilidad (robots.txt, mapas de sitios, encabezados Link), Contenido (apoyo de marcado para los agentes), Control de acceso de Bot (directrices específicas de IA, Auth Web Bot), y Capacidades (MCP Server Cards, catálogos de API, OAuth discovery). Análisis de 200.000 dominios principales encontró que mientras que el 78% tiene un robots.txt, sólo el 4% declaró preferencias de uso de IA, negociación de contenido de marcado de soporte del 3,9%, y menos de 15 sitios en todo el conjunto de datos tenían tarjetas de servidor MCP o catálogos de API.
¿Por qué Reddit tiene una tasa de citación tan baja de ChatGPT a pesar de ser recuperado con frecuencia?
Reddit cuenta con más de 16 millones de URL recuperadas en el conjunto de datos de Ahrefs, la fuente única más grande, pero se cita sólo 1.93% del tiempo, lo que lo hace 67.8% de todas las URL no recitadas. ChatGPT recupera los puestos de Reddit como contexto complementario durante su fase de investigación, pero al final prefiere citar fuentes más autorizadas y estructuradas al generar respuestas. El contenido de Reddit funciona como material de investigación de antecedentes en lugar de autoridad citable, que tiene implicaciones significativas para las marcas que invierten en estrategias de Reddit SEO.
¿Cómo afecta la edad de la página a la probabilidad de citación de ChatGPT?
Para el contenido general de búsqueda, la edad media de las páginas citadas es de aproximadamente 500 días (unos 1,3 años), con algunas páginas citadas más de 2.700 días (7,4 años). El contenido establecido y autorizado sigue ganando citas incluso sin ser fresco. Para el contenido de noticias, la frescura importa mucho más: los artículos citados tienen una mediana edad de unos 200 días contra 300 días para noticias no recitadas. El contenido Evergreen debe priorizar la profundidad y la autoridad sobre el recreo; el contenido de las noticias debe mantenerse actualizado para permanecer citable.
Sources
- Ahrefs , Por qué ChatGPT Cites Una página sobre otra (Estudio de 1.4M Prompts) , 15 de abril, 2026
- Search Engine Journal , AI Overview CTR Fell 61%, pero los clics no se desplomaron , 26 de abril, 2026
- Search Engine Journal , Google Pushes "Bounce Clicks" Explicación para AI Vista general Pérdida de tráfico , 25 de abril, 2026
- Cloudflare , Introducción de la puntuación del agente Readiness , 17 de abril, 2026
- Cloudflare , Redirects for AI Training Enforces Canonical Content , 17 de abril, 2026
- Cloudflare, Moving Past Bots vs. Humans , 21 de abril de 2026
Sobre el autor
 Sobre el autor
Sobre el autor Francisco Leon de Vivero
Francisco es un estratega senior de SEO y vicepresidente de crecimiento en Growing Search, con más de 15 años de experiencia en búsqueda de empresas. Anteriormente sirvió como Jefe de Plan Global SEO en Shopify de 2015 a 2022 y se centra en SEO técnico, estrategia de búsqueda internacional y optimización de plataformas.